shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]就是读取矩阵的长度。它的输入参数可以使一个整数表示维度,也可以是一个矩阵。

使用shape需要导入numpy
tile函数位于python模块 numpy.lib.shape_base中,他的功能是重复某个数组。比如tile(A,n),功能是将数组A重复n次,构成一个新的数组

使用shape需要导入numpy
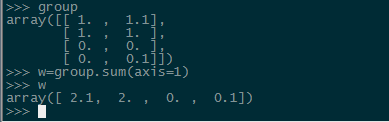
xxx.sum(axis=1);对矩阵的每一个向量相加求和
矩阵排序算法 code(numpy)
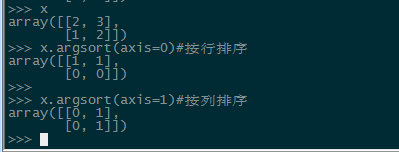
argsort函数返回的是数组值从小到大的索引值
x = np.array([3, 1, 2])
np.argsort(x)
array([1, 2, 0])
按行排序/按列排序(输出为索引的排序)
假设字典Dictionary={'A' : 1, 'B' : 2}
dic.setdefault('key','No Found') 如果在字典中查不到key 则会新建key 值为No Found Dictionary.setdefault('C',0) 执行结果为Dictionary={'A' : 1, 'B' : 2 ,'C' : 0}
Dictionary.get('key','No Found') 如果在字典中查不到key 则会输出 No Found Dictionary.get('C',0) 执行结果为:0
sorted(): sorted(对象,排序元素,正序/逆序) sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) classCount:字典{'A' : 1, 'B' : 2 ,'C' : 0},key=operator.itemgetter(1):对值进行排序,reverse=True:逆序输出3,2,1
计算两点间距离
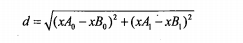
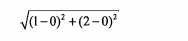 可以将其推广到n维
可以将其推广到n维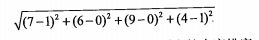
最终 K-近邻算法 为 :
1 def classify0(inX, dataSet, labels, k): 2 dataSetSize = dataSet.shape[0] #shape[0]就是读取矩阵的长度 3 diffMat = tile(inX, (dataSetSize,1)) - dataSet 4 sqDiffMat = diffMat**2 5 sqDistances = sqDiffMat.sum(axis=1) 6 distances = sqDistances**0.5 7 sortedDistIndicies = distances.argsort() 8 classCount={} 9 for i in range(k): 10 voteIlabel = labels[sortedDistIndicies[i]] 11 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 12 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) 13 return sortedClassCount[0][0]
最终返回 值最大的一类(A/B/C).
案例分析:
1 def createDataSet(): 2 group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) 3 labels = ['A','A','B','B'] 4 return group, labels
classify0([0,0],group,labels,3)
输出结果为B
文本解析成矩阵
1 def file2matrix(filename): 2 fr = open(filename) 3 f_lines = fr.readlines() 4 numberOfLines = len(f_lines) #get the number of lines in the file 得到文件的行数 7 returnMat = zeros((numberOfLines,3)) #prepare matrix to return 创建以0填充的矩阵numpy,为了简化处理,将该矩阵的另一维度设置为固定值3,可以根据自己的需求增加相应的代码以适应变化的输入值 8 classLabelVector = [] #prepare labels return 9 #fr = open(filename) 10 11 index = 0 12 for line in f_lines: #循环处理文件中的每行数据,首先使用line.strip截取掉所有的回车字符,然后使用tab字符 将上一步得到的整行数据分割成一个元素列表 13 line = line.strip() 14 15 listFromLine = line.split(' ') 16 17 returnMat[index,:] = listFromLine[0:3] #选取前3个元素,将其存储到特征矩阵中 18 classLabelVector.append(listFromLine[-1]) #Python语言可以使用索引值-1表示列表中的最后一列元素,利用这种负索引,可以将列表的最后一列存储到向量classLabelVector中。注意:必须明确的通知解释器,告诉它列表中存储的元素值为整形,否则Python语言会将这些元素当做字符串来处理 listFromLine前不能加int否则报错 19 index += 1 20 return returnMat,classLabelVector
文本部分数据
1 40920 8.326976 0.953952 largeDoses 2 14488 7.153469 1.673904 smallDoses 3 26052 1.441871 0.805124 didntLike 4 75136 13.147394 0.428964 didntLike 5 38344 1.669788 0.134296 didntLike 6 72993 10.141740 1.032955 didntLike 7 35948 6.830792 1.213192 largeDoses 8 42666 13.276369 0.543880 largeDoses 9 67497 8.631577 0.749278 didntLike 10 35483 12.273169 1.508053 largeDoses 11 50242 3.723498 0.831917 didntLike 12 63275 8.385879 1.669485 didntLike 13 5569 4.875435 0.728658 smallDoses 14 51052 4.680098 0.625224 didntLike 15 77372 15.299570 0.331351 didntLike 16 43673 1.889461 0.191283 didntLike 17 61364 7.516754 1.269164 didntLike 18 69673 14.239195 0.261333 didntLike 19 15669 0.000000 1.250185 smallDoses 20 28488 10.528555 1.304844 largeDoses 21 6487 3.540265 0.822483 smallDoses 22 37708 2.991551 0.833920 didntLike
1 40920 8.326976 0.953952 3 2 14488 7.153469 1.673904 2 3 26052 1.441871 0.805124 1 4 75136 13.147394 0.428964 1 5 38344 1.669788 0.134296 1 6 72993 10.141740 1.032955 1 7 35948 6.830792 1.213192 3 8 42666 13.276369 0.543880 3 9 67497 8.631577 0.749278 1 10 35483 12.273169 1.508053 3 11 50242 3.723498 0.831917 1 12 63275 8.385879 1.669485 1 13 5569 4.875435 0.728658 2 14 51052 4.680098 0.625224 1 15 77372 15.299570 0.331351 1 16 43673 1.889461 0.191283 1 17 61364 7.516754 1.269164 1 18 69673 14.239195 0.261333 1 19 15669 0.000000 1.250185 2 20 28488 10.528555 1.304844 3 21 6487 3.540265 0.822483 2 22 37708 2.991551 0.833920 1 23 22620 5.297865 0.638306 2 24 28782 6.593803 0.187108 3 25 19739 2.816760 1.686209 2 26 36788 12.458258 0.649617 3
Jupyter
1 %matplotlib inline 2 import numpy 3 import matplotlib 4 import matplotlib.pyplot as plt 5 import kNN 6 from numpy import array 7 a, b = kNN.file2matrix('datingTestSet2.txt') 8 p1 = plt.figure().add_subplot(111) 9 plt.xlabel('Percentage of time spent playing video games') 10 plt.ylabel('Liters of ice cream consumed weekly') 11 p1.scatter(a[:,1],a[:,2],15.0*array(b),15.0*array(b)) 12 plt.show()
显示结果(X:玩视频游戏所耗时间百分比 Y:每周消耗的冰淇淋公升数)

Jupyter
1 %matplotlib inline 2 import numpy 3 import matplotlib 4 import matplotlib.pyplot as plt 5 import kNN 6 from numpy import array 7 a, b = kNN.file2matrix('datingTestSet2.txt') 8 p1 = plt.figure().add_subplot(111) 9 plt.xlabel('Number of frequent flyer miles earned per year') 10 plt.ylabel('Liters of ice cream consumed weekly') 11 p1.scatter(a[:,0],a[:,1],15.0*array(b),15.0*array(b)) 12 plt.show()
显示结果(X:每年的飞行常客里程数 Y:每周消耗的冰淇淋公升数)
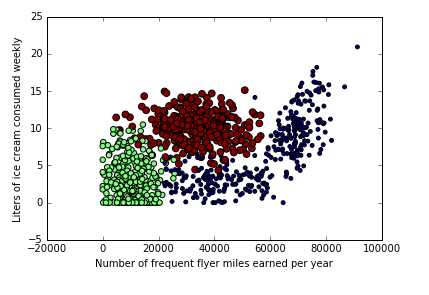


从上图来看每年获得的飞行常客里程数会在很大程度上影响距离的求解但是这三种特征在该环境下应该是同等重要的因此需要对数据进行归一化(公式如下)
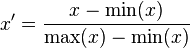
这种归一化方法比较适用在数值比较集中的情况。
归一化特征值函数
1 def autoNorm(dataSet): 2 minVals = dataSet.min(0) #将矩阵每一列进行排序取最小值 3 maxVals = dataSet.max(0) #将矩阵每一列进行排序取最大值 4 ranges = maxVals - minVals 5 normDataSet = zeros(shape(dataSet)) #生成一个与dataSet行列一样的0矩阵 6 m = dataSet.shape[0] #返回矩阵行数 7 normDataSet = dataSet - tile(minVals, (m,1)) 8 normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide 9 return normDataSet, ranges, minVals
归一化函数
1 %matplotlib inline 2 import numpy 3 import matplotlib 4 import matplotlib.pyplot as plt 5 import kNN 6 from numpy import array 7 normMat,max_min,minVals = kNN.autoNorm(a)
执行结果

测试代码
1 def datingClassTest(): 2 hoRatio = 0.50 #hold out 10% 3 datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file 4 normMat, ranges, minVals = autoNorm(datingDataMat) 5 m = normMat.shape[0] 6 numTestVecs = int(m*hoRatio) 7 errorCount = 0.0 8 for i in range(numTestVecs): 9 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) #前50%作为测试数据后 50%作为训练数据 10 print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]) 11 if (classifierResult != datingLabels[i]): errorCount += 1.0 12 print "the total error rate is: %f" % (errorCount/float(numTestVecs)) 13 print errorCount
对于测试代码中的函数一一验证
结果
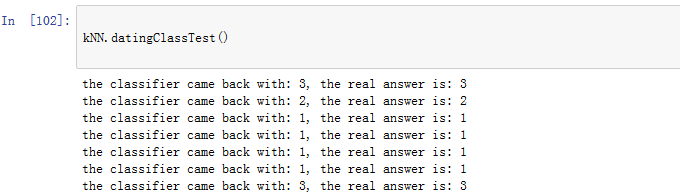
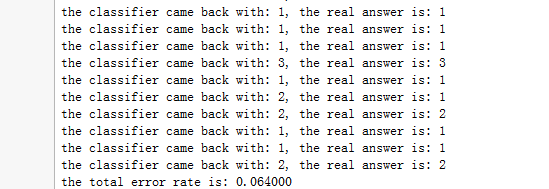
验证结果错误率为6.4%
用于约会网站预测函数:
1 %matplotlib inline 2 import numpy 3 import matplotlib 4 import matplotlib.pyplot as plt 5 import kNN 6 from numpy import array 7 a, datingLabels_b = kNN.file2matrix('datingTestSet2.txt') 8 9 def classifyPerson(): 10 resultList=['not at all','in small doses','in large doses'] 11 percentTats=float(raw_input("percentage of time spent playing video games?")) 12 ffMiles=float(raw_input("frequent flier miles earned per year?")) 13 iceCream=float(raw_input("liters of ice cream consumed per year?")) 14 datingDataSetMat,datingLabels=kNN.file2matrix('datingTestSet2.txt') 15 normMat,ranges,minVals=kNN.autoNorm(a) 16 inArr=array([ffMiles,percentTats,iceCream]) 17 classiferResult=kNN.classify0((inArr-minVals)/ranges,normMat,datingLabels_b,3) 18 print "You will probably like this person:",resultList[classiferResult-1] 19 classifyPerson()
结果:
1 percentage of time spent playing video games?6 2 frequent flier miles earned per year?111111 3 liters of ice cream consumed per year?5 4 You will probably like this person: not at all