SolrCloud(solr 云)是 Solr 提供的分布式搜索方案,当你需要大规模,容错,索引量很大,搜索请求并发很高时可以使用SolrCloud。它是基于 Solr 和Zookeeper的分布式搜索方案,它的主要思想是使用 Zookeeper作为集群的配置信息中心。它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
SolrCloud系统架构图:
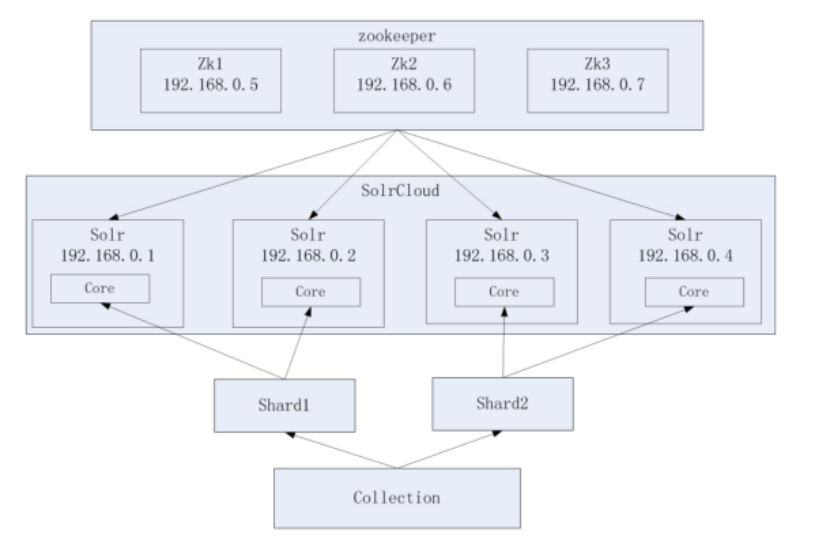
我们可以看到上面的结构图是 4个solr组成一个solrcloud,每个solr里只有一个core,一个shard指向2个solr服务,一主一从,以zookeeper集群作为注册中心。
【1】物理结构
4个 Solr 实例( 每个实例包括1个 Core 也可以多个),组成一个 SolrCloud。
【2】逻辑结构
索引集合包括两个 Shard分片(shard1 和 shard2),shard1 和 shard2 分别由4个Core 组成,其中一个 Leader 两个 Replication,Leader 是由 zookeeper 选举产生,zookeeper 控制每个shard上的Core 的索引数据一致,解决高可用问题。用户发起索引请求分别从 shard1 和 shard2 上获取,解决高并发问题。
【2.1】Collection
Collection 在 SolrCloud 集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个 Shard(分片),它们使用相同的配置信息。比如:针对商品信息搜索可以创建一个 collection。即: collection=shard1+shard2+....+shardX
【2.2】 Core
每个 Core 是 Solr 中一个独立运行单位,提供索引和搜索服务。一个 shard 需要由一个Core 或多个 Core 组成。由于 collection 由多个 shard 组成所以 collection 一般由多个 core 组成。
【2.3】Master 或 Slave
Master 是 master-slave 结构中的主结点(通常说主服务器),Slave 是 master-slave 结构中的从结点(通常说从服务器或备服务器)。同一个 Shard 下 master 和 slave 存储的数据是一致的,这是为了达到高可用目的。
【2.4】Shard
Collection 的逻辑分片。每个 Shard 被化成一个或者多个 replication,通过选举确定哪个是 Leader。
安装步骤
准备工作 1. 安装好jdk和zookeeper 2. 在win上安装好了solr 这些准备工作都可以在楼主的Linux入门安装分类里面找到。
- 把配置好的solr复制成4份,修改每个tomcat的原运行端口8085 8080 8009 ,分别为
8105 8180 8109
8205 8280 8209
8305 8380 8309
8405 8480 8409
因为我们是伪集群所以要靠端口区分,如果是真实集群运行在不同服务器上,它们的ip不同,是不需要改tomcat端口的。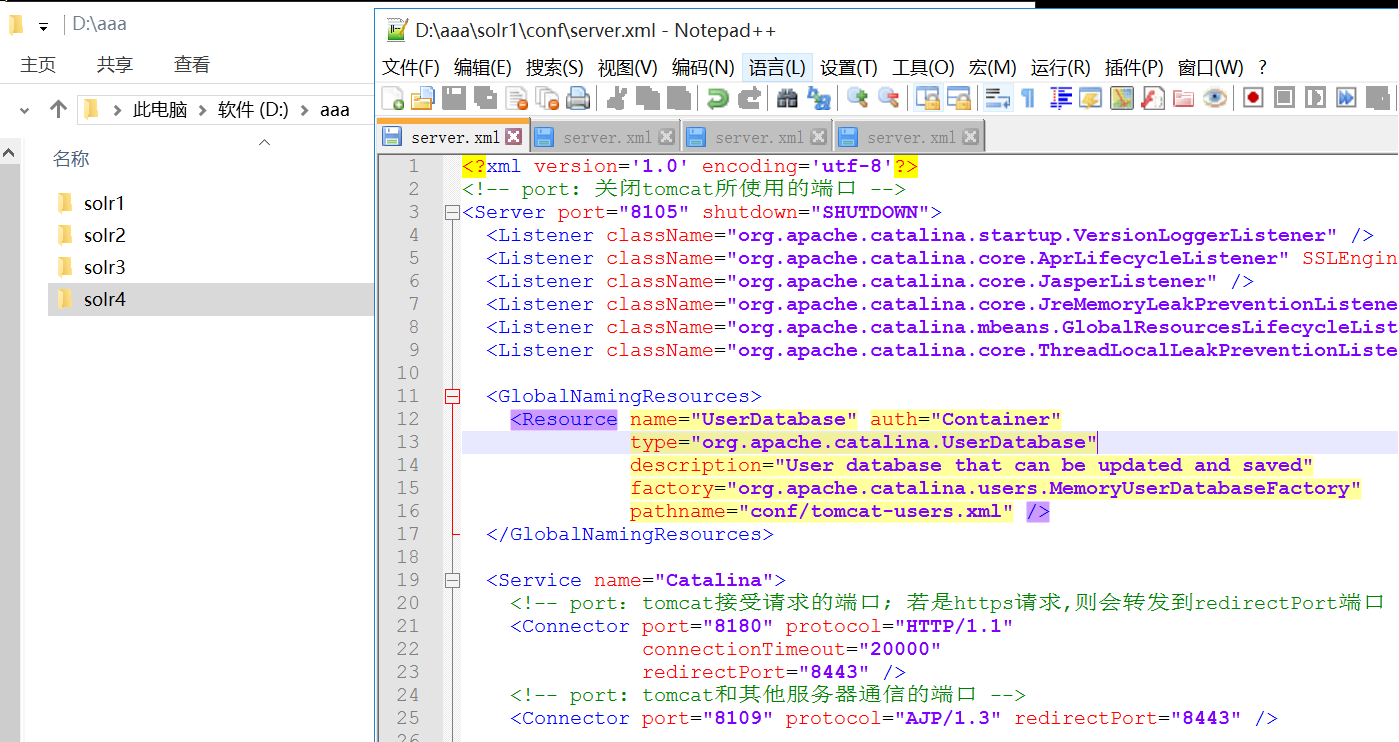
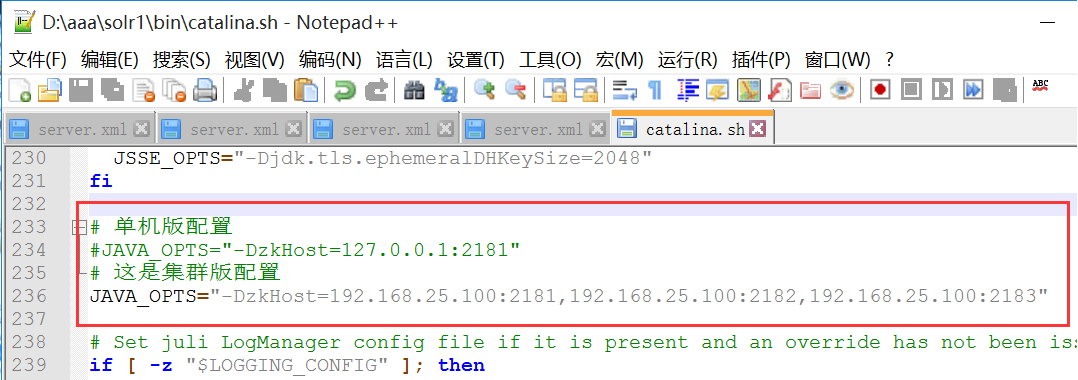
2. 我们是用zk作为solr的管理中心,所以要修改tomcat/bin/catalina.sh的运行参数。4个文件都一样!
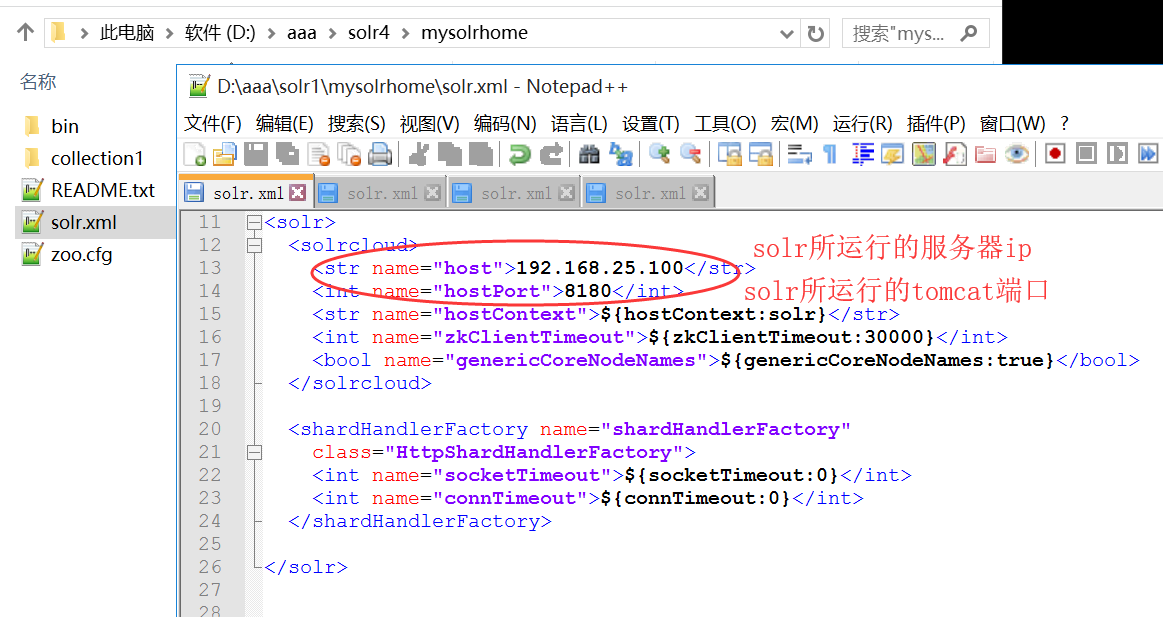
3. 修改4个solrhome的配置文件
4. 刚刚三步已经把所有的准备工作都做完了,接下来我们把solr全部署到服务器上面去。
4.1 创建文件夹 mkdir /usr/local/wulei/solrcloud 把,4个solr服务和solr原生文件全上传到该文件夹里面,。
4.2 解压这4个文件
unzip solr1.zip
unzip solr2.zip
unzip solr3.zip
unzip solr4.zip
5. 给4个solr分别指定solrhome的路径, 我这里以第一个为例:
vim /usr/local/wulei/solrcloud/solr1/webapps/solr/WEB-INF/web.xml
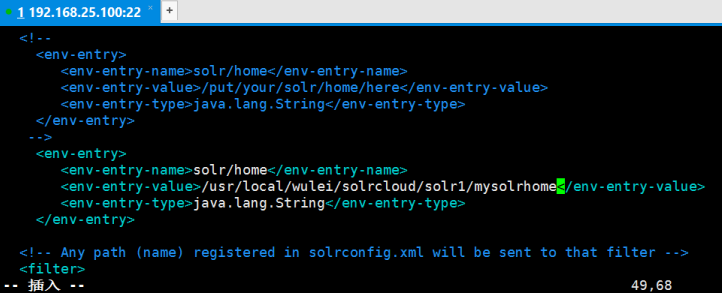
6. 经过上面 5 步,solr就配置好了。为了让zookeeper 统一管理配置文件。需要把刚刚mysolrhome/collection1/conf 目录上传到zookeeper中。(主要是solrCloud的核心配置文件solrconfig.xml和schema.xml),由于我们4个solr的solrhome都一样,所以我们这里无论传哪一个都一样。当我们上传到zk管理之后,solr本地的配置属性就失效了,而是直接读取zk的配置。我们下载solr时,它里面内置了工具上传配置文件:solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh。我们刚刚上传的solr-4.10.3.tgz.tgz就是做这个事的。
6.1 解压 tar -zxvf solr-4.10.3.tgz.tgz
6.2 进入zkcli.sh所在目录: cd /usr/local/wulei/solrcloud/solr-4.10.3/example/scripts/cloud-scripts
6.3 执行上传命令: (必须保证连接的zookeeper已经启动了)
./zkcli.sh -zkhost 192.168.25.100:2181,192.168.25.100:2182,192.168.25.100:2183 -cmd upconfig -confdir /usr/local/wulei/solrcloud/solr1/mysolrhome/collection1/conf -confname mysolrconf
6.4 分别启动4个solr服务。(浏览器连接有点慢,楼主这里花了大概45秒)

【分片配置】
1. 创建新的 Collection 进行分片处理。 在浏览器输入以下地址,可以按照我们的要求 创建新的Collection http://192.168.25.100:8180/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2 参数: name:将被创建的集合的名字 numShards:分片的个数 replicationFactor:从节点的个数。
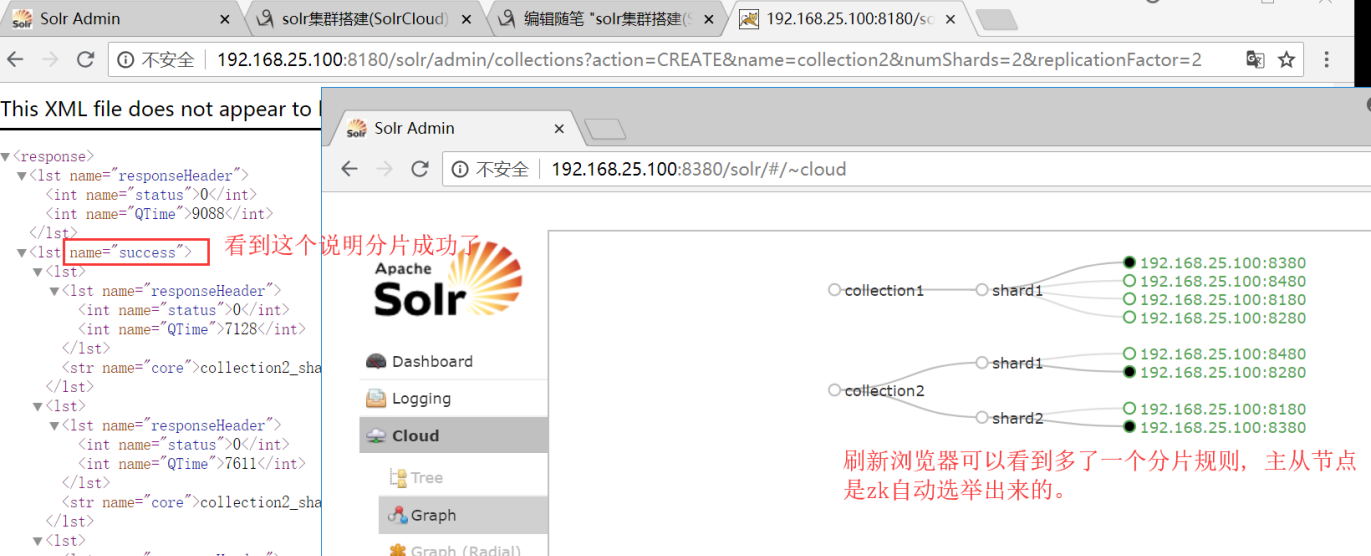
删除分片规则 http://192.168.25.100:8280/solr/admin/collections?action=DELETE&name=collection1

【模拟集群异常测试】
(1)停止第一个tomcat节点,看查询是否能正常工作 -- 能!因为还有从节点
(2)停止第三个tomcat节点,看看查询能够正常工作 -- 不能,因为整个一片数据全没了,无法正常工作。
(3)恢复第三个tomcat节点,看看能否正常工作。恢复时间会比较长,大概2分半到3分钟之间。请耐心等待。