今天我们学习的是spark sql的相关的知识点,一想到,自己最近就要回家了,就会感到幸福,好了不说了,
我们先介绍今天的内容,今天我们讲的是spqrk sql相关的内容
1.我们为什么要学习spark sql
我们已经学习了Hive,它是将Hive SQL转换成为MapReduce然后提交到集群上执行,
大大简化了MapReduce的程序的复杂度,由于MapReduce这种计算模型执行效率比较慢,
所以有了spark sql的应用而生,它是将spark sql转换成为rdd,然后提交到集群上执行,执行
速率非常快
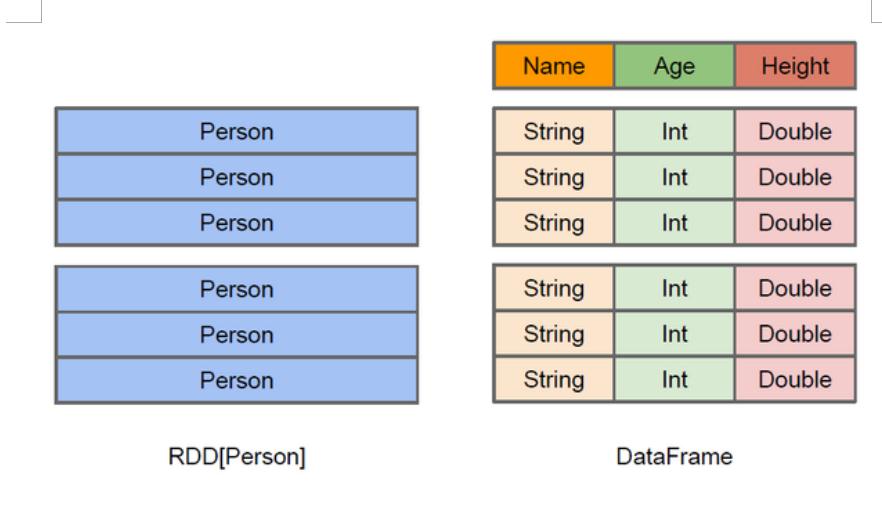
2.什么是DateFrames
与RDD类似,DataFrame也是一种分布式数据容器,然而DataFrame更像传统数据库中的二维
表格,除了数据外,还记录数据的结构信息,即schema,同时,与Hive类似,DataFrame也支持嵌套
数据类型(struct,array和map).从API易用性的角度上看,DataFrame API提供的是一套高层
的关系操作,比函数式的RDD API要更加友好,门槛更低.由于与R和Pandas的DataFrame类似,
Spark DataFrame很好的继承了传统单机数据分析的开发体验
3.hdfs的书写
例如:person.txt里面的数据为
1,laozhao,18
2,laoduan,30
3.loamao,28
val rdd = sc.textFile("hdfs:192.168.109.136:9000/person/person.txt").map(_.split(","))
则会报错:java.lang.IllegalArgumentException:java.net.URISyntaxException:Relative path
inabsolute URI:hdfs:192.168.109.136:9000/person.txt(出现了不被允许的符号)
则此时修改为:
val rdd = sc.textFile(“hdfs://192.168.109.136:9000/person/person.txt”).map(_.split(","))
接下来利用case class
case class person(id:Long,name:String,age:Int)
val personRDD = rdd.map(x => person(x(0).toLong,x(1),x(2).toInt))
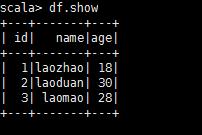
val df = personRDD.toDF
df.show
如果我们想把这个数据转换成为json的格式
df.write.json(“”hdfs://192.168.109.136:9000/person/output“”)
则此时我们在这个目录下回发现有两个目录

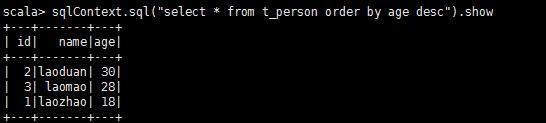
如果想使用SQL风格的语法,需要将DataFrame注册成表
personDF.registerTempTable(“t_person”)
sqlContext.sql(“select * from t_person order by age desc”).show
4.以编程的方式执行spark sql查询
1.添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.2</version>
</dependency>
第一种dataframes,是把rdd映射成为一个类的结构,然后我们在调用toDF,就形成了datafram
然后我们就可以使用sql的一些语句了
代码如下
package cn.wj.spark.day08 import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkConf, SparkContext} /** * Created by WJ on 2017/1/11. */ object SQLDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("SQLDemo").setMaster("local[2]") //如何想在本地执行,则我们就需要setMaster("local"),这个可以简单的理解我们就在IDEA,在集群上运行,我们就不需要 val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) //从hdfs读数据,设置用户访问权限 System.setProperty("user.name","bigdata") val rdd = sc.textFile("hdfs://192.168.109.136:9000/person/person.txt").map(line =>{ val fields = line.split(",") Person(fields(0).toLong,fields(1),fields(2).toInt) }) //导入隐式转换,如果不导入则无法将RDD转换成为DataFrame import sqlContext.implicits._ val personDf = rdd.toDF //xxx.toDf将这个Array[(String)],进行推测类型的操作 personDf.registerTempTable("t_person") sqlContext.sql("select * from t_person where id >= 1 order by id desc ").show() sc.stop() } } case class Person(id:Long,name:String,age:Int)