今天我们讲spark streaming的应用,这个是实时处理的,类似于Storm以及Flink相关的知识点,
说来也巧,今天的自己也去听了关于Flink的相关的讲座,可惜自己没有听得特别清楚,好像是
spark streaming与flink是竞争关系,好了,我们进入今天的主题吧
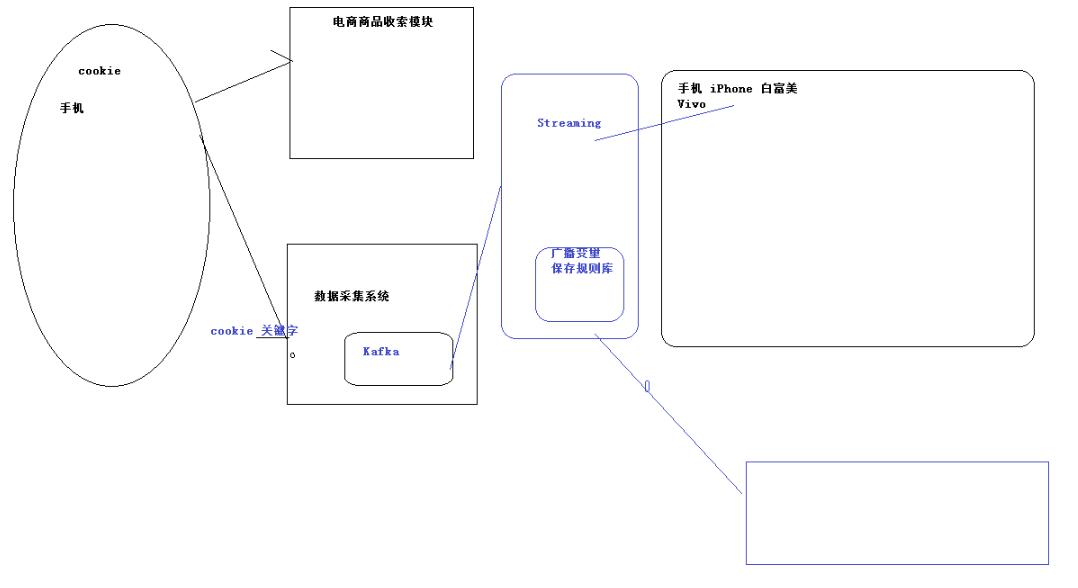
1.一般会做用户画像的差不多集中在两个行业,电商以及广告行业
一般根据现实给这个人打上一个标签,在根据标签来确定画像
2.如果一个人不登录,怎样确定这个人的详情
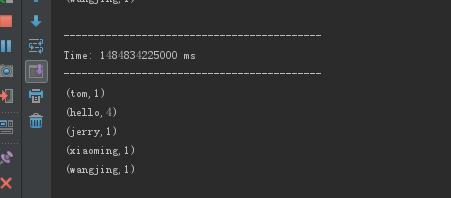
这个就是spark streaming的应用
nc -lk 8888 这个端口可以一直发送数据
请记住,spark中产生的rdd,可能会由于某种意外的原因,从而这个计算可能就要重新开始计算,
但是假如我们设置了checkpoint(如果多个进程同时开始的话,我们可以搞一个共享存储)的时候,
就可以保存这个值,当再一次出现意外的时候,就可以从恢复的这个值重新读取
对于map来说,可以map(),同时也可以map{},这样的两种表达形式,不过当我们写成了case()的
这种形式,则我们必须使用map的大括号的这种形式了,后文附带代码
package cn.wj.spark.day09 import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} /** * Created by WJ on 2017/1/18. */ object StateFulWordCount { //Seq这个批次某个单词的次数 //Option[Int]:以前的结果 //(hello,1),(hello,1),(tom,1) //(hello,Seq(1,1)),(tom,Seq(1)) //此时x=>String(Key的值),y=>Seq[Int](当前的这个value的值),z=>Option[Int],这个代表的是以前的value的值 val updateFunc = (iter:Iterator[(String,Seq[Int],Option[Int])]) =>{ iter.flatMap{case(x,y,z) => Some(y.sum+z.getOrElse(0)).map(m =>(x,m))} } def main(args: Array[String]): Unit = { LoggerLevels.setStreamingLogLevels() //StreamingContext val conf = new SparkConf().setAppName("StreamingContext").setMaster("local[2]") val sc = new SparkContext(conf) sc.setCheckpointDir("/tmp/ck") // sc.setCheckpointDir("hdfs://192.168.109.136:9000/person/myfile") val ssc = new StreamingContext(sc,Seconds(5)) val ds = ssc.socketTextStream("192.168.109.136",8888) //updateStateByKey:这个方法的意思是说将每一次的partition都进行一次累计 val result = ds.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc,new HashPartitioner(sc.defaultParallelism),true) result.print() ssc.start() ssc.awaitTermination() } }
其中,LoggerLevels.setStreamingLogLevels()这个是设置日志文件的显示情况的,是让打出来的日志更清晰,
如果没必要,可以删除的。
首先我们在linux里面向8888端口发送信息:
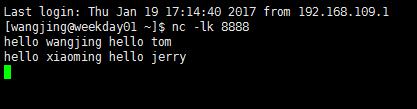
然后启动项目,这个时候就可以看见这个效果了(可以叠加的spark streaming)