1.Hive表文件的存储格式
通过上述的stored as操作设置表的存储格式
hive文件的存储格式分为以下四种:
TEXTFILE,SEQUENCEFILE,RCFILE,ORCFILE
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时直接把数据文件copy到HDFS上不进行处理;
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入textfile格式的表中,然后在从表中用insert导入SEQUENCEFILE,RCFILE,ORCFILE中;
1.1 TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大;
可结合Gzip,Bzip使用(系统自动检查,执行查询时解压),但使用这种方式,hive默认对数据不会切分,从而无法对数据进行并行操作;
在反序列化的过程中,必须逐个字符判断是不是分隔符或行终止符,因此反序列化开销最大;
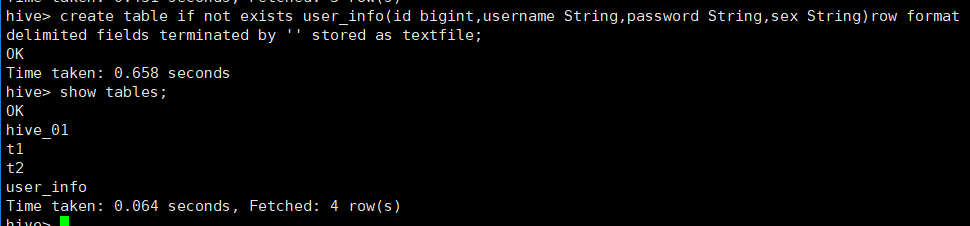
1.1.1 创建一张UserInfo表:
create table if not exists user_info(id bigint,username String,password String,sex String)row format delimited fields terminated by ' ' stored as textfile;
1.1.2 使用load语句加载数据:
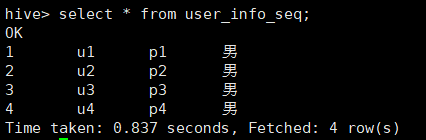
1 u1 p1 男
2 u2 p2 男
3 u3 p3 男
4 u4 p4 男

load data local inpath '/opt/module/hive/data/user_info' overwrite into table user_info;
1.1.3 查看表数据:
select * from user_info;

1.2 SEQUENCEFILE格式
SequenceFile是hadoop API提供的一种二进制文件,它将数据以二进制的形式序列化到文件中;这种二进制文件内部使用hadoop的标椎的writeable接口实现序列化和反序列化;它与hadoop API中的MapFile是互相兼容的;Hive中的SequenceFile继承自hadoop API的SequenceFile,不过它的key为空,使用value存放实际的值,这样是为了避免MR在运行map阶段的排序过程;
1.2.1 创建表:
create table if not exists user_info_seq(id bigint,username String,password String,sex String)row format delimited fields terminated by ' ' stored as sequencefile;
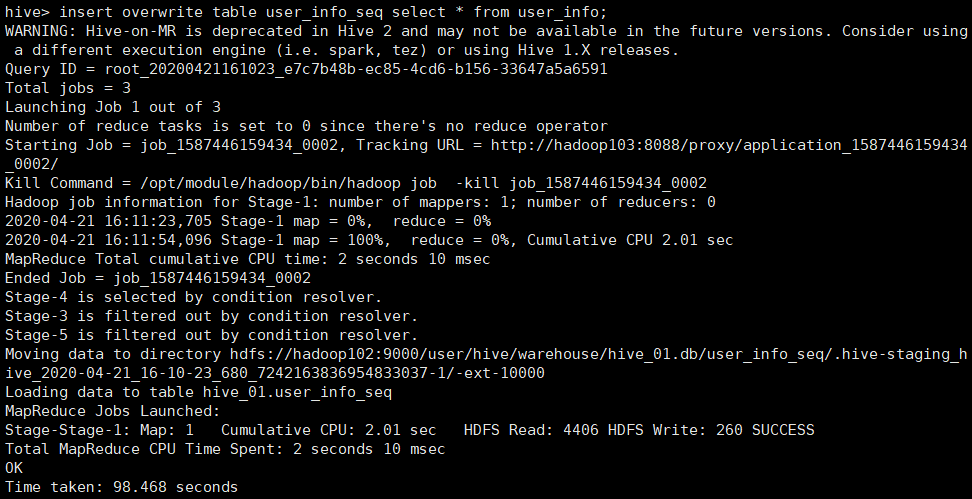
1.2.2 数据导入:
insert overwrite table user_info_seq select * from user_info;
1.2.3 查看表数据:
select * from user_info_seq;
1.3 RCFILE格式
RCFILE是一种行列存储相结合的存储方式;首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block;其次,块数据列式存储,有利于数据压缩和快速的列存放;
1.3.1 创建表:
create table if not exists user_info_rc(id bigint,username String,password String,sex String)row format delimited fields terminated by ' ' stored as rcfile;
1.3.2 数据导入:
insert overwrite table user_info_rc select * from user_info;
1.3.3 查看表数据:
select * from user_info_rc;

1.4 ORCFILE格式
Orcfile(Optimized Row Columnar)是hive 0.11版里引入的新的存储格式,是对之前的RCFile存储格式的优化;
可以看出每个Orc文件由一个或多个stripe(线条组成),每个stripe250MB大小,这个stripe实际相当于之前的rcfile里的RowGroup概念,不过大小由4MB->250MB,这样应该能提升顺序读的吞吐量;每个stripe里有三部分组成,分别是IndexData,Row Data,Stripe Footer:

(1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引;这里做的索引只是记录某行的各字段在Row Data中的offset;
(2)Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储;与RCfile不同的地方在于每个列进行了编码,分成多个stream来存储;
(3)Stripe Footer:存的是各个stream的类型,长度等信息;
每个文件有一个File Footer,这里面存的是stripe的行数,每个column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等;在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读File Footer,从里面解析到各个stripe信息,再读各个stripe,即从后往前读;
1.4.1 创建数据表:
create table if not exists user_info_orc(id bigint,username String,password String,sex String)row format delimited fields terminated by ' ' stored as orcfile;
1.4.2 数据导入:
insert overwrite table user_info_orc select * from user_info;
1.4.3 查看表数据:
select * from user_info_orc;

1.5 结论
textfile:存储空间消耗比较大,并且压缩的text无法分割和合并,查询的效率最低,可以直接存储,加载数据的速度最高;
sequencefile:存储空间消耗最大,压缩的文件可以分割和合并,需要通过text文件转化来加载;
rcfile:存储空间小,查询的效率高,需要通过text文件转化来加载,加载的速度最低;
orcfile:存储空间最小,查询的效率高,需要通过text文件转化来加载,加载的速度最低;
2.Hive SerDe
2.1 什么是SerDe
SerDe是“Serializer and Deserializer”(序列化器和反序列化器的缩写);
Hive使用SerDe读写表的行数据;
HDFS FILEX-->InputFileFormat--><key,value>-->Deserializer-->Row Object;
Row Object-->Serializer--><key,value>-->OutputFileFormat-->HDFS FILES;
注意:“key”部分在读时被忽略,在写时始终是常量;基本上,row对象存储在value中序列化是对象转换为字节序列的过程;反序列化是字节序列恢复为对象的过程;对象的序列化主要由两种用途:对象的持久化,即把对象转换成字节序列后保存到文件中;对象数据的网络传送;除了上面两点,hive的序列化的作用还包括:Hive的反序列化是对key/value反序列化成hive table的每个列的值;Hive可以方便的将数据加载到列表中而不需要对数据进行转换,这样在处理海量数据时可以节省大量的时间;
erDe说明hive如果去处理一条记录,包括Serialize/Deserilize两个功能,Serialize把hive使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件;Deserilize把字符串或者二进制流转换成hive能识别的java object对象;比如:select语句会用到Serialize对象,把hdfs数据解析出来;insert语句会使用Deserilize对象,数据写入hdfs系统,需要把数据序列化;
Hive的一个原则是Hive不拥有HDFS文件格式;用户应该能够使用工具直接读取Hive表的HDFS文件或者使用其他工具直接写那些可以加载外部表的HDFS文件;
2.2 RegExpSerDe的用法
2.2.1 数据准备:
id=123,name=wldy
id=55,name=qtxsn
id=666,name=sjdf
Id=345,name=zs
2.2.2 期望输出格式:
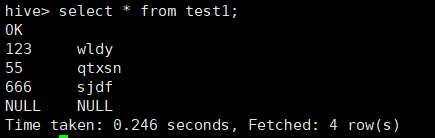
123 wldy
55 qtxsn
666 sjdf
345 zs
2.2.3 创建表:
input.regex(按照输入的正则匹配)
create table test1(id int,name String)row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties ("input.regex"="id=(.*),name=(.*)") stored as textfile;
2.2.4 加载数据:
load data local inpath '/opt/module/hive/data/regexptest' overwrite into table test1;
2.2.5 查询表数据:
select * from test1;
2.3 JsonSerDe的用法
2.3.1 数据准备:
{"id":1, "create_at":"20190317", "text":"你好", "user_info":{"id":"1","name":"binghe01"}}
{"id":2, "create_at":"20190317", "text":"Hello", "user_info":{"id":"2","name":"binghe02"}}
需要注意的问题:每行必须是一个完整的JSON,一个JSON串不能跨越多行,原因是hadoop是依赖换行符分割文件的;
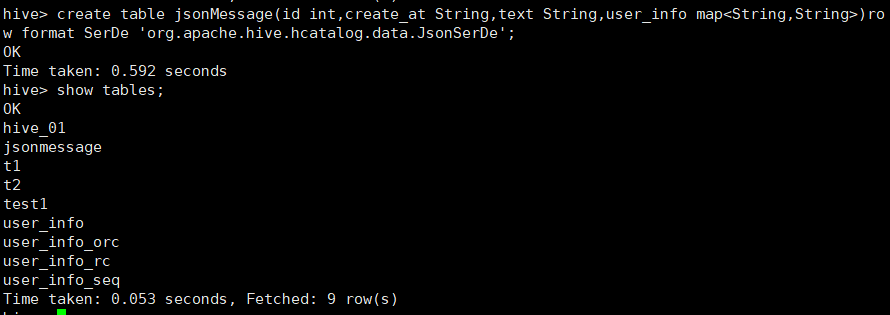
2.3.2 创建表:
create table jsonMessage(id int,create_at String,text String,user_info map<String,String>)row format SerDe 'org.apache.hive.hcatalog.data.JsonSerDe';
2.3.3 加载数据:
load data local inpath '/opt/module/hive/data/json' overwrite into table jsonMessage;
2.3.4 查询表数据:
select * from jsonMessage;

3.Hive表的修改操作
大多数的表属性可以通过ALTER TABLE语句来进行修改;这种操作会修改元数据,但不会修改数据本身;
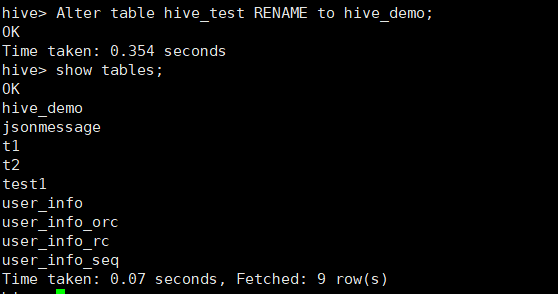
3.1 表重命名
语法:Alter table 旧名称 RENAME to 新名称;
Alter table hive_test RENAME to hive_demo;
3.2 修改列信息
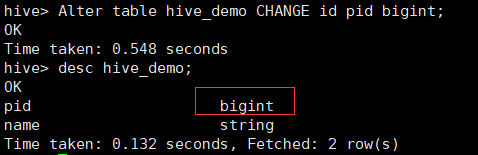
语法:Alter table 表名 CHANGE [COLUMN] 列名 新列名 数据类型 [COMMENT 注释文本] [AFTER 字段名称|FIRST];
注意:即使字段名和类型没有改变,用户也需要完全指定旧的字段名,并给出新的字段名和字段类型;COMMENT与AFTER关键字可以省去,COMMENT关键字的所用是为列声明新的注释,AFTER关键字的作用是将当前修改的列防止对应字段名称之后,如果要放在最前面,则使用FIRST关键字代替;
Alter table hive_demo CHANGE id pid bigint;
3.3 增加列
Hive能将新的字段添加到已有字段之后;
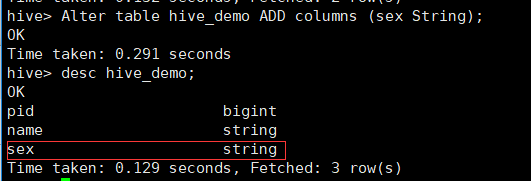
语法:Alter table 表名 ADD COLUMNS(列名 字段类型[COMMENT '注释'],......);
Alter table hive_demo ADD columns (sex String);
3.4 删除或替换列
语法:Alter table 表名 REPLACE COLUMNS (列名 字段类型 [COMMENT '注释'],......);
Alter table hive_demo REPLACE columns (name String);

3.5 修改表的存储属性
语法:Alter table 表名 SET FILEFORMAT(TEXTFILE|SEQUENCEFILE|RCFILE|ORCFILE);
Alter table hive_demo SET FILEFORMAT ORCFILE;
3.6 修改表的普通属性
语法:Alter table 表名 SET TBLPROPERTIES('属性名'='属性值');
Alter table hive_demo set tblproperties('comment','best!');
3.7 修改表的SerDe格式
语法:Alter table 表名 SET SERDEPROPERTIES('属性名'='属性值');
3.8 查看表的详细建表语句
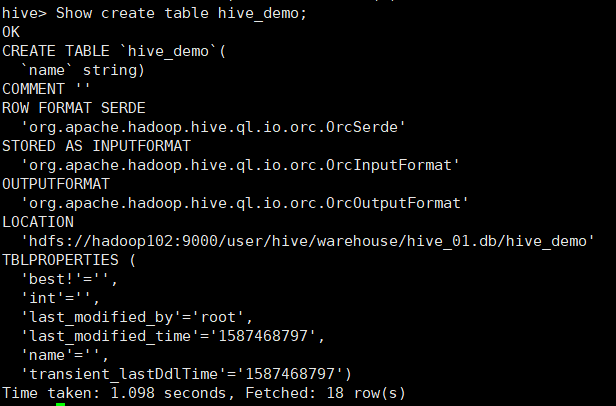
语法:Show create table 表名;
Show create table hive_demo;