1.视图
和关系型数据库一样,Hive也提供了视图的功能,不过请注意,Hive的视图和关系型数据的视图还是有着很大的区别:
(1)只要逻辑视图,没有物理视图;
(2)视图只提供查询操作,不能执行LOAD/INSERT/UPDATE/DELETE
(3)视图在创建的时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的查询操作;
1.1 创建一个视图
create view user_view as select * from user_info;
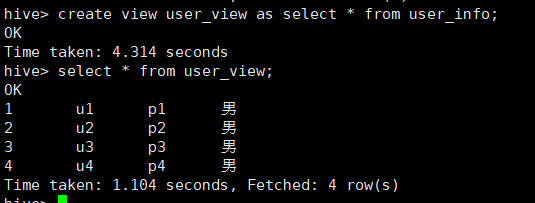
1.2 查看视图
show views; #查看所有视图

desc user_view; #查看某个视图的详情

1.3 检索视图
语法:select * from 视图名称;
select * from user_view;
将视图作为虚拟表进行检索;
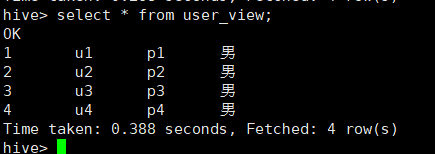
1.4 删除视图
语法:drop view 视图名称;
drop view user_view;
2.内置函数
cast(expr as <type>)
类型转换
select cast('1' as bigint);
split(String str,String par)
按照指定符号切割成array
select split('hello',sjdf,',');
regexp_extract(String subject,String pattern,int index)
基于正则表达式截取字符串
select regexp_extract('hello<B>nice</B>haha','<B>(.*)</B>',1);
trim(String word)
清除字符串空格
select trim('sjdf ');
sum avg min max count 聚合函数
3.处理JSON数据
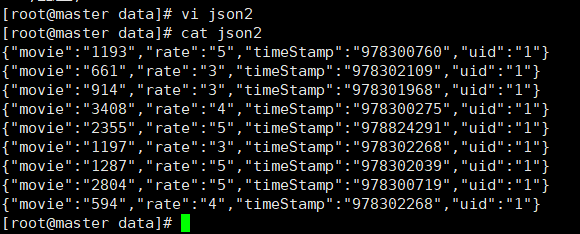
3.1 JSON数据如下:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
3.2 创建表:
create table json_data(data String);
3.3 load载入数据:
load data local inpath '/opt/module/hive/data/json2' overwrite into table json_data;
3.4 借助函数get_json_object检索JSON数据中的某个键的值:
该方法只能获取一个键的值;
select get_json_object(data,'$.movie')as movie from json_data;

3.5 解析JSON中多个键的值:
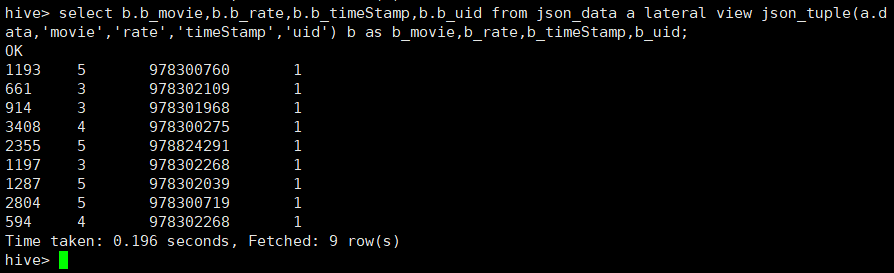
select b.b_movie,b.b_rate,b.b_timeStamp,b.b_uid from json_data a lateral view json_tuple(a.data,'movie','rate','timeStamp','uid') b as b_movie,b_rate,b_timeStamp,b_uid;
4.窗口函数
窗口函数使你能够在一个数据集上创建一个窗口,并允许你在这个数据上使用聚合函数;
4.1 SUM,AVG,MIN,MAX
与OVER语句联用的标椎集合函数,OVER语句指定分析函数工作的数据窗口大小,决定了集合函数的范围,这个数据窗口大小可能会随着行的变化而变化;
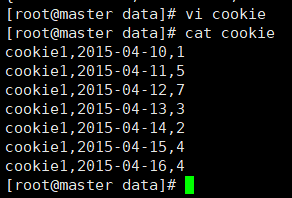
4.1.1 数据准备:
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
4.1.2 创建数据表:
create table cookie1(cookieid String,createtime String,pv int)row format delimited fields terminated by ',';

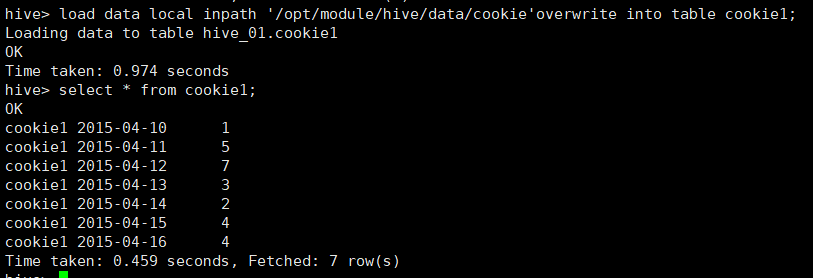
4.1.3 load载入数据:
load data local inpath '/opt/module/hive/data/cookie'overwrite into table cookie1;
4.1.4 SUM函数求和:
select
cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
上述关键词分析:
(1)如果不指定ROWS BETWEEN,默认为从起点当当前行;
(2)如果不指定ORDER BY,则将分组内所有的值累加;
(3)ROWS BETWEEN中的WINDOW字句;
PRECEDING:往前;
FLLOWING:往后;
CURRENT ROW:当前行;
UNBOUNDED:起点;
(4)UNBOUNDED PRECEDING:表示从前面的起点;
(5)UNBOUNDED FOLLOWING:表示到后面的起点;
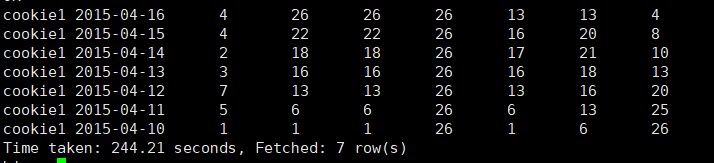
结果解析:
pv1:是将pv的值在当前分组中从首行加到当前行;
pv2:同上ROWS BETWEEN可以省略不写
pv3:当省略了order by的情况下,不会进行排序,而是将当前分组中的所有值进行累加;
pv4:是将pv的值在当前分组中从当前行+往前3行的累计值;
pv5:是将pv的值在当前分组中从当前行+往前3行+往后1行的累计值;
pv6:是将pv的值在当前分组中从当前行一致累计到尾行;
其余的聚合函数使用方式等同于SUM;
4.2 NEILE,ROW_NUMBER,RANK,DENSE_PANK
4.2.1 数据准备:
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
4.2.2 创建表
create table cookie2(cookieid String,createtime String,pv int)row format delimited fields terminated by ',';

4.2.3 插入数据
load data local inpath '/opt/module/hive/data/cookie2' into table cookie2;
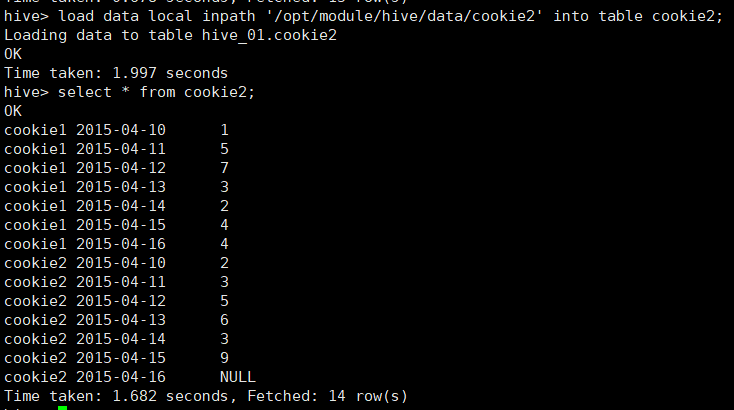
4.2.4 NTILE
用户将分组数据按照顺序切分成n片,返回当前切片值;
NTILE不支持ROWS BETWEEN,如果切片不均匀,默认增加第一个切片的分布;
查询语句:
select
cookieid,
createtime,
pv,
ntile(2) over (partition by cookieid order by createtime) as rn1, #分组内将数据分成2片
ntile(3) over (partition by cookieid order by createtime) as rn2, #分组内将数据分成3片
ntile(4) over (order by createtime) as rn3 #分组内将数据分成4片
from cookie2
order by cookieid,createtime;
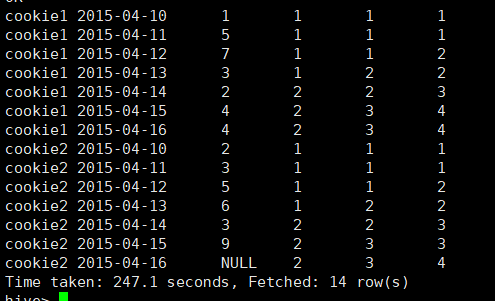
按照顺序将组内的数据分为两片,一般用来求前几分之几的数据
举例:统计一个cookie,PV数最多的前1/3的天;
select
cookieid,
createtime,
pv,
ntile(3) over (partition by cookieid order by pv desc ) as rn
from cookie2;
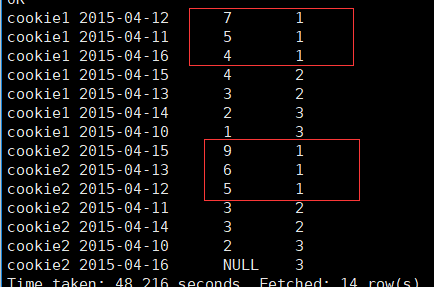
前三分之一的数据也就是rn为1的记录;
4.2.5 ROW_NUMBER
从1开始,按照顺序,生成分组内记录的序列,一般用来获取记录的前几名;
举例:分组统计pv最多的前三名
select * from
(select
cookieid,
createtime,
pv,
row_number() over (partition by cookieid order by pv desc) as rn
from cookie2) t where rn<=3;
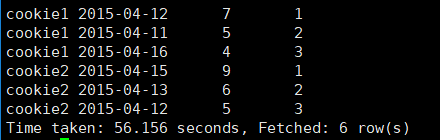
4.2.6 RANK和DENSE_PANK
RANK:生成数据项在分组中的排名,排名相等会在名词中留下空位;
DENSE_PANK:生层数据项在分组中的排名,排名相等不会在名次中留下空位;
select
cookieid,
createtime,
pv,
rank() over (partition by cookieid order by pv desc) as rn1,
dense_rank() over (partition by cookieid order by pv desc ) as rn2,
row_number() over(partition by cookieid order by pv desc) as rn3
from cookie2;
4.3 LAG.LEAD,FIRST_VALUE,LAST_VALUE
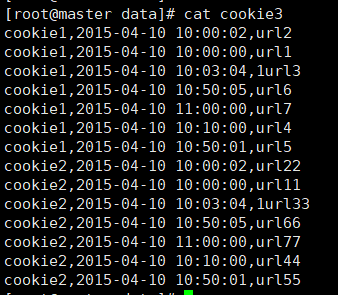
4.3.1 数据准备:
cookie1,2015-04-10 10:00:02,url2
cookie1,2015-04-10 10:00:00,url1
cookie1,2015-04-10 10:03:04,1url3
cookie1,2015-04-10 10:50:05,url6
cookie1,2015-04-10 11:00:00,url7
cookie1,2015-04-10 10:10:00,url4
cookie1,2015-04-10 10:50:01,url5
cookie2,2015-04-10 10:00:02,url22
cookie2,2015-04-10 10:00:00,url11
cookie2,2015-04-10 10:03:04,1url33
cookie2,2015-04-10 10:50:05,url66
cookie2,2015-04-10 11:00:00,url77
cookie2,2015-04-10 10:10:00,url44
cookie2,2015-04-10 10:50:01,url55
4.3.2 创建表:
create table cookie3(cookieid String,createtime String,url String)row format delimited fields terminated by ',';
4.3.3 load载入数据:
load data local inpath '/opt/module/hive/data/cookie3' into table cookie3;

4.3.4 LAG(col,n,DEFAULT)
用户统计窗口内往上第n行值;
col参数为列名;
n参数为往上第n行(可选,默认为1);
DEFAULT参数为默认值(当往上第n行为NULL时候,取消默认值,如不指定,则为NULL);
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LAG(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as last_1_time,
LAG(createtime,2) over (partition by cookieid order by createtime) as last_2_time
from cookie3;

4.3.5 LEAD与LAG相反
LEAD(col,n,DEFAULT)用于窗口内往下第n行值;
col参数为列名;
n参数为往下第n行(可选,默认为1);
DEFAULT参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LEAD(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as next_1_time,
LEAD(createtime,2) over (partition by cookieid order by createtime) as next_2_time
from cookie3;

4.3.6 FIRST_VALUE
取分组内排序后,截止到当前行,第一个值;
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
first_value(url) over (partition by cookieid order by createtime) as first1
from cookie3;
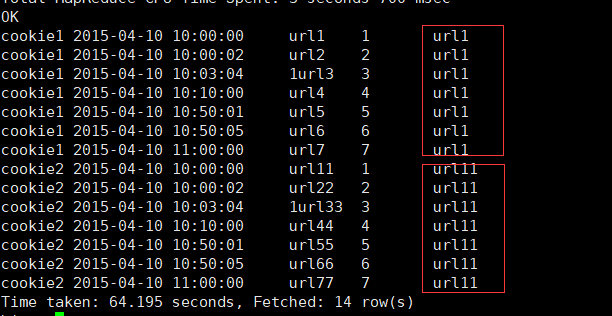
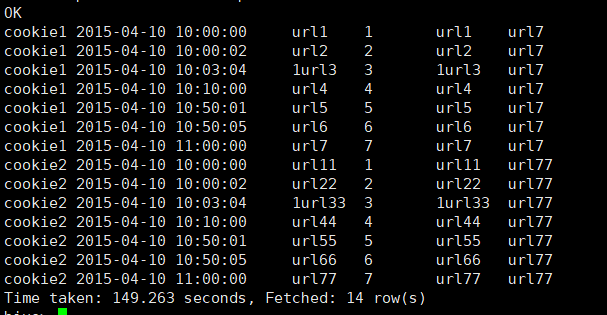
4.3.7 LAST_VALUE
取分组内排序后,截止到当前行,最后一个值
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LAST_VALUE(url) over (partition by cookieid order by createtime) as last1, #最后一个值永远是自己本身
FIRST_VALUE(url) over (partition by cookieid order by createtime desc) as last2 #通过FIRST_VALUE获取
from cookie3
order by cookieid,createtime; #注意SQL执行顺序 from-->order by-->select
5.自定义函数
当Hive提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数;
HDF(user-defined function)作用域单个数据行,产生一个数据行作为输出;
UDAF(用户定义聚集函数 User-Defined Aggregation Funcation):接收多个输入数据行,并产生一个输出数据行;类似于max,min;
UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行,类似于explode;
5.1 自定义UDF函数:
5.1.1 导入依赖包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.5</version>
</dependency>
5.1.2 自定义UDF类
public class LowerUDF extends UDF{
public String evaluate(String field) {
String result = field.toLowerCase();//小写
return result;
}
}
5.1.3 打成jar文件后上传至master节点上
5.1.4 添加jar包到hive中
ass JAR /opt/module/hive/data/hive-1.0-SNAPSHOT.jar;
list jar;
5.1.5 创建临时函数与jar中的class关联
create temporary funcation tolowercase as 'com.wn.LowerUDF';
5.1.6 尝试运行
select tolowercase('SJDF');
注意:这种方式创建的临时函数只在一次hive会话中有效,重启后会话就失效了;
(1)永久失效:
如果需要经常使用该自定义函数,可以考虑创建永久函数;
拷贝jar包到hive的lib目录下;
创建永久关联函数:
create temporay funcation tolowercase as 'cn.jixiang.udf.FirstUDF';
(2)删除函数:
删除临时函数
drop temporary funcation tolowercase;
删除永久函数
drop funcation tolowercase;