安装
1.安装相关依赖:Twisted
pip install Twistedkdjdkfjd.whl
2.安装scrapy框架:
pip install scrapy
1.scrapy框架介绍
#爬虫当中:scrapy框架
scrapy是一个基于Twisted异步框架的爬虫框架(异步,爬虫框架)
scrapy异步 快,解耦的思想
用在数据量比较大的爬虫项目中,分布式爬虫,增量式爬虫
2.文件解释
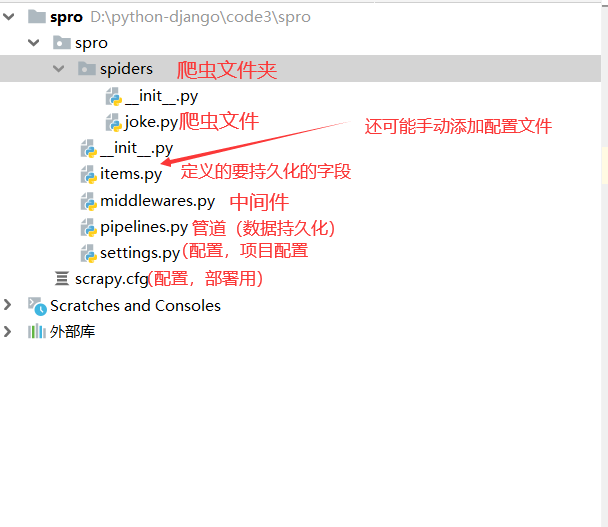
3.项目说明
1).spiders:其内包含一个个Spider的实现,每个Spider是单独的文件
2).tiems.py:它定义了item数据结构,爬取到的数据存储为那些字段
3).pipelines.py:管道,负责数据持久化
4).settings.py:项目的全局配置
5).middlewares.py:定义中间件,包括爬虫中间件和下载中间件
6).scrapy.cfg:他是scrapy项目的配置文件,其内定义了项目的配置路径,部署相关的信息等7).costom_settings.py: 多个爬虫私有配置
4.数据流向
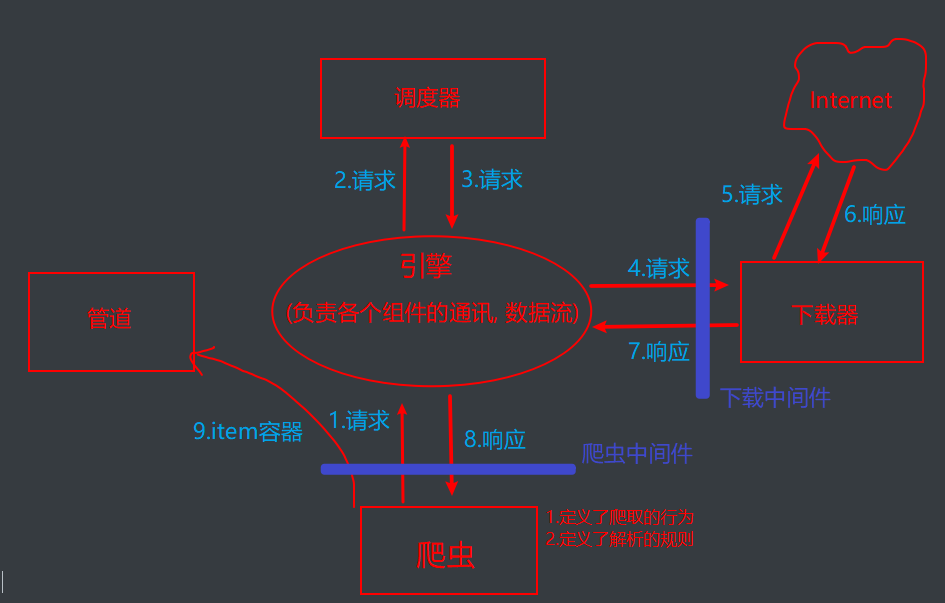
5.常规操作
title = li.xpath('./span/a/text()').extract()
# .extract()过滤出所有的文本
link=li.xpath('./span/a/@href').extract_first()
# .extract_first()过滤出第一条文本
yield scrapy.Request(url=link,method='GET',callback=self.detail_parse,meta={'title':title})
# callback:回调函数。 回调进入某个函数
# meta传参,传参为字典形式
6.scrapy框架
#创建项目
scrapy startproject projectname(项目名) #创建项目
cd projectname #进入项目目录
scrapy genspider 爬虫名 域名 #创建爬虫 ps:域名 baidu.com
#运行 (两种方式)
scrapy crawl 爬虫名
scrapy runsider 爬虫py文件名
模块详解
#爬取字段:items.py
import scrapy
class ProItem(scrapy.Item):
#定义要爬取的字段
name = scrapy.Field()
comment = scrapy.Field()
#爬虫
import scrapy
from ..items import ProItem
class Prosider(scrapy.Spider):
#爬虫名,爬虫名是爬虫的唯一身份标识,在运行时会用到,不能删
name = 'psider'
#限定爬取范围:需要注释掉,如果不注释,请求的域名与该域名相同才会发起请求,否则请求会被过滤掉
allowed_domains=['www.baidu.com']
#起始url:项目一启动,会自动对start_urls当中url发起请求
start_urls = []
#自定义的解析方法
def detail_parse(self,response):
#meta传参的取值方法
title = response.meta['title']
pass
#解析方法:提供了解析规则,实例化item容器,提交item至管道,手动发送请求
#如果请求未指定解析,默认调用parse解析方法
def parse(self, response):
# 解析的规则
title_list = response.xpath() --> 其获得的结果为: selector对象, selector对象还能进行xpath
#如果要从某个xpath解析的列表里面取值:extract()和extract_first()
#extract():取多条
#extract_first():取一条
for title in title_list: item = ProItem()
item['title'] = title
link = 'dfkdfjk'
# yield item
#回调给另一个函数,解析详情页
yield scrapy.Request(url=link, callback=self.xxx_parse, meta={'item': item}, method="GET")
# 管道: PipeLine 导入mongodb进行存储
import pymongo
class ProPipeline(object):
conn = pymongo.MongoClient('localhost', 27017) # localhost是数据库的地址, 27017是端口
db = conn.songxuefei
table = db.hanlei
def process_item(self, item, spider):
self.table.insert_one(dict(item))
return item
# 配置文件:
1.User-Agent:
2.RobotTxtobey = False
3.ITEM_PIPELINES = [
# 注释放开
]
4.DOWNLOAD_DELAY = 3 #下载延迟
7.中间件
#scrapy框架中中间件的种类
1 爬虫中间件:SpiderMiddleware
1) 拦截请求
2) 拦截响应
3) 拦截item:item丢弃
2. 下载中间件:DownloadMiddleware
1) 拦截请求
2) 拦截响应
下载中间件的核心方法:
1).process_request: 拦截正常请求
2).process_response: 拦截所有响应
3).process_exception: 拦截异常请求
8.数据持久化
#核心方法
1。开始调用:连接数据库
open_spider(self,spider) :spider开启时被调用
2。爬虫结束时调用:关闭数据库连接
close_spider(self,spider) :spider关闭时被调用
3。用来取配置
from_crawler(cls,crawler) :类方法,用@classmethod标识,可以获取配置信息
4。(非常重要!!)实际与数据库进行交互,实现数据存储的方法
process_item(self,item,spider) :与数据库交互存储数据,该方法必须实现
#注意事项:1。方法名已经再底层封装过,方法可以重写,但名字必须一致 2.return item:存在多个类管道时,权重小必须return item ,权重大的管道类才能接受到item进行存储
8.构建post请求
import scrapy
import json
class FanyiSpider(scrapy.Spider):
name = 'fanyi'
# allowed_domains = ['baidu.com']
start_urls = ['https://fanyi.baidu.com/sug']
#重写start_requests父类方法
def start_requests(self):
data={
'kw':'boy'
}
yield scrapy.FormRequest(url=self.start_urls[0],formdata=data,callback=self.parse)
def parse(self, response):
ret = json.loads(response.text)
print(ret)