#!/usr/bin/env python3
days = int(input("Enter days: "))
print("Months = {} Days = {}".format(*divmod(days, 30)))
divmod(num1, num2) 返回一个元组,这个元组包含两个值,第一个是 num1 和 num2 相整除得到的值,第二个是 num1 和 num2 求余得到的值,然后我们用 * 运算符拆封这个元组,得到这两个值。
a, b = b, a + b
含义:将 a + b 的值赋值给 b,b 的值赋值给 a
解释:Python 中赋值语句执行时会先对赋值运算符右边的表达式求值,然后将这个值赋值给左边的变量
默认情况下,print() 除了打印你提供的字符串之外,还会打印一个换行符,所以每调用一次 print() 就会换一次行。
你可以通过 print() 的另一个参数 end 来替换这个换行符:
print('wonker', end=' ')
我们来写一个程序计算幂级数:e^x = 1 + x + x^2 / 2! + x^3 / 3! + ... + x^n / n! (0 < x < 1)。
#!/usr/bin/env python3
x = float(input("Enter the value of x: "))
n = term = num = 1
result = 1.0
while n <= 100:
term *= x / n #x^3 / 3! = x^2 * x / 2! * 3;化简后即 T = t * x/n
result += term
n += 1
if term < 0.0001:
break
print("No of Times= {} and Sum= {}".format(n, result))
print("-" * 50)
字符串若是乘上整数 n,将返回由 n 个此字符串拼接起来的新字符串。例:
>>> 's' * 10
'ssssssssss'
>>> print("*" * 10)
**********
列表切片:
切片时的索引是在两个元素之间 。左边第一个元素的索引为 0,而长度为 n 的列表其最后一个元素的右界索引为 n。
+---+-----+-----+---------+----------+
| 1 | 342 | 223 | 'India' | 'Fedora' |
+---+-----+-----+---------+----------+
0 1 2 3 4 5
-5 -4 -3 -2 -1
上面的第一行数字给出列表中的索引点 0...5。第二行给出相应的负索引。切片是从 i 到 j 两个数值表示的边界之间的所有元素。
对于非负索引,如果上下都在边界内,切片长度就是两个索引之差。例如 a[2:4] 是 2。
Python 中有关下标的集合都满足左闭右开原则,切片中也是如此,也就是说集合左边界值能取到,右边界值不能取到。
对上面的列表, a[0:5] 用数学表达式可以写为 [0,5) ,其索引取值为 0,1,2,3,4,所以能将a中所有值获取到。 你也可以用a[:5], 效果是一样的。
而a[-5:-1],因为左闭右开原则,其取值为 -5,-4,-3,-2 是不包含 -1 的。
为了取到最后一个值,你可以使用 a[-5:] ,它代表了取该列表最后5个值。




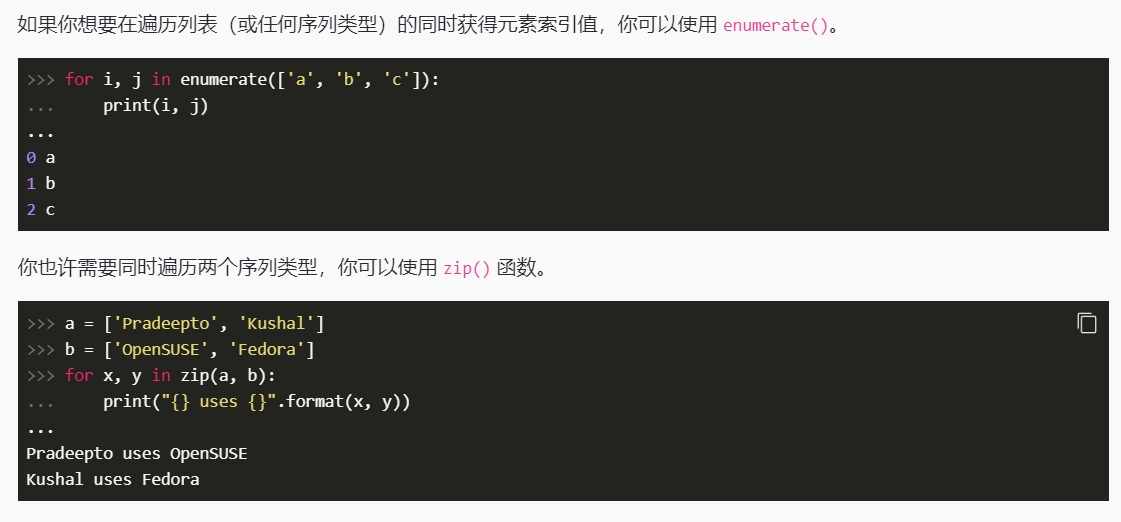
for 循环我们通常与 range() 函数配合使用,要特别注意的是,range() 函数返回的并不是列表而是一种可迭代对象。
python 中 for 循环的 else 子句给我们提供了检测循环是否顺利执行完毕的一种优雅方法。
列表相关操作函数:
insert(位置下标,元素):插入元素 count(元素) 返回元素在列表中的出现次数 remove(元素)删除元素,或del list[i]
reverse()反转列表 extend(另一列表名)将一个列表的所有元素添加到另一个列表的末尾 sort()排序
append(元素)在末尾追加元素 pop(i)将第i个元素弹出--->pop()弹出栈顶元素,pop(0)弹出队头元素
列表推导式【用来简易构建for循环】
形式:[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
列表推导式由包含一个表达式的中括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句。
结果是一个列表,由表达式依据其后面的 for 和 if 子句上下文计算而来的结果构成。列表推导式也可以嵌套。
squares = list(map(lambda x: x**2, range(10))) 等价于 squares = [x**2 for x in range(10)]
lambda表达式【用来简易构建函数】
1、简单理解:
g = lambda x:x+1
g(1) >>>2
lambda作为一个表达式,定义了一个匿名函数,上例的代码x为入口参数,x+1为函数体,用函数来表示为:
1 def g(x):
2 return x+1
另一种使用方式:
lambda x:x+1(1) >>>2
# ###################### 普通函数 ###################### # 定义函数(普通方式) def func(arg): return arg + 1 # 执行函数 result = func(123) # ###################### lambda ###################### # 定义函数(lambda表达式) my_lambda = lambda arg : arg + 1 # 执行函数 result = my_lambda(123)
内置函数示例
一、map【映射】map(function, iterable, ...)
遍历序列,对序列中每个元素进行操作,最终获取新的序列。
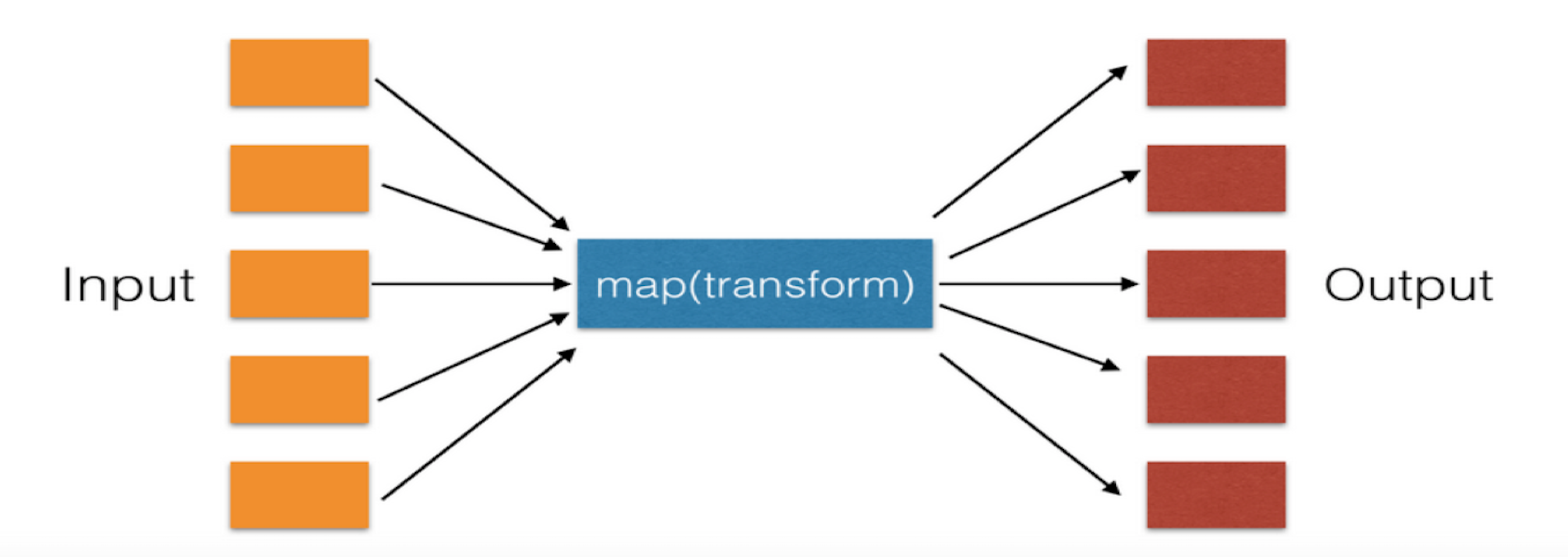
### li = [11, 22, 33] new_list = map(lambda a: a + 100, li) ### li = [11, 22, 33] sl = [1, 2, 3] new_list = map(lambda a, b: a + b, li, sl)
二、filter【过滤器】filter(function, iterable)
对于序列中的元素进行筛选,最终获取符合条件的序列

li = [11, 22, 33] new_list = filter(lambda arg: arg > 22, li) #filter第一个参数为空,将获取原来序列
Python3 divmod() 函数
Python divmod() 函数接收两个数字类型(非复数)参数,返回一个包含商和余数的元组(a // b, a % b)。
元组
元组是不可变类型,这意味着你不能在元组内删除或添加或编辑任何值。
要创建只含有一个元素的元组,在值后面跟一个逗号。
>>> a = (123) >>> a 123 >>> type(a) <class 'int'> >>> a = (123, ) >>> b = 321, >>> a (123,) >>> b (321,) >>> type(a) <class 'tuple'> >>> type(b) <class 'tuple'>
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
集合对象还支持 union(联合),intersection(交),difference(差)和 symmetric difference(对称差集)等数学运算。
大括号或 set() 函数可以用来创建集合。注意:想要创建空集合,你必须使用 set() 而不是 {}。后者用于创建空字典。
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 你可以看到重复的元素被去除
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket
True
>>> 'crabgrass' in basket
False
>>> # 演示对两个单词中的字母进行集合操作
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # a 去重后的字母
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # a 有而 b 没有的字母
{'r', 'd', 'b'}
>>> a | b # 存在于 a 或 b 的字母
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # a 和 b 都有的字母
{'a', 'c'}
>>> a ^ b # 存在于 a 或 b 但不同时存在的字母
{'r', 'd', 'b', 'm', 'z', 'l'}
###从集合中添加或弹出元素:
>>> a = {'a','e','h','g'}
>>> a.pop() # pop 方法随机删除一个元素并打印
'h'
>>> a.add('c')
>>> a
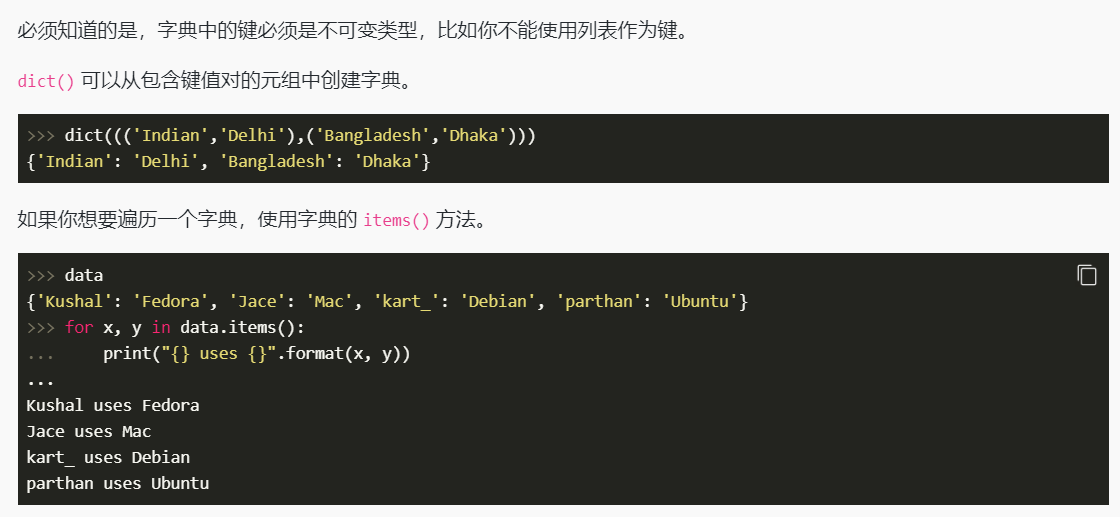
{'c', 'e', 'g', 'a'}字典


字符串
split() 允许有一个参数,用来指定字符串以什么字符分隔(默认为 " "),它返回一个包含所有分割后的字符串的列表。
方法 join() 使用指定字符连接多个字符串,它需要一个包含字符串元素的列表作为输入,然后连接列表内的字符串元素。



格式化操作符(%)
print("my name is %s.I am %d years old" % ('Shixiaolou',4))
%s 字符串(用 str() 函数进行字符串转换) %r 字符串(用 repr() 函数进行字符串转换)
%d 十进制整数 %f 浮点数 %% 字符“%”
函数
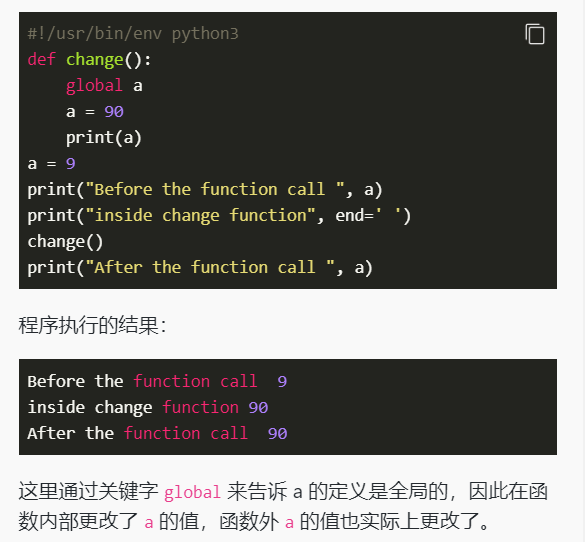
函数内使用global声明全局变量
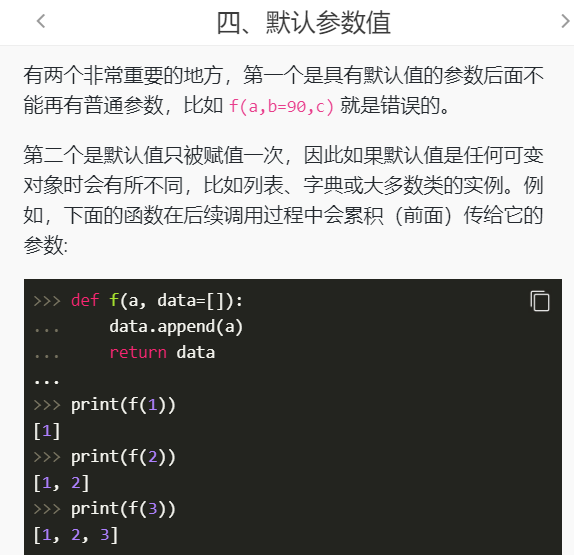
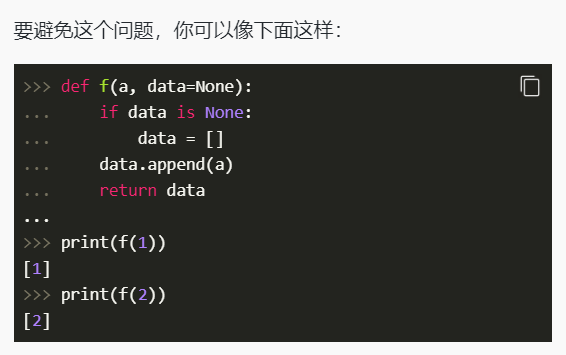

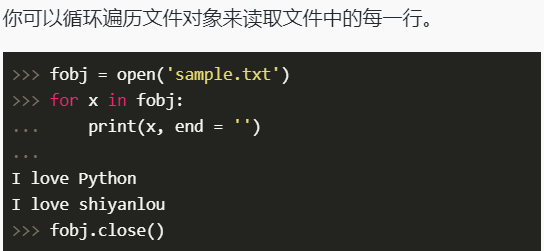
文件处理
使用 read() 方法一次性读取整个文件。 使用 read() 方法一次性读取整个文件。 使用 read() 方法一次性读取整个文件。
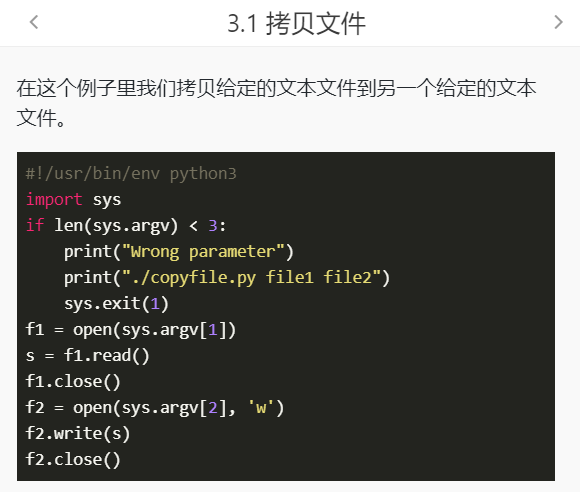
执行程序 空格隔开了这三个参数,sys.argv[0]==./copyfile.py sys.argv[1]==sample.txt sys.argv[2]==sample2.txt
![]()


getcwd() 函数返回当前工作目录。chdir(path) 则是更改当前目录到 path
if __name__ == '__main__': 这条语句,它的作用是,只有在当前模块名为 __main__ 的时候(即作为脚本执行的时候)才会执行此 if 块内的语句。换句话说,当此文件以模块的形式导入到其它文件中时,if 块内的语句并不会执行。
每层缩进使用4个空格。
续行与圆括号、中括号、花括号这样的被包裹元素保持垂直对齐






2.8.3.1 应该避免的名字
永远不要使用单个字符l(小写字母 el),O(大写字母 oh),或I(大写字母 eye)作为变量名。
在一些字体中,这些字符是无法和数字1和0区分开的。试图使用l时用L代替。
2.8.3.2 包和模块名
模块名应该短,且全小写。如果能改善可读性,可以使用下划线。Python 的包名也应该短,全部小写,但是不推荐使用下划线。
因为模块名就是文件名,而一些文件系统是大小写不敏感的,并且自动截断长文件名,所以给模块名取一个短小的名字是非常重要的 – 在 Unix 上这不是问题,但是把代码放到老版本的 Mac, Windows,或者 DOS 上就可能变成一个问题了。
用 C/C++ 给 Python 写一个高性能的扩展(e.g. more object oriented)接口的时候,C/C++ 模块名应该有一个前导下划线。
2.8.3.5 全局变量名
(我们希望这些变量仅仅在一个模块内部使用)这个约定有关诸如此类的变量。
若被设计的模块可以通过from M import *来使用,它应该使用__all__机制来表明那些可以可导出的全局变量,或者使用下划线前缀的全局变量表明其是模块私有的。
2.8.3.6 函数名
函数名应该是小写的,有必要的话用下划线来分隔单词提高可读性。
2.8.3.7 函数和方法参数
总是使用self作为实例方法的第一个参数。
总是使用cls作为类方法的第一个参数。
如果函数参数与保留关键字冲突,通常最好在参数后面添加一个尾随的下划线,而不是使用缩写或胡乱拆减。因此class_比clss要好。(或许避免冲突更好的方式是使用近义词)
2.8.3.8 方法名和实例变量
用函数名的命名规则:全部小写,用下划线分隔单词提高可读性。
用一个且有一个前导的下划线来表明非公有的方法和实例变量。
2.8.3.9 常量
常量通常是模块级的定义,全部大写,单词之间以下划线分隔。例如MAX_OVERFLOW和TOTAL。
为了更好的支持内省,模块应该用__all__属性来明确规定公有 API 的名字。设置__all__为空list表明模块没有公有 API。
甚至与__all__设置相当,内部接口(包、模块、类、函数、属性或者其它的名字)应该有一个前导的下划线前缀。
被认为是内部的接口,其包含的任何名称空间(包、模块或类)也被认为是内部的。
字符串拼接用在库中性能敏感的部分,用''.join形式来代替,而不是a += b。
比较单例,像None应该用is或is not,从不使用==操作符。
-
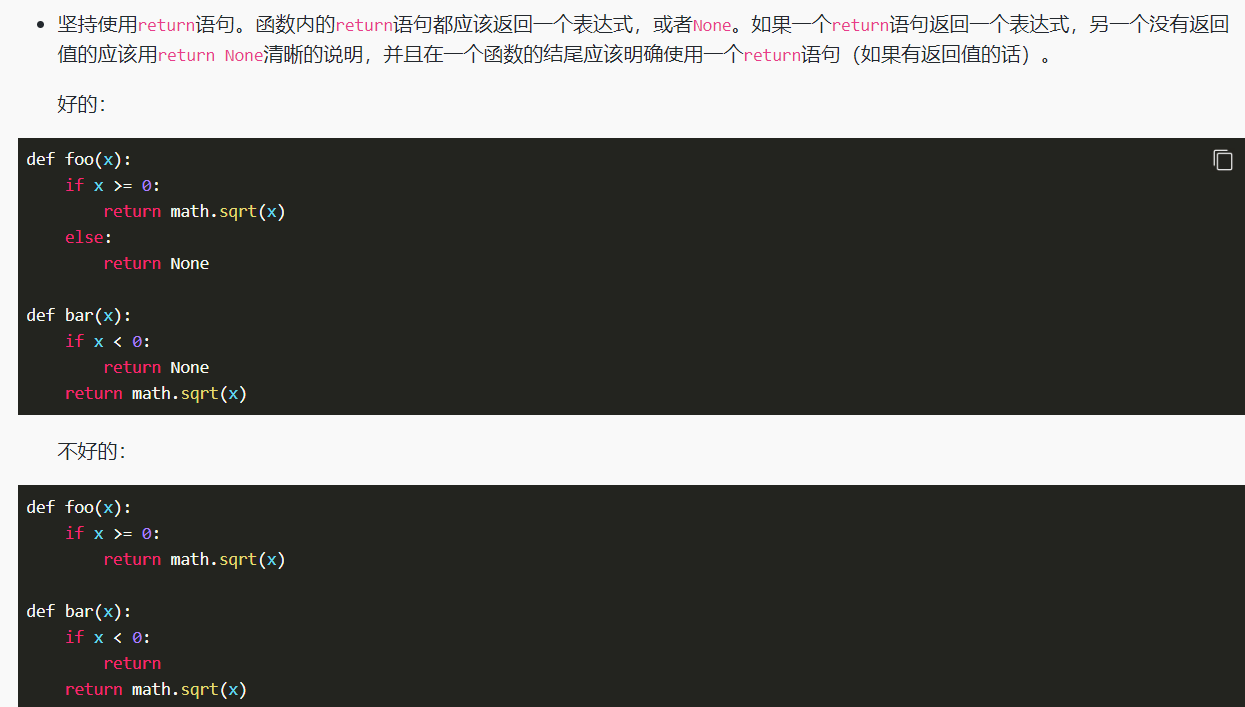
始终使用
def语句来代替直接绑定了一个lambda表达式的赋值语句。好的:
def f(x): return 2*x不好的:f = lambda x: 2
-
用
''.startswith()和''.endswith()代替字符串切片来检查前缀和后缀。startswith()和endswith()是更简洁的,不容易出错的。例如:
Yes: if foo.startswith('bar'):
No: if foo[:3] == 'bar':- 对象类型的比较应该始终使用
isinstance()而不是直接比较。
Yes: if isinstance(obj, int):
No: if type(obj) is type(1):
python中yield的用法详解——最简单,最清晰的解释
生成器表达式和列表推导式的区别:
1. 列表推导式比较耗内存. 一次性加载. 生成器表达式几乎不占用内存. 使用的时候才分配和使用内存
2. 得到的值不一样. 列表推导式得到的是一个列表. 生成器表达式获取的是一个生成器.
生成器的惰性机制: 生成器只有在访问的时候才取值. 说白了. 你找他要他才给你值. 不找他要. 他是不会执行的.
列表推导式: lst = [i for i in range(1, 15)] print(lst) 列表推导式的常用写法: [ 结果 for 变量 in 可迭代对象] 生成器表达式和列表推导式的语法基本上是一样的. 只是把[]替换成() gen = (i for i in range(10)) print(gen) 结果: <generator object <genexpr> at 0x106768f10>
yield和return的关系和区别“”带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。

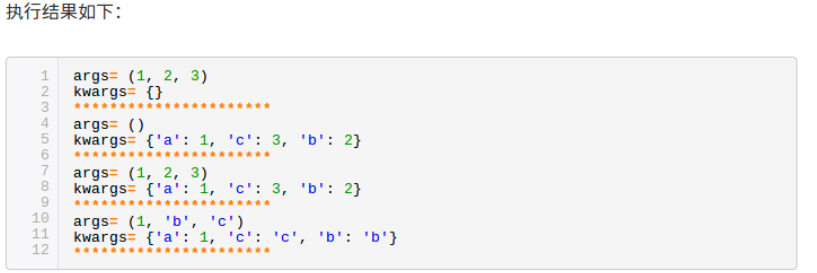
func(*args, **kwargs) *args, **kwargs表示函数的可变参数 *args 表示任何多个无名参数,它是一个tuple **kwargs 表示关键字参数,它是一个dict def foo(*args,**kwargs): print 'args=',args print 'kwargs=',kwargs print '**********************' if __name__=='__main__': foo(1,2,3) foo(a=1,b=2,c=3) foo(1,2,3,a=1,b=2,c=3) foo(1,'b','c',a=1,b='b',c='c')

你还记得我们经常使用的 pip 命令吗?有没有想过这些包是从哪里来的?答案是 PyPI。这是 Python 的软件包管理系统。
为了实验,我们会使用 PyPI 的测试服务器 https://testpypi.python.org/pypi。
2.4.1 创建账号
首先在这个链接注册账号。你会收到带有链接的邮件,点击这个链接确认你的注册。
创建 ~/.pypirc 文件,存放你的账号详细信息,其内容格式如下:
[distutils]
index-servers = pypi
testpypi
[pypi]
repository: https://upload.pypi.org/legacy/
username: <username>
password: <password>
[testpypi]
repository:https://test.pypi.org/legacy/
username: <username>
password: <password>
替换 <username> 和 <password> 为您新创建的帐户的详细信息。在这里,由于我们是到 testpypi的网页上去注册账号,即将相应的服务上传到 testpypi,所以在这里,你只需修改[testpypi]的用户名和密码
记得在 setup.py 中更改项目的名称为其它的名字来测试下面的指令,在接下来的命令中我将项目名称修改为factorial2,为了不重复,大家需要自行修改至其它名称(不要使用 factorial 和 factorial2,因为已经被使用了)。
2.4.2 上传到 TestPyPI 服务
下一步我们会将我们的项目到 TestPyPI 服务。这通过 twine 命令完成。
我们也会使用 -r 把它指向测试服务器。
$ sudo pip3 install twine
$ twine upload dist/* -r testpypi执行完毕会返回类似下面的信息:
Uploading distributions to https://test.pypi.org/legacy/
Uploading factorial2-0.1.tar.gz现在如果你浏览这个页面,你会发现你的项目已经准备好被别人使用了。
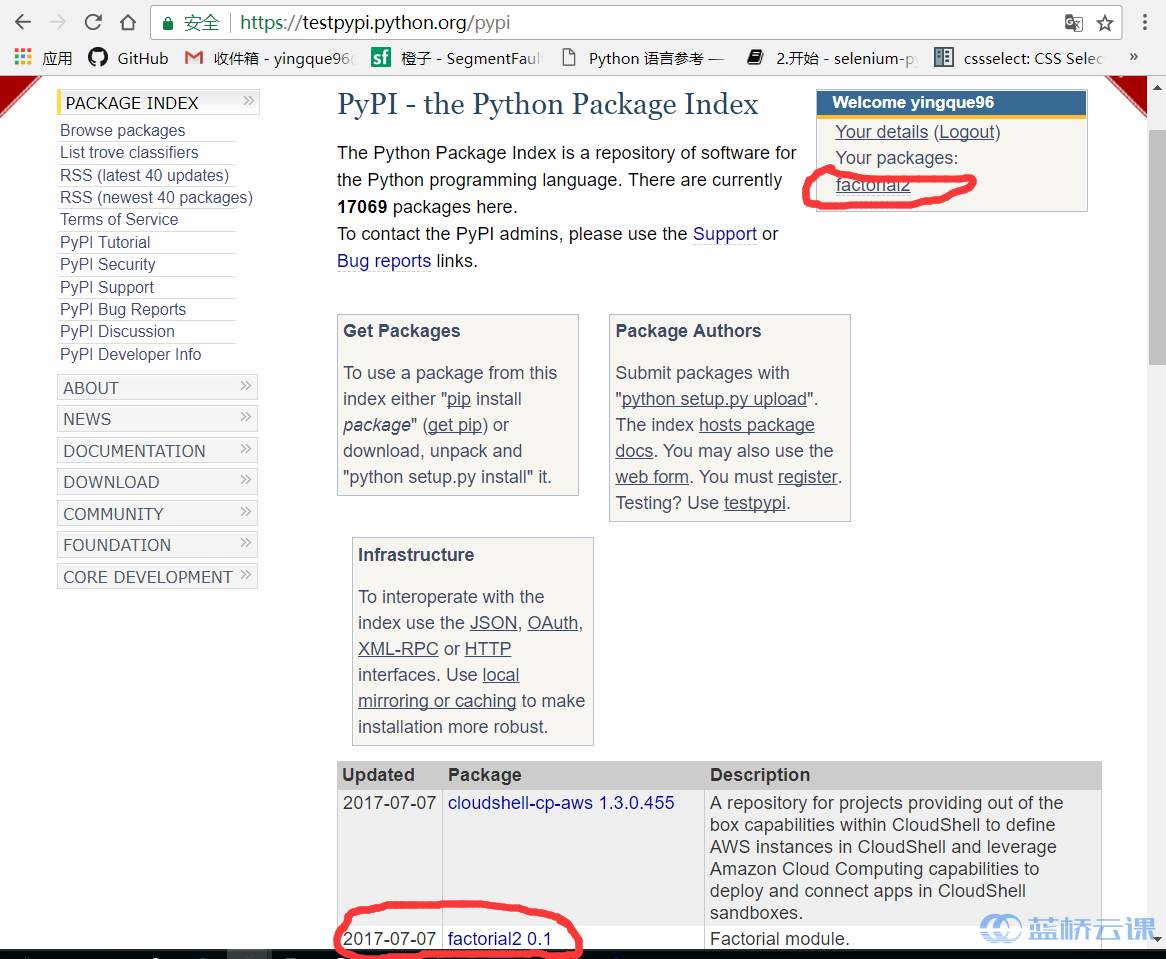
在这里你也可以使用下面的命令上传到 PyPI 服务上,但这里需要注意,在 ~/.pypirc 里面,你需要到 https://pypi.python.org页面,按照上面的步骤去注册一个账号,然后到~/.pypirc 的 [pypi] 下填写相应的用户名和密码。testpypi 和 pypi 的账号密码并不通用。
$ twine upload dist/* -r pypi