假设有一个表:reward(奖励表),表结构如下:
CREATE TABLE test.reward ( id int(11) NOT NULL AUTO_INCREMENT, uid int(11) NOT NULL COMMENT '用户uid', money decimal(10, 2) NOT NULL COMMENT '奖励金额', datatime datetime NOT NULL COMMENT '时间', PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT = '奖励表';
表中数据如下:
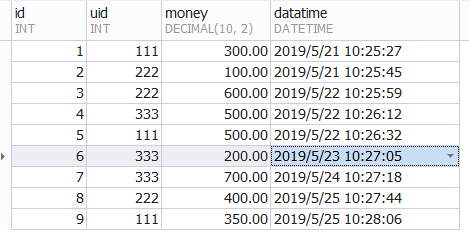
现在需要查询每个人领取的最高奖励并且从大到小排序:
如果直接查询:
SELECT id, uid, money, datatime FROM reward GROUP BY uid ORDER BY money DESC;
得到如下结果:
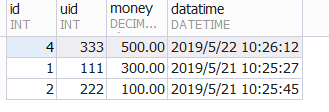
没有得到我们需要的结果,这是因为group by 和 order by 一起使用时,会先使用group by 分组,并取出分组后的第一条数据,所以后面的order by 排序时根据取出来的第一条数据来排序的,但是第一条数据不一定是分组里面的最大数据。
方法一:
既然这样我们可以先排序,在分组,使用子查询。
SELECT r.id, r.uid, r.money, r.datatime FROM (SELECT id, uid, money, datatime FROM reward ORDER BY money DESC) r GROUP BY r.uid ORDER BY r.money DESC;
得到正确结果:

方法二:
如果不需要取得整条记录,则可以使用 max()
SELECT id, uid, money, datatime, MAX(money) FROM reward GROUP BY uid ORDER BY MAX(money) DESC;
得到结果:

可能你已经发现了,使用max()取得的记录,money字段和max(money)字段不一致,这是因为这里只是取出了该uid的最大值,但是该最大值对应的整条记录没有取出来。
如果需要取得整条记录,则不能使用这种方法,可以使用子查询。