

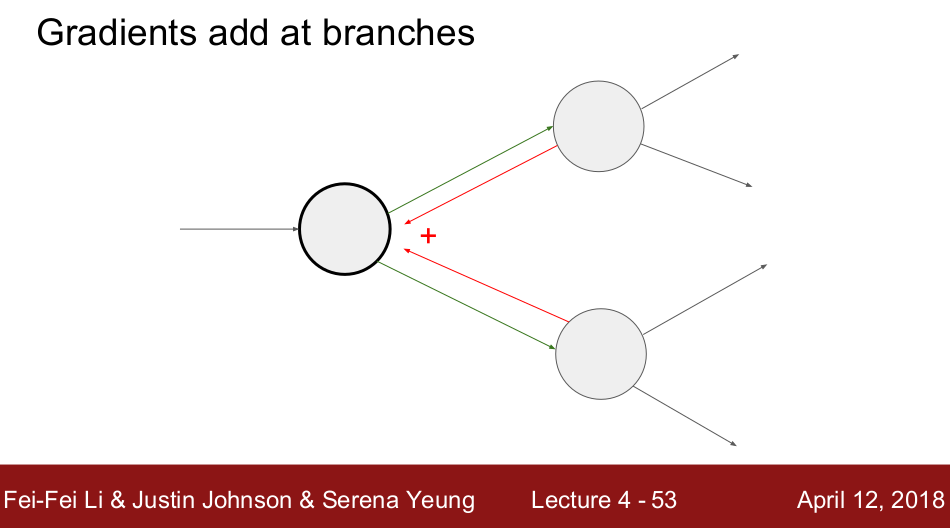
Gradients add up at forks. If a variable branches out to different parts of the circuit, then the gradients that flow back to it will add.
Example:

There are 3 paths from x to f, and 2 paths from y to f.
As for the fork of x, it braches out 3 paths and converges at f, when computing df/dx, the 3 gradients flowing back should be sumed up.
As for the fork of y, it braches out 2 paths and converges at f, when computing df/dy, the 2 gradients flowing back should be sumed up.
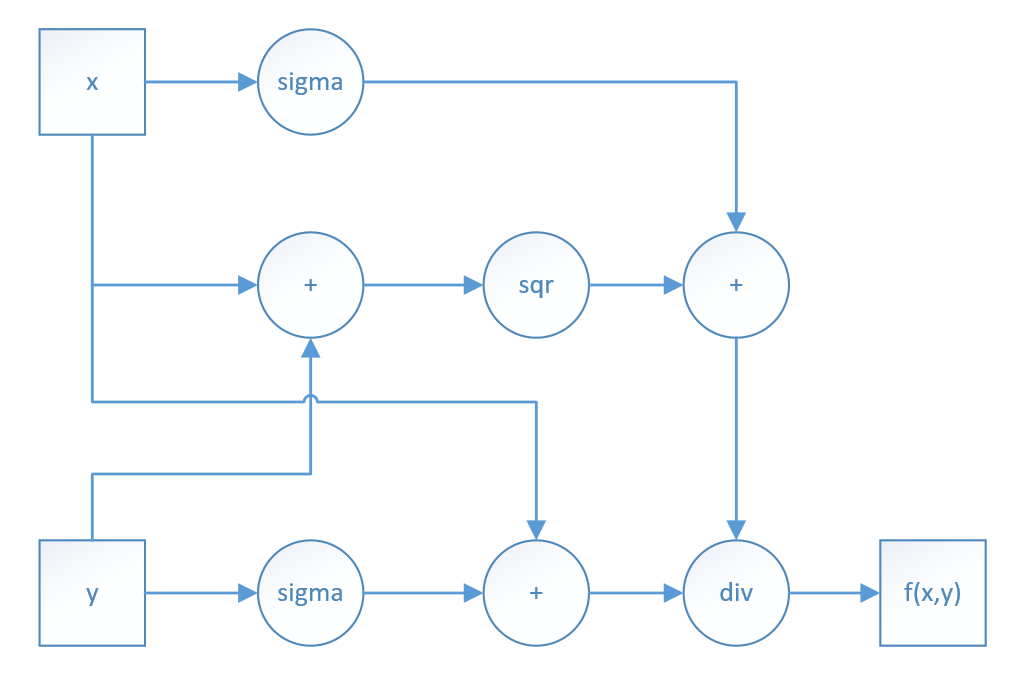
forward pass:

backward pass:

The size of the mini-batch is a hyperparameter but it is not very common to cross-validate it. It is usually based on memory constraints (if any), or set to some value, e.g. 32, 64 or 128. We use powers of 2 in practice because many vectorized operation implementations work faster when their inputs are sized in powers of 2.
Reference:
1.http://cs231n.github.io/optimization-2/
2.https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b