1、模块
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
作用
如果退出python解释器然后重新进入,那么之前定义的函数或者变量都将丢失,因此通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,或者把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
1.1 import 语句
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入,如果不在当前路径就会按照系统环境变量导入
语法
import name1,name2
别名
impor name1 as name2
提示
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句)
1.2 From…import 语句
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。
语法
from modname import name1[, name2[, ... nameN]]
把一个模块的所有内容全都导入到当前的命名空间也是可行的
from modname import *
别名
from modname import name1 as name2
1.3 标准模块
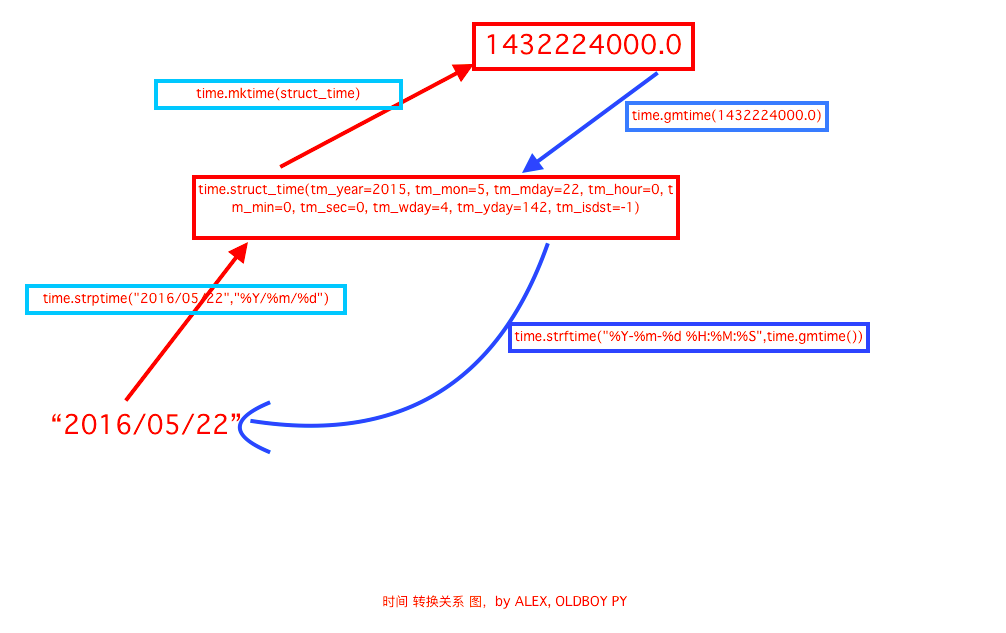
time datetime 模块
print(time.time())#作为时间戳使用,是计算机 Unix 诞生的时间(1970)
print(time.altzone)#返回与utc时间的时间差,以秒计算
print(time.asctime())#返回时间格式"Sat Feb 18 15:15:03 2017"
print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
print(time.localtime()) #返回本地时间 的struct time对象格式
print(time.gmtime())#返回utc的时间
print(time.strftime('%Y-%m-%d %H:%M:%S'))#自定义格式,2017-02-18 15:26:29
print(time.strptime('2017-02-18 15:26:29','%Y-%m-%d %H:%M:%S'))#将固定格式转换为时间对象
print(time.localtime(time.time()))#时间戳到时间对象的转换
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))#时间戳到自定义时间格式转换
print(time.strptime('2017-02-18 15:43:11','%Y-%m-%d %H:%M:%S'))#自定义时间到时间对象的装换
print(time.mktime(time.strptime('2017-02-18 15:43:11','%Y-%m-%d %H:%M:%S')))#自定义时间到时间戳的转换
print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
#时间替换
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2))
random 模块
- random.random() 用于生成一个0到1的随机符点数: 0 <= n < 1.0
- random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
- random.randrange([start], stop[, step])从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数。random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。
- random.choice(sequence) 从序列中获取一个随机元素。参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence
print(random.choice([1,'23',[4,5],'bac'])) - **random.sample(sequence, k) **从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列
- **random.uniform(a, b) **用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a <b, 则 b <= n <= a。
- random.shuffle(x[, random]) 用于将一个列表中的元素打乱。
os 模块
**os.getcwd() **获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
**os.makedirs('dirname1/dirname2') **可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
**os.mkdir('dirname') ** 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
**os.rename("oldname","newname") ** 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
**os.name ** 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
**os.system("bash command") ** 运行shell命令,直接显示,返回命令结果的执行状态
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
**os.path.basename(path) **返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
**os.path.exists(path) **如果path存在,返回True;如果path不存在,返回False
**os.path.isabs(path) **如果path是绝对路径,返回True
**os.path.isfile(path) **如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.normpath(path) 规范化路径,转换path的大小写和斜杠
sys 模块
- sys.argv 命令行参数List,第一个元素是程序本身路径
- sys.exit(n) 退出程序,正常退出时exit(0)
- sys.version 获取Python解释程序的版本信息
- sys.maxint 最大的Int值
- sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- sys.platform 返回操作系统平台名称
pickle、json模块
用于序列化的两个模块:
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:序列化(dumps、dump)、反序列化(loads、load)
pickle模块提供了四个功能:序列化(dumps、dump)、反序列化(loads、load)
序列化:内存存储方式转换为字符串
反序列化:字符串转换为内存存储方式
json 与 pickle功能完全相同,只是 json 只支持少量字符串格式,如:str、int、float、set、dict、list、tuple
import pickle
date = {
'id': 6452523,
'credit':15000,
'balance':8000,
'passwd':'asasda'
}
with open('account','wb') as df:
df.write(pickle.dumps(date))
with open('account','rb') as df:
print(pickle.loads(df.read()))
shutil 模块
shutil.copyfileobj(fsrc, fdst[, length])将文件内容拷贝到另一个文件中,可以限制长度分次导入
shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
f = shelve.open('logging')
f['name']=['a','b','c']
tmpe = f['name']#只能通过这样的方式添加
tmpe.append('d')
f['name'] = tmpe
print(f)
f.close()
xml 模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")#parse 是解析的意思
root = tree.getroot()#根节点
print(root.tag)
#遍历xml文档,直接用循环嵌套就行tag是标记,text是数据,attrib是属性
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点,直接搜关键字即可
for node in root.iter('year'):
print(node.tag,node.text)
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#新建xml
new_xml = ET.Element("namelist")#根节点
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)#第一行声明
ET.dump(new_xml) #打印生成的格式
configparser 模块
在 python 2.x 版本中 configparser 需要大写
#创建ConfigParser实例
config=ConfigParser.ConfigParser()
#读取模块信息,不会显示默认模块
config.sections()
#读取模块下的参数,如果有 default 默认模块也会显示
config.options('section')
#返回section 模块下,option 参数的值
config.get(section,option)
#返回section 模块下,option 参数的键和值
config.itens('section')
#添加一个配置文件节点(str)
config.add_section(str)
#设置section节点中,键名为option的值(val) config.set(section,option,val)
#读取文件
config.read(filename)
#写入配置文件
config.write(obj_file)
#删除某个模块或该模块的某个键
config.remove_option('section','option')
生成文件
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
#生成如下格式
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
修改已有的文件
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()#查看配置文件中有哪些模块,因为没指定文件,所以是空的
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()#此时有了,默认的模块没有显示
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config#判断是相应模块是否存在
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']#查看参数
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
'50022'
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
hashlib 模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5()
m.update(b'hello')
print(m.hexdigest())
m.update(b'my name is')
print(m.hexdigest())
m2 = hashlib.md5()
m2.update(b'hellomy name is')
print(m2.hexdigest())#16进制
print(m2.digest())#二进制
#输出结果
5d41402abc4b2a76b9719d911017c592
144e390a38d33b5257b20558ac017ad1
144e390a38d33b5257b20558ac017ad1
b'x14N9
8xd3;RWxb2x05Xxacx01zxd1'
#因为 m 的两次结果是叠加的,就相当于 m2
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
subprocess 模块
每次调用该模块就相当于启动新的进程
>>> retcode = subprocess.call("ls -l",shell=Ture)
#执行命令,打印命令结果
#执行命令,返回命令执行状态 , 0 or 非0
>>> retcode = subprocess.call(["ls", "-l"])
#执行命令,如果命令结果为0,就正常返回,否则抛异常
>>> subprocess.check_call(["ls", "-l"])
0
#接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
>>> subprocess.getstatusoutput('ls /bin/ls')
(0, '/bin/ls')
#接收字符串格式命令,并返回结果
>>> subprocess.getoutput('ls /bin/ls')
'/bin/ls'
#执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
>>> res=subprocess.check_output(['ls','-l'])
>>> res
b'total 0
drwxr-xr-x 12 alex staff 408 Nov 2 11:05 OldBoyCRM
'
#上面那些方法,底层都是封装的subprocess.Popen
poll()当子进程执行完后等到结果状态
wait()等待子进程结果状态
terminate() 杀掉所启动进程
communicate() 等待任务结束
stdin 标准输入
stdout 标准输出
stderr 标准错误
pid
The process ID of the child process.
#例子
>>> p = subprocess.Popen("df -h|grep disk",stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
>>> p.stdout.read()
b'/dev/disk1 465Gi 64Gi 400Gi 14% 16901472 104938142 14% /
'
re 模块
正则表达式模块
常用符号
'.' 默认匹配除
之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","
abc
eee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo
sdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'A' 只从字符开头匹配,re.search("Aabc","alexabc") 是匹配不到的
'' 匹配字符结尾,同$
'd' 匹配数字0-9
'D' 匹配非数字
'w' 匹配[A-Za-z0-9]
'W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、 、
、
, re.search("s+","ab c1
3").group() 结果 ' '
常用匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r""表示。同样,匹配一个数字的"d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观
2、包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的Python的应用环境。
2.1 注意事项
- 关于包相关的导入语句也分为 import 和 from ... import ... 两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如 item.subitem.subsubitem ,但都必须遵循这个原则。
- 对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。