表述类目的变量通常,通常没有次序概念,且取值范围有限。例如性别行业信用卡类型。有些模型可以直接读类别变量(例如决策树)。有些模型不能识别类别变量(例如回归模型,神经网络,有距离的度量模型(svn,knn))。
当类别变量无法放入模型的时候,需要做编码处理即以数值的形式替代原有的值:
- onehot编码
- dummy
- 浓度编码
- WOE编码
我们主要用onehot编码,dummy(哑变量)操作,通常会使得我们模型具有较强的非线性能力。
那么这两种编码方式是如何进行的呢?
它们之间是否有联系?
又有什么样的区别?
是如何提升模型的非线性能力的呢?
我们带着这三个疑问进入特殊变量的主题:
1.为什么
这一个迷你数据集,为什么我们用1,2,3,4这样的数据值不行呢,非要用00001,01000这样的才可以?即为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
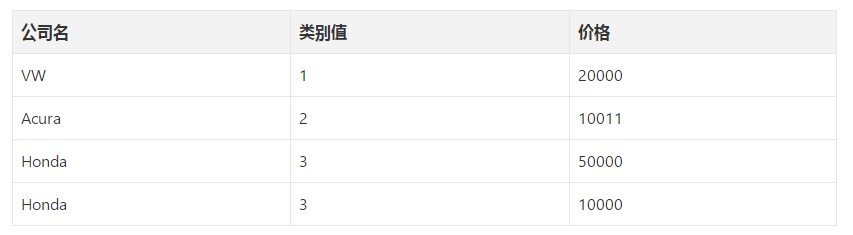
标签编码的问题是它假定类别值越高,该类别更好。
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。
比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2.
这意味着:VW和Honda平均一下是Acura。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
如果原本的标签编码是有序的,那one hot编码就不合适了——会丢失顺序信息。
转化成二进制编码(如下图所示):

2.怎么用
我们先不讲各种编码之间的差别,先讲一个案例Demo,什么编码转化。
import pandas pd df = pd.DataFrame({'country': ['russia', 'germany', 'australia','korea','germany']}) pd.get_dummies(df,prefix=['country'])

一些机器学习技术要求,从表示中删除一个维度,以避免变量之间的依赖性。使用“drop_first = True”来实现这一目标。
import pandas as pd # using the same example as above df = pd.DataFrame({'country': ['russia', 'germany', 'australia','korea','germany']}) pd.get_dummies(df,prefix=['country'], drop_first=True)
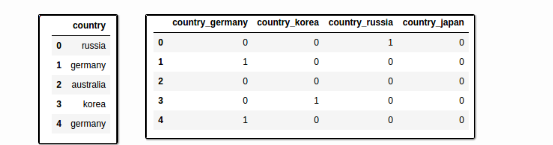
同时你也要修改测试集上的数据。要和训练集保持一致才能测试的时候用。
import pandas as pd # say you want a column for "japan" too (it'll be always zero, of course) df["country"] = train_df["country"].astype('category',categories=["australia","germany","korea","russia","japan"]) # now call .get_dummies() as usual pd.get_dummies(df,prefix=['country'])
然后我们重新关注一下训练集,我们剔除原来那一列被编码的特征同时,把编码特征concat回去。
df = pd.concat([df,pd.get_dummies(df['mycol'], prefix='mycol',dummy_na=True)],axis=1).drop(['mycol'],axis=1)
import pandas as pd # df now has two columns: name and country df = pd.DataFrame({ 'name': ['josef','michael','john','bawool','klaus'], 'country': ['russia', 'germany', 'australia','korea','germany'] }) # use pd.concat to join the new columns with your original dataframe df = pd.concat([df,pd.get_dummies(df['country'], prefix='country')],axis=1) # now drop the original 'country' column (you don't need it anymore) df.drop(['country'],axis=1, inplace=True)

同时我们也可以把数据缺失也作为一种特征
import pandas as pd import numpy as np df = pd.DataFrame({ 'country': ['germany',np.nan,'germany','united kingdom','america','united kingdom'] }) pd.get_dummies(df,dummy_na=True)

3.whatone-hot encoding
接下来我们详细的讲一下onehot编码和dummy之间的区别。
二者都可以对Categorical Variable做处理,转换为定量特征,转换为定量特征其实就是将原来每个特征的类别拿出来作为一个新的特征(Dummy Variable)了,
如性别——男,女,定量特征即将男作为一个特征,女作为一个特征,如果数据中的Categorical Variable很多,且每个Variable种类比较多,那么转换后的数据可能会非常稀疏。
二者本身存在差别。
Difference:一个定性特征或者成为Categorical Variable,其有n个值,
Dummy Encoding 会将这个Categorical Variable转换为n-1个特征变量,而OneHot Encoding会转换为n个特征变量。
其中,这种转换在经济学或者回归模型中会存在一个Dummy Variable Trap的问题,使用Dummy Encoder可以避免这个问题,由于我这里面对的是分类问题,没有过多的调研。
如果你还不理解我借鉴一下某个博客的例子
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,
也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

dummy encoding
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士。所以,我们用哑变量编码可以将上述5类表示成:

哑变量编码去除了one-hot编码内部线性相关的一个。这种简化不能说到底好不好,这要看使用的场景。下面我们以一个例子来说明:
假设我们现在获得了一个模型![]() ,这里自变量满足
,这里自变量满足![]()
(因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),
故我们可以用![]() 表示第三个特征,将其带入模型中,得到:
表示第三个特征,将其带入模型中,得到:
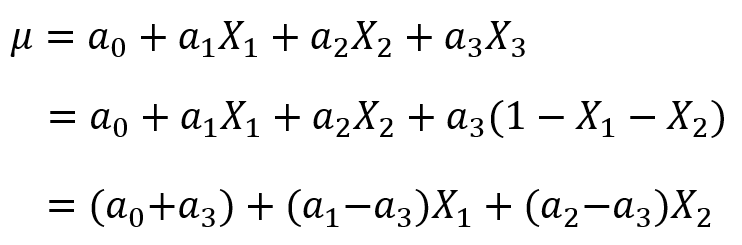
这时,我们就惊奇的发现![]() 和
和![]() 这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
(1)使用![]() 正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
(2)把偏置项![]() 去掉,这时我们发现也可以解决同一个模型参数等价的问题。
去掉,这时我们发现也可以解决同一个模型参数等价的问题。
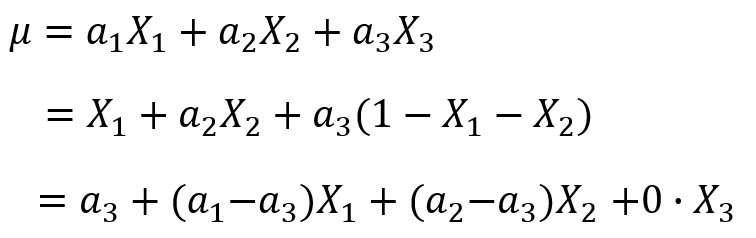
因为有了bias项,所以和我们去掉bias项的模型是完全不同的模型,不存在参数等价的问题。
(3)再加上bias项的前提下,使用哑变量编码代替one-hot编码,这时去除了![]() ,也就不存在之前一种特征可以用其他特征表示的问题了。
,也就不存在之前一种特征可以用其他特征表示的问题了。
总结:我们使用one-hot编码时,通常我们的模型不加bias项 或者 加上bias项然后使用![]() 正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
选择建议:最好是选择正则化 + one-hot编码;哑变量编码也可以使用,不过最好选择前者。虽然哑变量可以去除one-hot编码的冗余信息,但是因为每个离散型特征各个取值的地位都是对等的,随意取舍未免来的太随意。
连续值的离散化为什么会提升模型的非线性能力?
简单的说,使用连续变量的LR模型,模型表示为公式(1),而使用了one-hot或哑变量编码后的模型表示为公式(2)
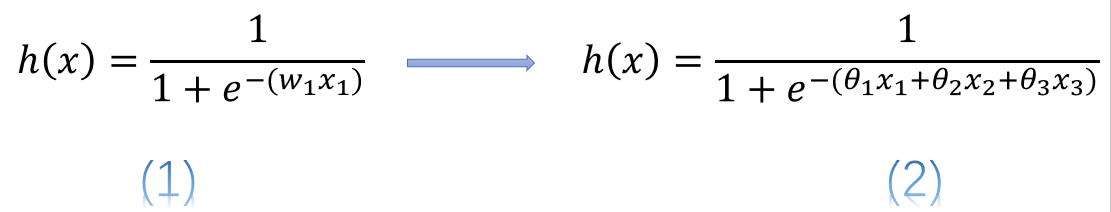
式中![]() 表示连续型特征,
表示连续型特征,![]() 、
、![]() 、
、![]() 分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
这样做除了增强了模型的非线性能力外,还有什么好处呢?这样做了我们至少不用再去对变量进行归一化,也可以加速参数的更新速度;再者使得一个很大权值管理一个特征,拆分成了许多小的权值管理这个特征多个表示,这样做降低了特征值扰动对模型为稳定性影响,也降低了异常数据对模型的影响,进而使得模型具有更好的鲁棒性。