1.定义
分箱就是将连续变量离散化,将多状态的离散变量合并成少状态。
2.分箱的用处
离散特征的增加和减少都很容易,易于模型的快速迭代;
稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
列表内容离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
列表内容逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
列表内容特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间
是门学问;
特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。 可以将缺失作为独立的一类带入模型。
将所有变量变换到相似的尺度上。
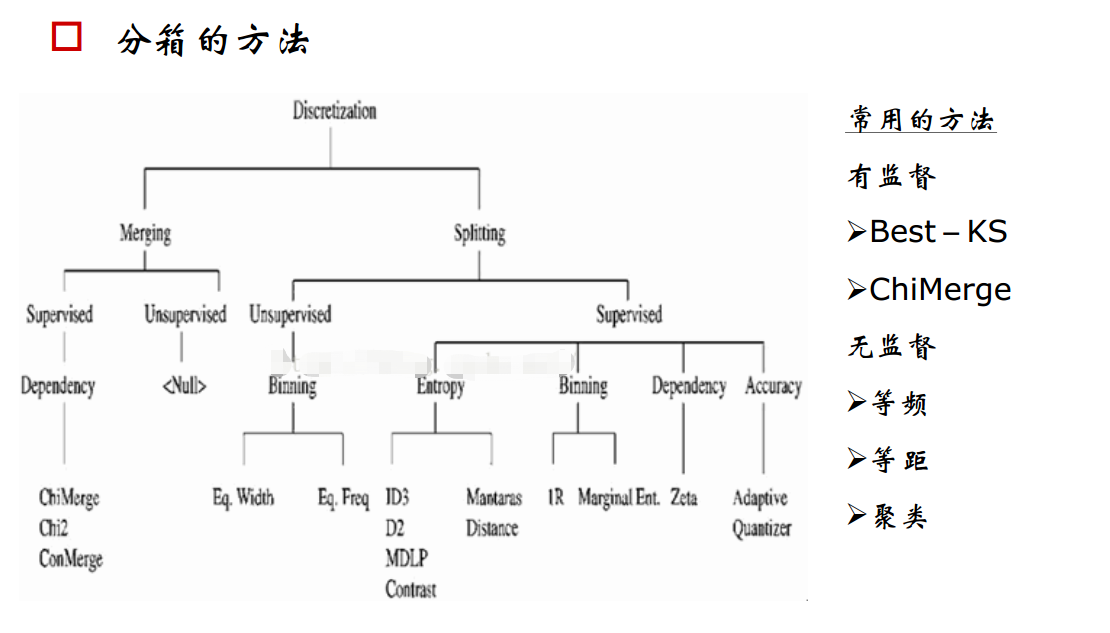
3.分箱方法
分箱方法分为无监督分箱和有监督分箱。
1)常用的无监督分箱方法有等频分箱,等距分箱和聚类分箱。
2)有监督分箱主要有best-ks分箱和卡方分箱。基于我的项目中重点应用了卡方分箱,所以这里重点对卡方分箱做些总结。
4.卡方分箱的原理
卡方分箱是自底向上的(即基于合并的)数据离散化方法。
它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想:对于精确的离散化,相对类频率在一个区间内应当完全一致。
因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;
否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
分箱步骤:

这里需要注意初始化时需要对实例进行排序,在排序的基础上进行合并。
卡方阈值的确定:
根据显著性水平和自由度得到卡方值
自由度比类别数量小1。例如:有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
阈值的意义
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。
大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
注:
1,ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间.
2,也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。指定区间数量的上限和下限,最多几个区间,最少几个区间。
3,对于类别型变量,需要分箱时需要按照某种方式进行排序。
5.分完箱之后评估指标
分为箱之后,需要评估。在积分卡模型中,最常用的评估手段是计算出WOE和IV值。
https://www.cnblogs.com/wqbin/p/10547628.html
6.分箱


def Chi2(df, total_col, bad_col,overallRate): ''' #此函数计算卡方值 :df dataFrame :total_col 每个值得总数量 :bad_col 每个值的坏数据数量 :overallRate 坏数据的占比 : return 卡方值 ''' df2=df.copy() df2['expected']=df[total_col].apply(lambda x: x*overallRate) combined=list(zip(df2['expected'], df2[bad_col])) chi=[(i[0]-i[1])**2/i[0] for i in combined] chi2=sum(chi) return chi2 #基于卡方阈值卡方分箱,有个缺点,不好控制分箱个数。 def ChiMerge_MinChisq(df, col, target, confidenceVal=3.841): ''' #此函数是以卡方阈值作为终止条件进行分箱 : df dataFrame : col 被分箱的特征 : target 目标值,是0,1格式 : confidenceVal 阈值,自由度为1, 自信度为0.95时,卡方阈值为3.841 : return 分箱。 这里有个问题,卡方分箱对分箱的数量没有限制,这样子会导致最后分箱的结果是分箱太细。 ''' #对待分箱特征值进行去重 colLevels=set(df[col]) #count是求得数据条数 total=df.groupby([col])[target].count() total=pd.DataFrame({'total':total}) #sum是求得特征值的和 #注意这里的target必须是0,1。要不然这样求bad的数据条数,就没有意义,并且bad是1,good是0。 bad=df.groupby([col])[target].sum() bad=pd.DataFrame({'bad':bad}) #对数据进行合并,求出col,每个值的出现次数(total,bad) regroup=total.merge(bad, left_index=True, right_index=True, how='left') regroup.reset_index(level=0, inplace=True) #求出整的数据条数 N=sum(regroup['total']) #求出黑名单的数据条数 B=sum(regroup['bad']) overallRate=B*1.0/N #对待分箱的特征值进行排序 colLevels=sorted(list(colLevels)) groupIntervals=[[i] for i in colLevels] groupNum=len(groupIntervals) while(1): if len(groupIntervals) == 1: break chisqList=[] for interval in groupIntervals: df2=regroup.loc[regroup[col].isin(interval)] chisq=Chi2(df2, 'total', 'bad', overallRate) chisqList.append(chisq) min_position=chisqList.index(min(chisqList)) if min(chisqList) >= confidenceVal: break if min_position==0: combinedPosition=1 elif min_position== groupNum-1: combinedPosition=min_position-1 else: if chisqList[min_position-1]<=chisqList[min_position + 1]: combinedPosition=min_position-1 else: combinedPosition=min_position+1 groupIntervals[min_position]=groupIntervals[min_position]+groupIntervals[combinedPosition] groupIntervals.remove(groupIntervals[combinedPosition]) groupNum=len(groupIntervals) return groupIntervals #最大分箱数分箱 def ChiMerge_MaxInterval_Original(df, col, target,max_interval=5): ''' : df dataframe : col 要被分项的特征 : target 目标值 0,1 值 : max_interval 最大箱数 :return 箱体 ''' colLevels=set(df[col]) colLevels=sorted(list(colLevels)) N_distinct=len(colLevels) if N_distinct <= max_interval: print("the row is cann't be less than interval numbers") return colLevels[:-1] else: total=df.groupby([col])[target].count() total=pd.DataFrame({'total':total}) bad=df.groupby([col])[target].sum() bad=pd.DataFrame({'bad':bad}) regroup=total.merge(bad, left_index=True, right_index=True, how='left') regroup.reset_index(level=0, inplace=True) N=sum(regroup['total']) B=sum(regroup['bad']) overallRate=B*1.0/N groupIntervals=[[i] for i in colLevels] groupNum=len(groupIntervals) while(len(groupIntervals)>max_interval): chisqList=[] for interval in groupIntervals: df2=regroup.loc[regroup[col].isin(interval)] chisq=Chi2(df2,'total','bad',overallRate) chisqList.append(chisq) min_position=chisqList.index(min(chisqList)) if min_position==0: combinedPosition=1 elif min_position==groupNum-1: combinedPosition=min_position-1 else: if chisqList[min_position-1]<=chisqList[min_position + 1]: combinedPosition=min_position-1 else: combinedPosition=min_position+1 #合并箱体 groupIntervals[min_position]=groupIntervals[min_position]+groupIntervals[combinedPosition] groupIntervals.remove(groupIntervals[combinedPosition]) groupNum=len(groupIntervals) groupIntervals=[sorted(i) for i in groupIntervals] print(groupIntervals) cutOffPoints=[i[-1] for i in groupIntervals[:-1]] return cutOffPoints #计算WOE和IV值 def CalcWOE(df,col, target): ''' : df dataframe : col 注意这列已经分过箱了,现在计算每箱的WOE和总的IV :target 目标列 0-1值 :return 返回每箱的WOE和总的IV ''' total=df.groupby([col])[target].count() total=pd.DataFrame({'total':total}) bad=df.groupby([col])[target].sum() bad=pd.DataFrame({'bad':bad}) regroup=total.merge(bad, left_index=True, right_index=True, how='left') regroup.reset_index(level=0, inplace=True) N=sum(regroup['total']) B=sum(regroup['bad']) regroup['good']=regroup['total']-regroup['bad'] G=N-B regroup['bad_pcnt']=regroup['bad'].map(lambda x: x*1.0/B) regroup['good_pcnt']=regroup['good'].map(lambda x: x*1.0/G) regroup['WOE']=regroup.apply(lambda x: np.log(x.good_pcnt*1.0/x.bad_pcnt),axis=1) WOE_dict=regroup[[col,'WOE']].set_index(col).to_dict(orient='index') IV=regroup.apply(lambda x:(x.good_pcnt-x.bad_pcnt)*np.log(x.good_pcnt*1.0/x.bad_pcnt),axis=1) IV_SUM=sum(IV) return {'WOE':WOE_dict,'IV_sum':IV_SUM,'IV':IV} #分箱以后检查每箱的bad_rate的单调性,如果不满足,那么继续进行相邻的两项合并,直到bad_rate单调为止 def BadRateMonotone(df, sortByVar, target): #df[sortByVar]这列已经经过分箱 df2=df.sort_values(by=[sortByVar]) total=df2.groupby([sortByVar])[target].count() total=pd.DataFrame({'total':total}) bad=df2.groupby([sortByVar])[target].sum() bad=pd.DataFrame({'bad':bad}) regroup=total.merge(bad, left_index=True, right_index=True, how='left') regroup.reset_index(level=0, inplace=True) combined=list(zip(regroup['total'], regroup['bad'])) badRate=[x[1]*1.0/x[0] for x in combined] badRateMonotone=[badRate[i]<badRate[i+1] for i in range(len(badRate)-1)] Monotone = len(set(badRateMonotone)) if Monotone==1: return True else: return False #检查最大箱,如果最大箱里面数据数量占总数据的90%以上,那么弃用这个变量 def MaximumBinPcnt(df, col): N=df.shape[0] total=df.groupby([col])[col].count() pcnt=total*1.0/N return max(pcnt) #对于类别型数据,以bad_rate代替原有值,转化成连续变量再进行分箱计算。比如我们这里的户籍地代码,就是这种数据格式 #当然如果类别较少时,原则上不需要分箱 def BadRateEncoding(df, col, target): ''' : df DataFrame : col 需要编码成bad rate的特征列 :target值,0-1值 : return: the assigned bad rate ''' total=df.groupby([col])[target].count() total=pd.DataFrame({'total':total}) bad=df.groupby([col])[target].sum() bad=pd.DataFrame({'bad':bad}) regroup=total.merge(bad, left_index=True, right_index=True, how='left') regroup.reset_index(level=0, inplace=True) regroup['bad_rate']=regroup.apply(lambda x: x.bad*1.0/x.total, axis=1) br_dict=regroup[[col,'bad_rate']].set_index([col]).to_dict(orient='index') badRateEnconding=df[col].map(lambda x: br_dict[x]['bad_rate']) return {'encoding':badRateEnconding,'br_rate':br_dict}
7.自动化分箱
在工程中,考虑到能够自动化对数据里所有需要分箱的连续变量进行分箱,所以在工程上需要做些处理,需要写个自动化分箱脚本:
class Woe_IV: def __init__(self,df,colList,target): ''' :param df: 这个是用来分箱的dataframe :param colList: 这个分箱的列数据,数据结构是一个字段数组 例如colList=[ { 'col':'openning_room_num_n3' 'bandCol':'openning_room_num_n3_band', 'bandNum':6, ‘toCsvPath':'/home/liuweitang/yellow_model/data/mk/my.txt' }, ] :param target 目标列0-1值,1表示bad,0表示good ''' self.df=df self.colList=colList self.target=target def to_band(self): for i in range(len(self.colList)): colParam=self.colList[i] #计算出箱体分别值,返回的是一个长度为5数组[0,4,13,45,78]或者长度为6的数组[0,2,4,56,67,89] cutOffPoints=ChiMerge_MaxInterval_Original(self.df,colParam['col'],self.target,colParam['bandNum']) print(cutOffPoints) indexValue=0 value_band=[] #那么cutOffPoints第一个值就是作为一个独立的箱 if len(cutOffPoints) == colParam['bandNum']-1: print('len-1 type') for i in range(0,len(cutOffPoints)): if i==0: self.df.loc[self.df[colParam['col']]<=cutOffPoints[i], colParam['bandCol']]=indexValue indexValue+=1 value_band.append('0-'+str(cutOffPoints[i])) if 0<i<len(cutOffPoints): self.df.loc[(self.df[colParam['col']] > cutOffPoints[i - 1]) & (self.df[colParam['col']] <= cutOffPoints[i]), colParam['bandCol']] = indexValue indexValue+=1 value_band.append(str(cutOffPoints[i - 1]+1)+"-"+str(cutOffPoints[i])) if i==len(cutOffPoints)-1: self.df.loc[self.df[colParam['col']] > cutOffPoints[i], colParam['bandCol']] = indexValue value_band.append(str(cutOffPoints[i]+1)+"-") #那么就是直接分割分箱, if len(cutOffPoints)==colParam['bandNum']: print('len type') for i in range(0,len(cutOffPoints)): if 0< i < len(cutOffPoints): self.df.loc[(self.df[colParam['col']] > cutOffPoints[i - 1]) & (self.df[colParam['col']] <= cutOffPoints[i]), colParam['bandCol']] = indexValue value_band.append(str(cutOffPoints[i - 1]+1)+"-"+str(cutOffPoints[i])) indexValue += 1 if i == len(cutOffPoints)-1: self.df.loc[self.df[colParam['col']] > cutOffPoints[i], colParam['bandCol']] = indexValue value_band.append(str(cutOffPoints[i]+1)+"-") self.df[colParam['bandCol']].astype(int) #到此分箱结束,下面判断单调性 isMonotone = BadRateMonotone(self.df,colParam['bandCol'], self.target) #如果不单调,那就打印出错误,并且继续执行下一个特征分箱 if isMonotone==False: print(colParam['col']+' band error, reason is not monotone') continue #单调性判断完之后,就要计算woe_IV值 woe_IV=CalcWOE(self.df, colParam['bandCol'],self.target) woe=woe_IV['WOE'] woe_result=[] for i in range(len(woe)): woe_result.append(woe[i]['WOE']) iv=woe_IV['IV'] iv_result=[] for i in range(len(iv)): iv_result.append(iv[i]) good_bad_count=self.df.groupby([colParam['bandCol'],self.target]).label.count() good_count=[] bad_count=[] for i in range(0,colParam['bandNum']): good_count.append(good_bad_count[i][0]) bad_count.append(good_bad_count[i][1]) print(value_band) print(good_count) print(bad_count) print(woe_result) print(iv_result) #将WOE_IV值保存为dataframe格式数据,然后导出到csv #这里其实还有个问题,就是 woe_iv_df=pd.DataFrame({ 'IV':iv_result, 'WOE':woe_result, 'bad':bad_count, 'good':good_count, colParam['bandCol']:value_band }) bad_good_count=self.df.groupby([colParam['bandCol'],self.target])[self.target].count(); woe_iv_df.to_csv(colParam['toCsvPath']) print(colParam['col']+'band finished')
应用方便 :
openning_data=pd.read_csv('***',sep='$') colList=[ { 'col':'openning_room_0_6_num_n3', 'bandCol':'openning_room_0_6_num_n3_band', 'bandNum':5, 'toCsvPath':'/home/liuweitang/yellow_model/eda/band_result/openning_room_0_6_num_n3_band.csv' }, { 'col':'openning_room_6_12_num_n3', 'bandCol':'openning_room_6_12_num_n3_band', 'bandNum':5, 'toCsvPath':'/home/liuweitang/yellow_model/eda/band_result/openning_room_6_12_num_n3_band.csv' } ] band2=Woe_IV(openning_data,colList,'label') band2.to_band()
8.分箱后处理
分箱后需要编码
- dummy
- one-hot
- label-encode
9.注意问题
对于分箱需要注意的是,分完箱之后,某些箱区间里,bad或者good分布比例极不均匀,极端时,会出现bad或者good数量直接为0。那么这样子会直接导致后续计算WOE时出现inf无穷大的情况,这是不合理的。这种情况,说明分箱太细,需要进一步缩小分箱的数量。