先说学习心得
通过这篇对特征重要性的baseline学习,我学习到了如下三个点:
3.回顾了xgb树模型的生成过程
资源搬运如下:
https://www.kaggle.com/aerdem4/m5-lofo-importance-on-gpu-via-rapids-xgboost
希望大家过去看看这位大佬的其他分享。谢谢。同时大佬在利物浦的比赛中又复用了这个计算特征重要性的方法。
from datetime import datetime, timedelta import gc import numpy as np, pandas as pd import lightgbm as lgb import cudf import cu_utils.transform as cutran
cu_utils这个是这位kaggler手写的轮子:


from numba import cuda, float32 import math def cu_mean_transform(x, y_out): res = cuda.shared.array(1, dtype=float32) res[0] = 0 cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): cuda.atomic.add(res, 0, x[i]) cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = res[0] / len(x) def cu_max_transform(x, y_out): res = cuda.shared.array(1, dtype=float32) res[0] = -math.inf cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): cuda.atomic.max(res, 0, x[i]) cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = res[0] def cu_min_transform(x, y_out): res = cuda.shared.array(1, dtype=float32) res[0] = math.inf cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): cuda.atomic.min(res, 0, x[i]) cuda.syncthreads() for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = res[0] def get_cu_shift_transform(shift_by, null_val=-1): def cu_shift_transform(x, y_out): for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = null_val if 0 <= i-shift_by < len(x): y_out[i] = x[i-shift_by] return cu_shift_transform def get_cu_rolling_mean_transform(window, null_val=-1): def cu_rolling_mean_transform(x, y_out): for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = 0 if i >= window-1: for j in range(cuda.threadIdx.y, window, cuda.blockDim.y): cuda.atomic.add(y_out, i, x[i-j]) y_out[i] /= window else: y_out[i] = null_val return cu_rolling_mean_transform def get_cu_rolling_max_transform(window, null_val=-1): def cu_rolling_max_transform(x, y_out): for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = -math.inf if i >= window-1: for j in range(cuda.threadIdx.y, window, cuda.blockDim.y): cuda.atomic.max(y_out, i, x[i-j]) else: y_out[i] = null_val return cu_rolling_max_transform def get_cu_rolling_min_transform(window, null_val=-1): def cu_rolling_min_transform(x, y_out): for i in range(cuda.threadIdx.x, len(x), cuda.blockDim.x): y_out[i] = math.inf if i >= window-1: for j in range(cuda.threadIdx.y, window, cuda.blockDim.y): cuda.atomic.min(y_out, i, x[i-j]) else: y_out[i] = null_val return cu_rolling_min_transform
其实轮子这块不没怎么看懂!
h = 28 max_lags = 57 tr_last = 1913 fday = datetime(2016,4, 25) FIRST_DAY = 1000 fday
下面是数据的预处理:
%%time def create_df(start_day): prices = cudf.read_csv("/kaggle/input/m5-forecasting-accuracy/sell_prices.csv") cal = cudf.read_csv("/kaggle/input/m5-forecasting-accuracy/calendar.csv") cal["date"] = cal["date"].astype("datetime64[ms]") numcols = [f"d_{day}" for day in range(start_day,tr_last+1)] catcols = ['id', 'item_id', 'dept_id','store_id', 'cat_id', 'state_id'] dt = cudf.read_csv("/kaggle/input/m5-forecasting-accuracy/sales_train_validation.csv", usecols = catcols + numcols) dt = cudf.melt(dt, id_vars = catcols, value_vars = [col for col in dt.columns if col.startswith("d_")], var_name = "d", value_name = "sales") dt = dt.merge(cal, on= "d") dt = dt.merge(prices, on = ["store_id", "item_id", "wm_yr_wk"]) return dt df = create_df(FIRST_DAY) df.head()
销量的数据总共从d1~d1913,但是kaggler用d1000-1913的数据作为训练数据。
可能是考虑时间太久远会,人的生活习惯会改变,历史行为的噪音过大。
def transform(data): nan_features = ['event_name_1', 'event_type_1', 'event_name_2', 'event_type_2'] for feature in nan_features: data[feature].fillna('unknown', inplace = True) data['id_encode'], _ = data["id"].factorize() cat = ['item_id', 'dept_id', 'cat_id', 'store_id', 'state_id', 'event_name_1', 'event_type_1', 'event_name_2', 'event_type_2'] for feature in cat: data[feature], _ = data[feature].factorize() return data df = transform(df) df.head()
kaggler先对['event_name_1', 'event_type_1', 'event_name_2', 'event_type_2']这些字段进行缺失值填补,然后再最['item_id', 'dept_id', 'cat_id', 'store_id', 'state_id', 'event_name_1', 'event_type_1', 'event_name_2', 'event_type_2']用类别编码。
其实我感觉这种对event的特征处理不是很合理。
kv={} for k in zip(calendar['event_name_1'].tolist(),calendar['event_type_1'].tolist(),calendar['event_name_2'].tolist(),calendar['event_type_2'].tolist()): if k not in kv: kv[k]=1 else: kv[k]=kv[k]+1 kv
数据如下:
{(nan, nan, nan, nan): 1807,
('SuperBowl', 'Sporting', nan, nan): 6,
('ValentinesDay', 'Cultural', nan, nan): 6,
('PresidentsDay', 'National', nan, nan): 6,
('LentStart', 'Religious', nan, nan): 6,
('LentWeek2', 'Religious', nan, nan): 6,
('StPatricksDay', 'Cultural', nan, nan): 6,
('Purim End', 'Religious', nan, nan): 6,
('OrthodoxEaster', 'Religious', 'Easter', 'Cultural'): 1,
('Pesach End', 'Religious', nan, nan): 6,
('Cinco De Mayo', 'Cultural', nan, nan): 5,
("Mother's day", 'Cultural', nan, nan): 6,
('MemorialDay', 'National', nan, nan): 6,
('NBAFinalsStart', 'Sporting', nan, nan): 6,
('NBAFinalsEnd', 'Sporting', nan, nan): 4,
("Father's day", 'Cultural', nan, nan): 4,
('IndependenceDay', 'National', nan, nan): 5,
('Ramadan starts', 'Religious', nan, nan): 6,
('Eid al-Fitr', 'Religious', nan, nan): 5,
('LaborDay', 'National', nan, nan): 5,
('ColumbusDay', 'National', nan, nan): 5,
('Halloween', 'Cultural', nan, nan): 5,
('EidAlAdha', 'Religious', nan, nan): 5,
('VeteransDay', 'National', nan, nan): 5,
('Thanksgiving', 'National', nan, nan): 5,
('Christmas', 'National', nan, nan): 5,
('Chanukah End', 'Religious', nan, nan): 5,
('NewYear', 'National', nan, nan): 5,
('OrthodoxChristmas', 'Religious', nan, nan): 5,
('MartinLutherKingDay', 'National', nan, nan): 5,
('Easter', 'Cultural', nan, nan): 4,
('OrthodoxEaster', 'Religious', nan, nan): 3,
('OrthodoxEaster', 'Religious', 'Cinco De Mayo', 'Cultural'): 1,
('Easter', 'Cultural', 'OrthodoxEaster', 'Religious'): 1,
('NBAFinalsEnd', 'Sporting', "Father's day", 'Cultural'): 2}
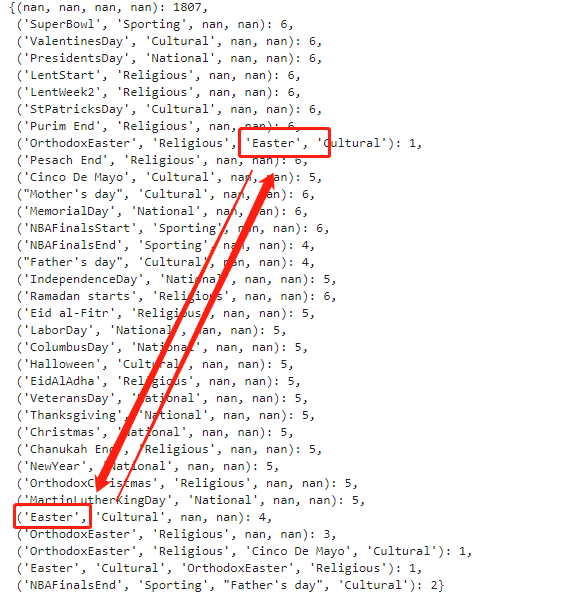
我认为对event1,2分开编码必然是不合理的。应该转为onehot的编码方式,也可以省去fillna.
特征工程:
def create_fea(data): for lag in [7, 28]: out_col = "lag_{}".format(str(lag)) data[out_col] = data[["id", "sales"]].groupby("id", method='cudf').apply_grouped(cutran.get_cu_shift_transform(shift_by=lag), incols={"sales": 'x'}, outcols=dict(y_out=np.float32), tpb=32)["y_out"] for window in [7, 28]: out_col = "rmean_{lag}_{window}".format(lag=lag, window=window) data[out_col] = data[["id", "lag_{}".format(lag)]].groupby("id", method='cudf').apply_grouped(cutran.get_cu_rolling_mean_transform(window), incols={"lag_{}".format(lag): 'x'}, outcols=dict(y_out=np.float32), tpb=32)["y_out"] # time features data['date'] = data['date'].astype("datetime64[ms]") data['year'] = data['date'].dt.year data['month'] = data['date'].dt.month data['day'] = data['date'].dt.day data['dayofweek'] = data['date'].dt.weekday return data # define list of features features = ['item_id', 'dept_id', 'cat_id', 'store_id', 'state_id', 'event_name_1', 'event_type_1', 'event_name_2', 'event_type_2', 'snap_CA', 'snap_TX', 'snap_WI', 'sell_price', 'year', 'month', 'day', 'dayofweek', 'lag_7', 'lag_28', 'rmean_7_7', 'rmean_7_28', 'rmean_28_7', 'rmean_28_28' ] df = create_fea(df)
用滑窗构建特征,先lag,后对lag的值进行滑窗求均值。
类似于这样:

使用xgboost计算特征重要性:
from lofo import LOFOImportance, Dataset, plot_importance from sklearn.model_selection import KFold import xgboost sample_df = df.to_pandas().sample(frac=0.1, random_state=0) sample_df.sort_values("date", inplace=True) cv = KFold(n_splits=5, shuffle=False, random_state=0) dataset = Dataset(df=sample_df, target="sales", features=features) # define the validation scheme and scorer params = {"objective": "count:poisson", "learning_rate" : 0.075, "max_depth": 6, 'n_estimators': 200, 'min_child_weight': 50, "tree_method": 'gpu_hist', "gpu_id": 0} xgb_reg = xgboost.XGBRegressor(**params) lofo_imp = LOFOImportance(dataset, cv=cv, scoring="neg_mean_squared_error", model=xgb_reg) # get the mean and standard deviation of the importances in pandas format importance_df = lofo_imp.get_importance()
绘图如下:
plot_importance(importance_df, figsize=(12, 20))
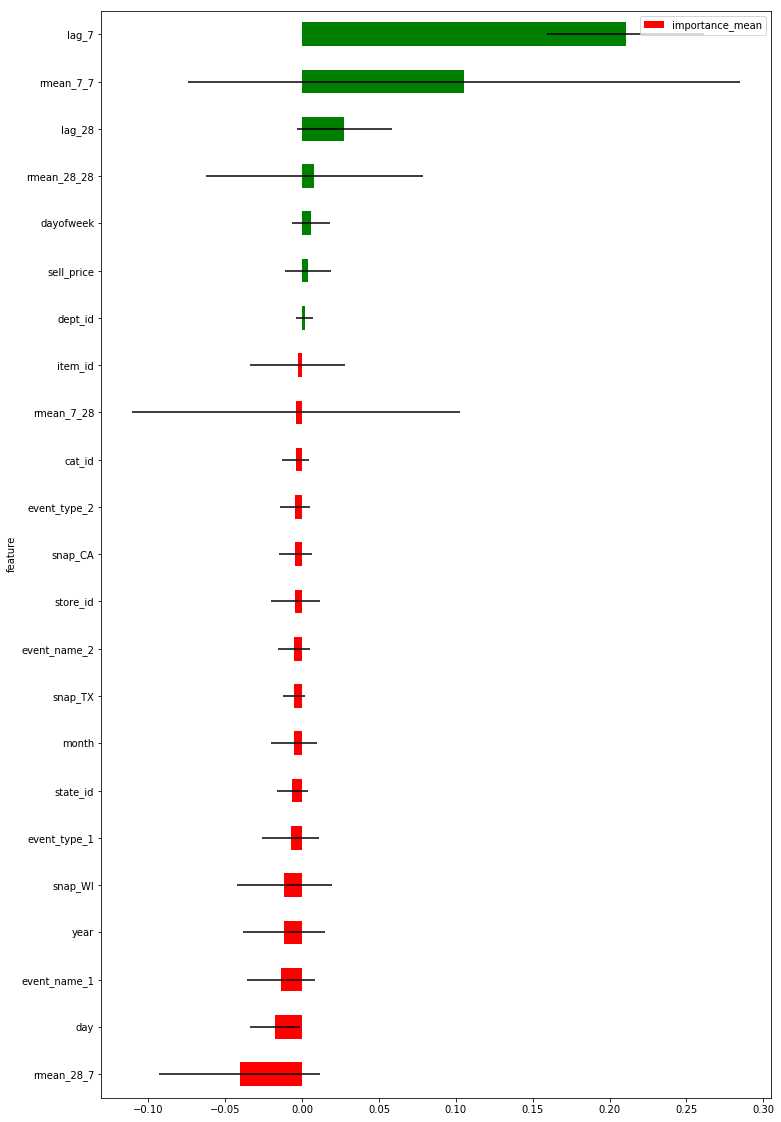
拿到特征重要度后,我们如何理解这里的特征重要度。
在训练集中,减少某个特征导致最终准确性减少的值(base-lofo),减少的值越大就意味着这个特征越重要。
当此值为负时,便意味着这个去掉这个特征反而导致模型分数更优,那么这个特征是噪声特征,应该被舍弃。

未完待续@@