一、表说明(MYSql)

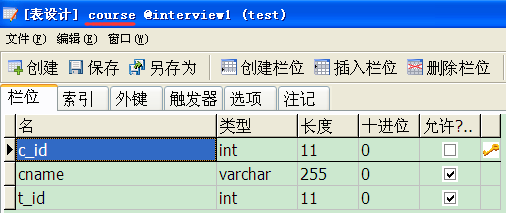

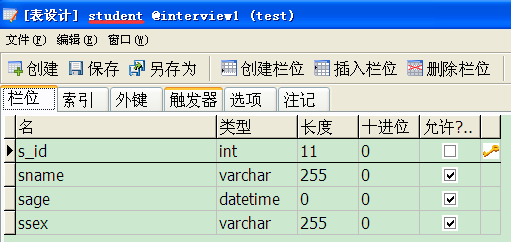

二、导入测试数据
学生表
insert into Student values('01' , N'赵雷' , '1990-01-01' , N'男'); insert into Student values('02' , N'钱电' , '1990-12-21' , N'男'); insert into Student values('03' , N'孙风' , '1990-05-20' , N'男'); insert into Student values('04' , N'李云' , '1990-08-06' , N'男'); insert into Student values('05' , N'周梅' , '1991-12-01' , N'女'); insert into Student values('06' , N'吴兰' , '1992-03-01' , N'女'); insert into Student values('07' , N'郑竹' , '1989-07-01' , N'女'); insert into Student values('08' , N'王菊' , '1990-01-20' , N'女');
课程表
insert into Course values('01' , N'语文' , '02'); insert into Course values('02' , N'数学' , '01'); insert into Course values('03' , N'英语' , '03');
教师表
insert into Teacher values('01' , N'张三'); insert into Teacher values('02' , N'李四'); insert into Teacher values('03' , N'王五');
成绩表
insert into Score values('01' , '01' , 80); insert into Score values('01' , '02' , 90); insert into Score values('01' , '03' , 99); insert into Score values('02' , '01' , 70); insert into Score values('02' , '02' , 60); insert into Score values('02' , '03' , 99.5); insert into Score values('03' , '01' , 80); insert into Score values('03' , '02' , 99); insert into Score values('03' , '03' , 80); insert into Score values('04' , '01' , 50); insert into Score values('04' , '02' , 30); insert into Score values('04' , '03' , 20); insert into Score values('05' , '01' , 76); insert into Score values('05' , '02' , 87); insert into Score values('06' , '01' , 31); insert into Score values('06' , '03' , 34); insert into Score values('07' , '02' , 89); insert into Score values('07' , '03' , 98);
(interview1)
三、查询
成绩情况
目录:
1. 查询各科成绩第一名的记录
2. 查询各科成绩前三名的记录(x,y)
3. 查询所有学生的课程及分数情况
4. 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
5. 查询学生平均成绩及其名次
6. 查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
7. 查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
8. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
9. 查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
10. 查询不及格的课程
11. 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
12. 查询在score表中不存在成绩的学生信息的SQL语句/查询没有参加任何一门课程考试(缺考所有课程)的学生信息的SQL语句。
13. 查询课程名称为"数学",且分数低于60的学生姓名和分数
14. 检索"01"课程分数小于60,按分数降序排列的学生信息
15. 查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
16. 查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
17. 查询s_id=7的学生的平均分
18. 查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
19. 查询"01"课程比"02"课程成绩高的学生的信息及课程分数
20. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
-----------------------------------------------------------------------------------------------
1.查询各科成绩第一名的记录
select student.s_id,sname,cname,m.score from student,course, ( select t1.* , (select count(distinct t2.score) from SCore t2 where t2.C_id = t1.C_id and t2.score >= t1.score)px from score t1 ) m where px between 1 and 1 and student.s_id=m.s_id and course.c_id=m.c_id order by m.C_id , m.px
分析:该查询的关键是在socre表中查询某分数在其所在课程的排名,如下面的一条记录:

那么这条记录中的80分在课程编号1中排第几名呢?——这就是本条SQL查询的关键问题。这个关键问题体现在SQL:
SQL1
select t1.* , (select count(distinct t2.score) from SCore t2
where t2.C_id = t1.C_id and t2.score >= t1.score)px from score t1
其查询结果如下:
图1
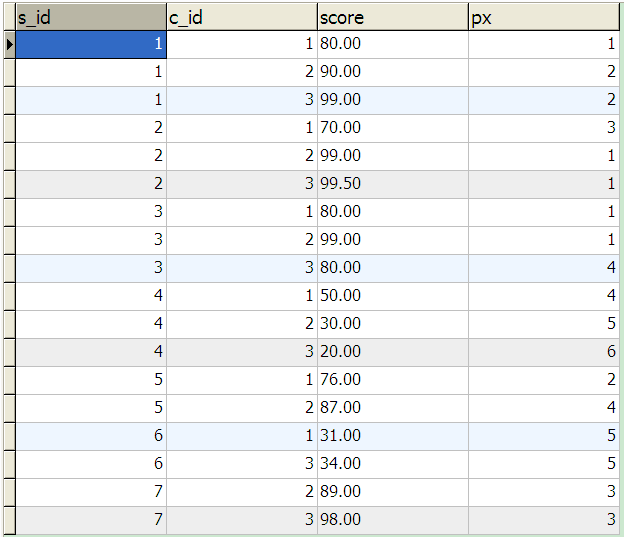
其中px列为其所在记录在其所属课程中的排名。那么这个排名是如何统计出来的呢?再看上面的SQL,从结构上看,SQL1对score表查询了2次,关键是其中里面的查询,其结果是count(distinct t2.score),count函数是查询符合条件的条数,distinct 是去掉重复的;再结合条件C_id = t.C_id,这在查询中会返回:t2与当前记录行中t1的C_id相等的条数(去重后的)--举例解释:下面将SQL1简化一下:
SQL2
select t1.* , (select count(distinct t2.score) from SCore t2
where t2.C_id = t1.C_id)px from score t1
查询结果(片段):

上面的结果中的px列的值的意思是c_id=1的记录有5条(去重后的,如果不去重,在score表中c_id=1的记录有6条)。
现在再加上SQL1中的条件score >= t.score,这样在查询中就会返回:在t2与当前记录行中t1的C_id相等的记录中,比当前记录行中t1的score大或者相等的条数——如图1中的这条记录:

此记录中的1即是这条记录中的score在c_id=1的课程中的排名。那么它是如何得来的呢?SQL1的查询过程中首先会返回两张虚拟表:t2与t1,如在查询第一行记录时,首先很容易地得到t1的第一行记录,在查询px的第一行记录时,分析器会分析其中的where条件:首先得到与t1的第一行记录中c_id相等(c_id=1)的集合,然后在此集合中查出比t1的第一行记录中的score大于或等于的记录,最后统计其条数(1),就是第一行记录中px值。
小结:在SQL1的整个查询中,t2所充当的角色相当于条件,而t1则是要返回的主要结果,因此可以称t2为“条件表”,t1为“结果表”,前者的作用在于为后者提供比对的数据,二者的查询结果一致。
结果:

2.查询各科成绩前三名的记录
2.1分数重复时保留名次空缺(x)
select m.* , n.C_id , n.score from Student m, SCore n where m.S_id = n.S_id and n.score in (select score from score where C_id = n.C_id order by score desc ) order by n.C_id , n.score desc
2.2分数重复时不保留名次空缺,合并名次
select student.s_id,sname,cname,m.score from student,course,(select t.* , (select count(distinct score) from SCore where C_id = t.C_id and score >= t.score)px from score t) m where px between 1 and 3 and student.s_id=m.s_id and course.c_id=m.c_id order by m.C_id , m.px
结果:

3.查询所有学生的课程及分数情况
select Student.* , Course.Cname , SCore.C_id , SCore.score from Student, SCore , Course where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id group by Student.S_id , SCore.C_id order by Student.S_id , SCore.C_id
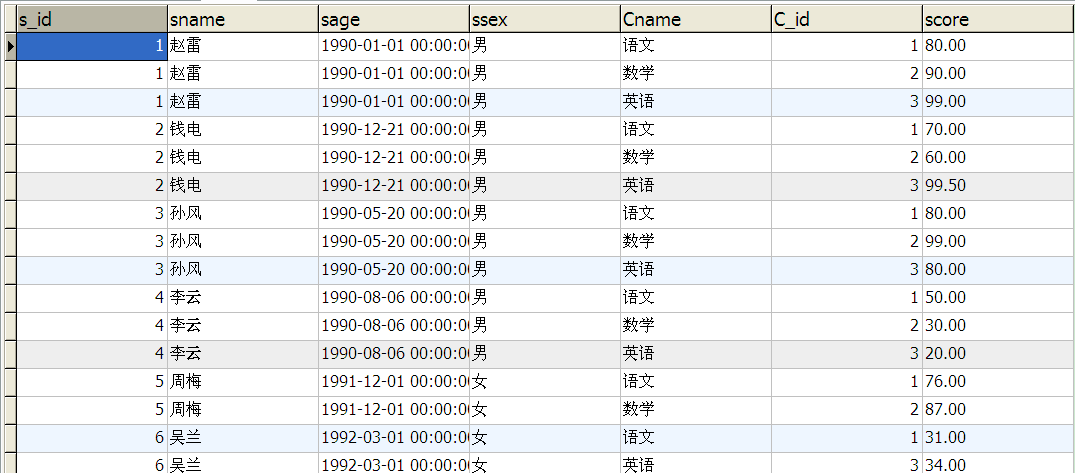
4.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
注:1.ifnull(cast(avg(b.score) asdecimal(18,2)),0) 平均分 可以去掉ifnull,写成:cast(avg(b.score) as decimal(18,2)) 平均分
2.目前在score表中,如果某位同学没有参加考试则没有成绩记录,这样会导致计算平均分错误,如郑竹同学的平均分只计算了其(数学+英语)/2。正确的做法应该是即使某位同学没有参加某科目的考试,那么该同学在socre表也应有记录,只不过对应的记录中的成绩为0,这样计算平均分就不会有错。
select a.S_id 学生编号 , a.Sname 学生姓名 , max(case c.Cname when '语文' then b.score else null end) 语文, max(case c.Cname when '数学' then b.score else null end) 数学, max(case c.Cname when '英语' then b.score else null end) 英语, ifnull(cast(avg(b.score) as decimal(18,2)),0) 平均分 from Student a left join SCore b on a.S_id = b.S_id left join Course c on b.C_id = c.C_id group by a.S_id , a.Sname order by 平均分 desc
分析:
如果不用case..when,则查询结果如第3个SQL。此SQL需解释2点:1.max(case c.Cname when '语文' then b.score else null end) 语文, 2.ifnull(cast(avg(b.score) as decimal(18,2)),0) 平均分
第1点:首先,关于MYsql的case函数有这样的介绍(详细介绍见http://www.jb51.net/article/28680.htm):
CASE 具有两种格式:
简单 CASE 函数将某个表达式与一组简单表达式进行比较以确定结果。
CASE 搜索函数计算一组布尔表达式以确定结果。
两种格式都支持可选的 ELSE 参数。
该SQL的case函数属于简单 CASE 函数,如果表达式1 c.Cname与表达式2 '语文'比对结果为true时,返回结果 b.score,否则返回结果 null(这有点类似于三目运算符)。那么问题是,为什么前面要加个聚合函数 max呢?现在将该SQL简化一下:
select a.S_id 学生编号 , a.Sname 学生姓名,
case c.Cname when '语文' then b.score else null end 语文,
case c.Cname when '数学' then b.score else null end 数学,
case c.Cname when '英语' then b.score else null end 英语
from Student a
left join SCore b on a.S_id = b.S_id
left join Course c on b.C_id = c.C_id
查询结果(片段):

可以看出,由于没有聚合函数,对于赵雷同学的三科成绩有三条记录,这样的查询结果显然需要进一步优化——即利用max,结合group by a.S_id , a.Sname,就可以将上面的三条记录合并为一条。
第2点:在ifnull(cast(avg(b.score) as decimal(18,2)),0) 平均分 中,cast是转换格式函数,将avg(b.score)转换成decimal(18,2)的格式(最多18位,小数点右边最多2位);ifnull是判断参数cast(avg(b.score) as decimal(18,2))的值是否为null,如果是,查询结果显示为0。
结果:
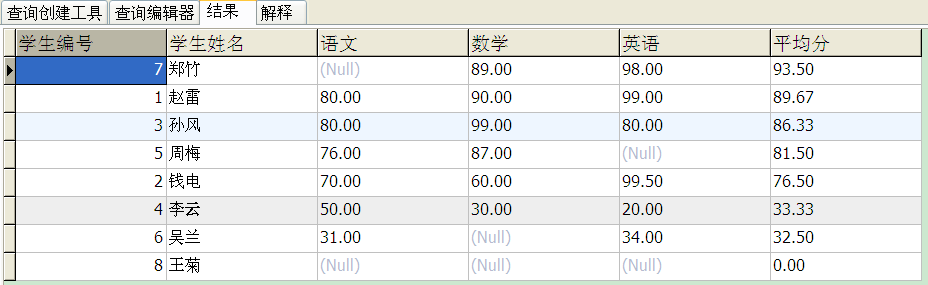
5.查询学生平均成绩及其名次
方法1
select t1.* , (select count(1) from( select m.S_id 学生编号 , m.Sname 学生姓名 , ifnull(cast(avg(score) as decimal(18,2)),0) 平均成绩 from Student m left join score n on m.S_id = n.S_id group by m.S_id , m.Sname ) t2 where 平均成绩 > t1.平均成绩) + 1 as 名次 from( select m.S_id 学生编号, m.Sname 学生姓名 , ifnull(cast(avg(score) as decimal(18,2)),0) 平均成绩 from Student m left join score n on m.S_id = n.S_id group by m.S_id , m.Sname ) t1 order by 名次
方法2
select t1.* , (select count(distinct t2.平均成绩) from( select m.S_id 学生编号 , m.Sname 学生姓名 , ifnull(cast(avg(score) as decimal(18,2)),0) 平均成绩 from Student m left join SCore n on m.S_id = n.S_id group by m.S_id , m.Sname ) t2 where t2.平均成绩 >= t1.平均成绩) as 名次 from( select m.S_id 学生编号 , m.Sname 学生姓名 , ifnull(cast(avg(score) as decimal(18,2)),0) 平均成绩 from Student m left join SCore n on m.S_id = n.S_id group by m.S_id , m.Sname ) t1 order by 名次
分析(方法2):此SQL虽然较长,但其查询原理同第1条、第3条SQL。关键在于理解“名次”是怎么来的。从结构上看,此SQL也是通过对同一结果查询了2次而实现的(第1条SQL是对score表查询了2次)。查询t1.* ,select count(distinct t2.平均成绩),条件是:t2.平均成绩 >= t1.平均成绩,其中,在查询列select count(distinct t2.平均成绩)时,会拿当前记录行的t1的平均成绩与t2中的平均成绩进行比较,返回比当前记录行中t1的平均成绩大于或等于的条数——即当前记录行中的平均成绩的名次,如在结果(图2)中的第一条记录中,名次列中的1即是当前记录行中的t1的平均成绩(93.50)与t2中的平均成绩比较符合条件“比93.50大于或等于”的条数。
结果:
图2

6.查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
select a.S_id , a.Sname , cast(avg(b.score) as decimal(18,2)) 平均分 from Student a , score b where a.S_id = b.S_id group by a.S_id , a.Sname having cast(avg(b.score) as decimal(18,2)) >= 85 order by 平均分 desc
注意:对于聚合函数的判断用having而不用where。
结果:

7.查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
7.1查询在score表存在成绩的学生信息的SQL语句。
select a.S_id , a.Sname , cast(avg(b.score) as decimal(18,2)) avg_score from Student a , score b where a.S_id = b.S_id group by a.S_id, a.Sname having cast(avg(b.score) as decimal(18,2)) < 60 order by a.S_id

7.2查询包括在score表中不存在成绩记录的学生信息的SQL语句。
select a.S_id, a.Sname , ifnull(cast(avg(b.score) as decimal(18,2)),0) avg_score from Student a left join score b on a.S_id = b.S_id group by a.S_id , a.Sname having ifnull(cast(avg(b.score) as decimal(18,2)),0) < 60 order by a.S_id
分析:1.要返回score表中的null记录就需要左外连接left join;2.在having条件中,只有利用ifnull将null转换为0,才能与具体的数(60)进行比较。
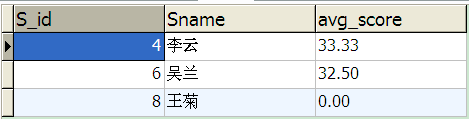
8. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select m.C_id , m.Cname , cast(avg(n.score) as decimal(18,2)) 平均分 from Course m, SCore n where m.C_id = n.C_id group by m.C_id , m.Cname order by 平均分 desc, m.C_id asc

9.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
9.1 查询所有有成绩的SQL
select a.s_id '学生编号', a.Sname '学生姓名', count(b.c_id) 选课总数, sum(score) '所有课程的总成绩' from Student a , SCore b where a.s_id = b.s_id group by a.s_id,a.Sname order by sum(score) desc
分析:对于返回的选课总数、所有课程的总成绩的依据条件均是a.s_id,a.Sname

9.2查询所有(包括有成绩和无成绩)的SQL
select a.s_id as '学生编号', a.Sname as '学生姓名', count(b.c_id) as '选课总数', sum(score) as '所有课程的总成绩' from Student a left join SCore b on a.s_id = b.s_id group by a.s_id,a.Sname order by sum(score) desc
分析:通过9.1与9.2的比较可以很典型地说明对于多表查询有无left(right)join..on的区别,有了左外连接或右外连接,可以返回null记录,而如果没有(或join..on或inner..join)则不返回null记录。

10.查询不及格的课程
select Student.* , Course.Cname , SCore.C_id, SCore.score from Student, SCore , Course where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id and SCore.score < 60 order by Student.S_id , SCore.C_id

11.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
11.1查询在score表存在成绩的学生信息的SQL语句。
select student.S_id, student.sname , cast(avg(score) as decimal(18,2)) 平均分 from student , SCore where student.S_id = SCore.S_id and student.S_id in (select S_id from SCore where score < 60 group by S_id having count(1) >= 2) group by student.S_id , student.sname order by 平均分 desc

11.2查询包括在score表不存在成绩记录的学生信息的SQL语句。(注:此条SQL不符需求,题目是查询至少2门不及格的同学的平均成绩,这里却是查询平均成绩小于60的信息。二者是不同的需求,比如某同学二科成绩均为59,另一科100,那么他的平均分会高于60,这个同学信息就满足前者而不满足后者。)
select a.S_id, a.Sname , ifnull(cast(avg(b.score) as decimal(18,2)),0) 平均分 from Student a left join score b on a.S_id = b.S_id group by a.S_id , a.Sname having ifnull(cast(avg(b.score) as decimal(18,2)),0) < 60 order by 平均分 desc

12. 查询在score表中不存在成绩的学生信息的SQL语句/查询没有参加任何一门课程考试(缺考所有课程)的学生信息的SQL语句。
select a.s_id, a.Sname , ifnull(cast(avg(b.score) as decimal(18,2)),0) avg_score from Student a left join score b on a.s_id = b.s_id group by a.s_id , a.Sname having ifnull(cast(avg(b.score) as decimal(18,2)),0) = 0 order by a.s_id
分析:如果一个同学没有参加任何一门课程的考试,那么其平均分肯定为0,所以查询利用ifnull(cast(avg(b.score) as decimal(18,2)),0) = 0 作为查询条件即可查出。

延伸:如果查询缺考指定课程的同学记录呢?
示例:查询缺考课程编号为1的同学信息。
如果想以左外连接(left join)进行查询,即在结果表中有s_id的记录,而对应的c_id、score为null记录,然后以此为条件进行筛选是行不通的。如:
select a.s_id,a.sname,c.c_id,cast(b.score as decimal(18,2)) 成绩
from student a
left join score b on a.s_id=b.s_id
left join course c on c.c_id=b.c_id
where c.c_id=1 and c.c_id=null and cast(b.score as decimal(18,2)) =null
分析:这是因为此SQL即使去掉where条件(蓝色SQL),所查询的结果也没有哪条记录是有s_id,而对应的c_id、score为null的记录。下面是蓝色SQL的查询结果(片段):

从上面的结果可以看出郑竹同学缺考了课程为1(c_id=1)的考试,但是却没有查出来,查出来的只是王菊同学。这是为什么呢?这是因为左外连接(left join)返回的是左表的全部记录以及与联结字段所匹配的记录:返回student表的所有记录(8个同学),以及score b on a.s_id=b.s_id、course c on c.c_id=b.c_id所匹配的记录,这两个条件匹配了2条郑竹同学的成绩记录。
因此,解决此查询,需换另一个角度。再分析一下题目:查询缺考课程编号为1的同学信息,如李某,首先在student表肯定有李某的信息,在score表缺少了李某对应的课程编号为1的成绩记录,但却有所有参加了该课程考试的同学的相应记录,那么查询的逻辑就出来了:先查出在student表中的所有记录,再在score表中查询所有参加了课程编号为1的所有记录中的同学编号(s_id),利用not in进行比对,即可查出结果。
select * from student where student.s_id not in( select st.s_id from score s,student st,course c where s.s_id=st.s_id and s.c_id=c.c_id and c.c_id=1 )
结果:

13.查询课程名称为"数学",且分数低于60的学生姓名和分数
select sname , score from Student , SCore , Course where SCore.S_id = Student.S_id and SCore.C_id = Course.C_id and Course.Cname = N'数学' and score < 60

14.检索"01"课程分数小于60,按分数降序排列的学生信息
select student.* , score.C_id , score.score from student , score where student.S_id = score.S_id and score.score < 60 and score.C_id = '01' order by score.score desc

15.查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
select Student.* , Course.Cname , SCore.C_id , SCore.score from Student, SCore , Course where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id and SCore.C_id = '01' and SCore.score >= 80 order by Student.S_id , SCore.C_id

16.查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
为了说明以下两种情况,现在改变一下数据:“张三”老师所授的课程编号为2,现在将学号为2的学生的该课程成绩由60改为99,这样成绩表中就有2条记录。

16.1当最高分只有一个时
select Student.* , Course.Cname , SCore.C_id , SCore.score from Student, SCore , Course , Teacher where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id and Course.T_id = Teacher.T_id and Teacher.Tname = N'张三' order by SCore.score desc limit 0,1

16.2当最高分出现多个时
select Student.* , Course.Cname , SCore.C_id , SCore.score from Student, SCore , Course , Teacher where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id and Course.T_id = Teacher.T_id and Teacher.Tname = N'张三' and SCore.score = (select max(SCore.score) from SCore , Course , Teacher where SCore.C_id = Course.C_id and Course.T_id = Teacher.T_id and Teacher.Tname = N'张三')
分析:该SQL先查出张三老师所授的课程中所有同学及分数的信息,在这个结果中以分数作为限定条件——“其中分数最大的”进行筛选。

17.查询s_id=1的学生的平均分
select a.S_id , a.Sname , cast(avg(b.score) as decimal(18,2)) avg_score from Student a , score b where a.S_id = b.S_id and a.S_id=1 group by a.S_id, a.Sname

18. 查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
select Student.* , Course.Cname , SCore.C_id , SCore.score from Student, SCore , Course where Student.S_id = SCore.S_id and SCore.C_id = Course.C_id and SCore.score >= 70 order by Student.S_id , SCore.C_id

19.查询"01"课程比"02"课程成绩高的学生的信息及课程分数
19.1查询同时存在"01"课程和"02"课程的情况
select a.* , b.score '课程"01"的分数',c.score '课程"02"的分数' from Student a , SCore b , SCore c where a.S_id = b.S_id and a.S_id = c.S_id and b.C_id = '01' and c.C_id = '02' and b.score > c.score

19.2查询同时存在"01"课程和"02"课程的情况和存在"01"课程但可能不存在"02"课程的情况(不存在时显示为null)
select a.* , b.score '课程"01"的分数',c.score '课程"02"的分数' from Student a left join SCore b on a.S_id = b.S_id and b.C_id = '01' left join SCore c on a.S_id = c.S_id and c.C_id = '02' where b.score > ifnull(c.score,0)
分析:由于需要比较两门课程的分数,所以需要查询两次score表:score b,score b。
注意:该SQL的条件中一定要用ifnull,否则当c.score为null时,b.score无法与之进行比较。

20. 查询不同课程成绩相同(成绩相同的课程)的学生的学生编号、课程编号、学生成绩
方法1
select m.* from SCore m ,(select C_id , score from SCore group by C_id , score having count(1) > 1) n where m.C_id= n.C_id and m.score = n.score order by m.C_id , m.score , m.S_id
分析:解决此查询的关键在于查出成绩相同的课程,SQL“select C_id , score from SCore group by C_id , score having count(1) > 1” 即是此目的,其中,group by C_id , score having count(1) > 1 表示在score中C_id 相同并且score相同的记录大于1,此SQL返回score表中相同的课程出现重复的分数的C_id、score,结果如下:

由于上述查询结果是根据C_id , score查询的,因此不能正确返回相应的s_id,解决这一点,只需把此结果作为条件,查询一下score表 m,以
m.C_id= n.C_id and m.score = n.score 作为联结条件即可查出所需结果。
方法2(注:select 1可以换成select n.* ,表示查询符合条件的所有记录。)
select m.* from SCore m where exists ( select 1 from (select C_id , score from SCore group by C_id , score having count(1) > 1) n where m.C_id= n.C_id and m.score = n.score ) order by m.C_id , m.score , m.S_id
分析:比较方法1,此方法利用了exists这个关键字,EXISTS 是判断是否存在,和in类似。但需注意的是,这里的exists并不能换成in——这很能典型地说明它们的区别。【那么它们有什么区别呢?
需说明的是,in和exists的区别不止一点,在这里所体现的是:
Exists是存在判断,只要有其中一个存在就返回。
in是返回所有包含在in中的数据。
现在就结合当前的例子加以说明:
假设换成in ,则SQL为:
select m.* from SCore m where m.c_id in (
select 1 from (select C_id , score from SCore group by C_id , score having count(1) > 1) n
where m.C_id= n.C_id and m.score = n.score
)
order by m.C_id , m.score , m.S_id
查询结果:

只是看以上的结果似乎还不能明白什么是“in是返回所有包含在in中的数据”,为了弄清楚这句话的含义,现在来看一下SQL..】待续..
结果:
