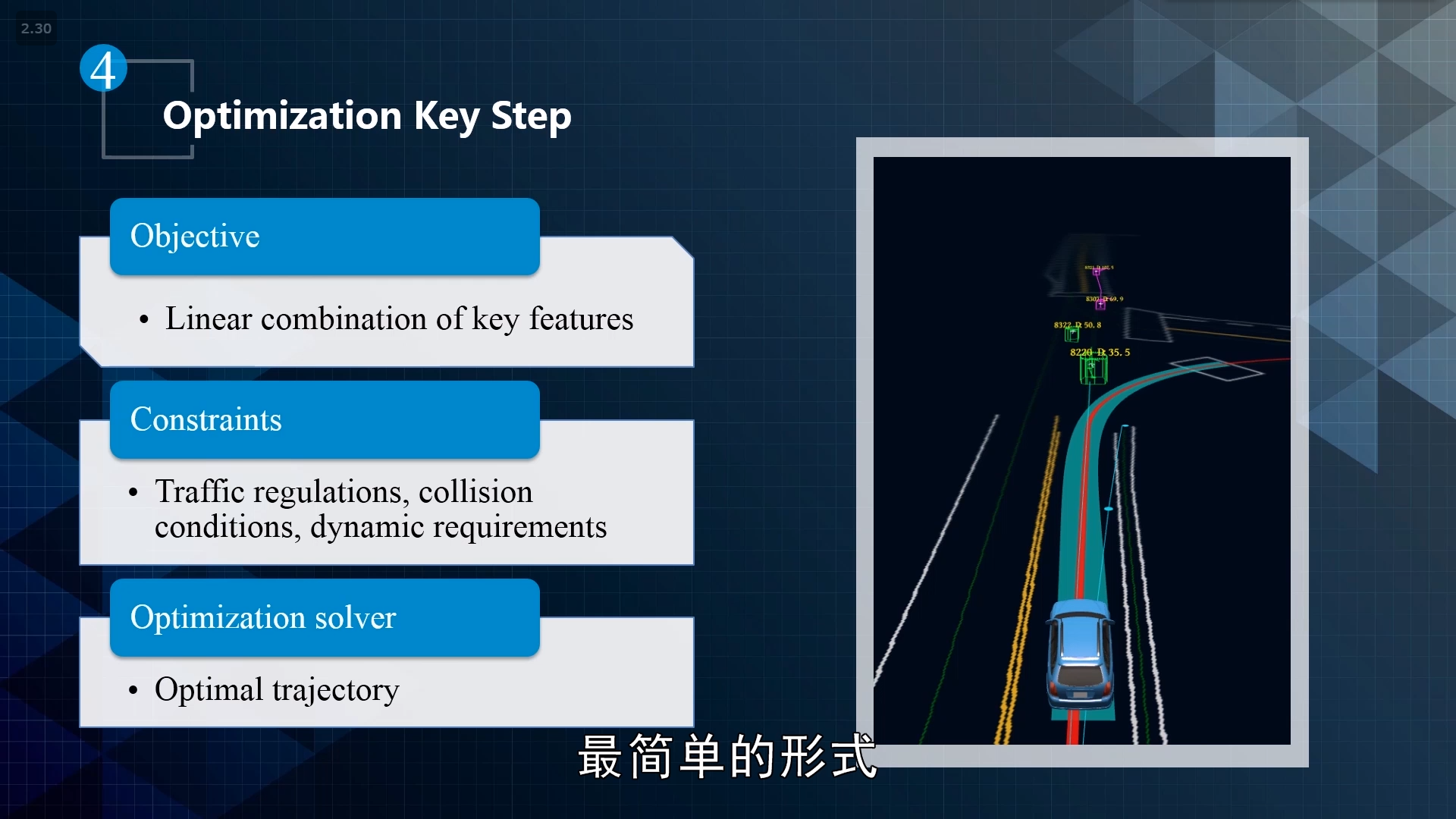
5.optimization inside motion planning
约束问题的核心有三点:
1.目标函数的定义
2.约束。如路网约束、交规、动态约束等
3.约束问题的优化。如动态规划、二次规划等
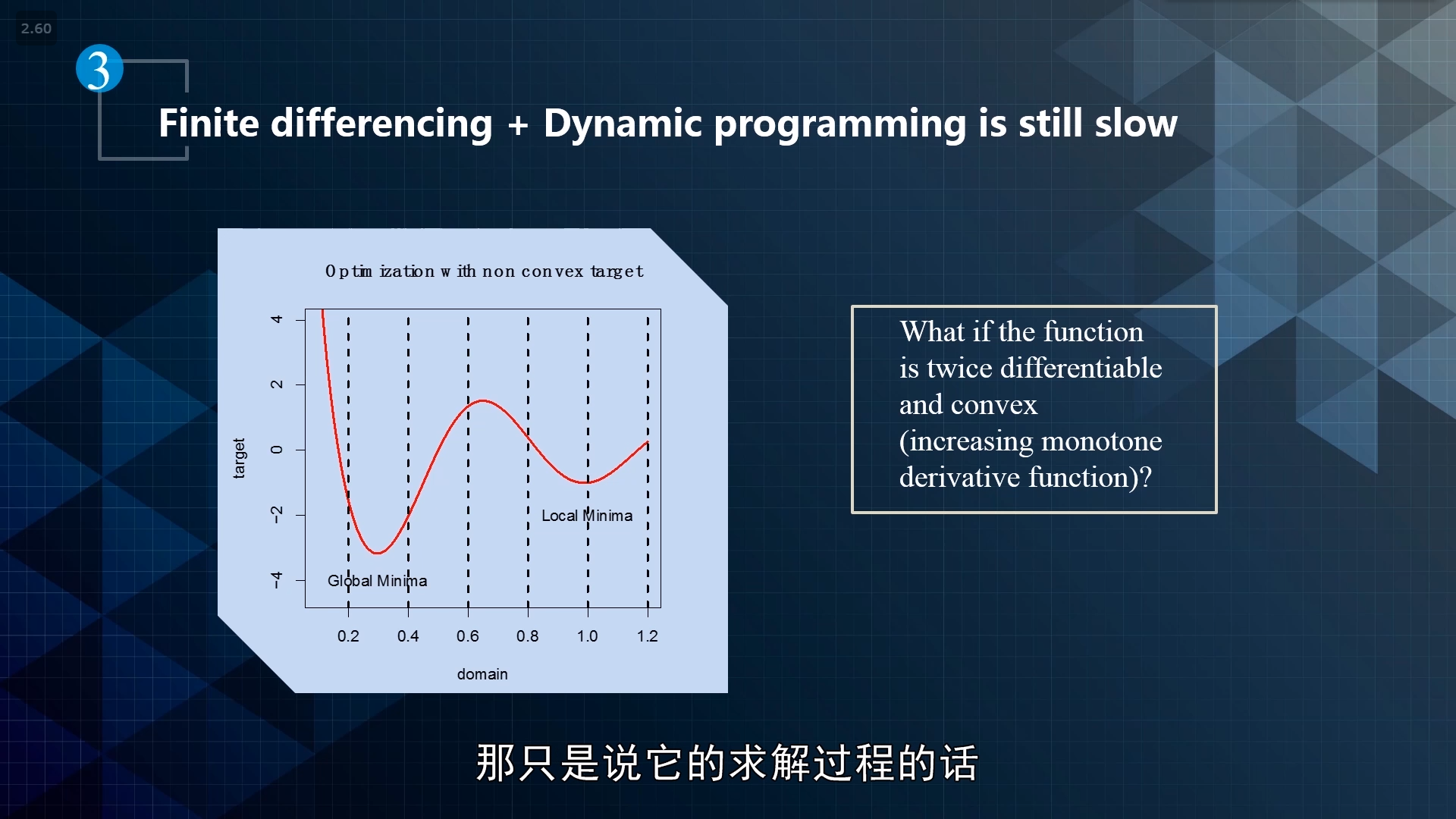
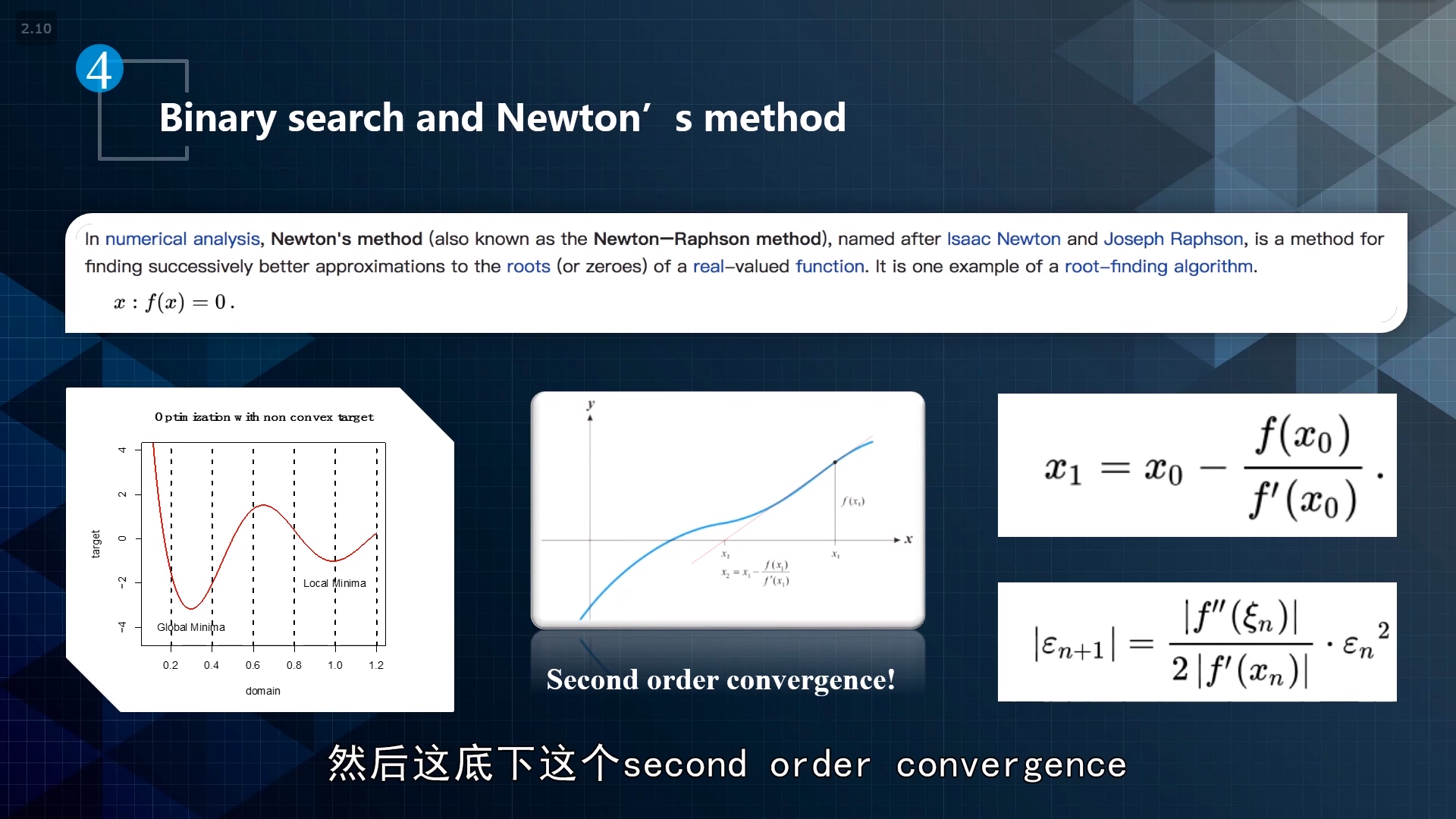
牛顿迭代法:研究导数变化,一阶导、二阶导、考虑斜率变化率,然后再用binary search去逼近。
核心思想:泰勒展开
收敛次数:指数平方,二次收敛
求解全局最优解:分块,求局部最优解,再综合
启发式搜索:用动态规划初步了解,计划二次规划方案
模拟退火等等。
quadratic programming

- 解决有约束条件的问题:

Lagrangian Method

KKT condition

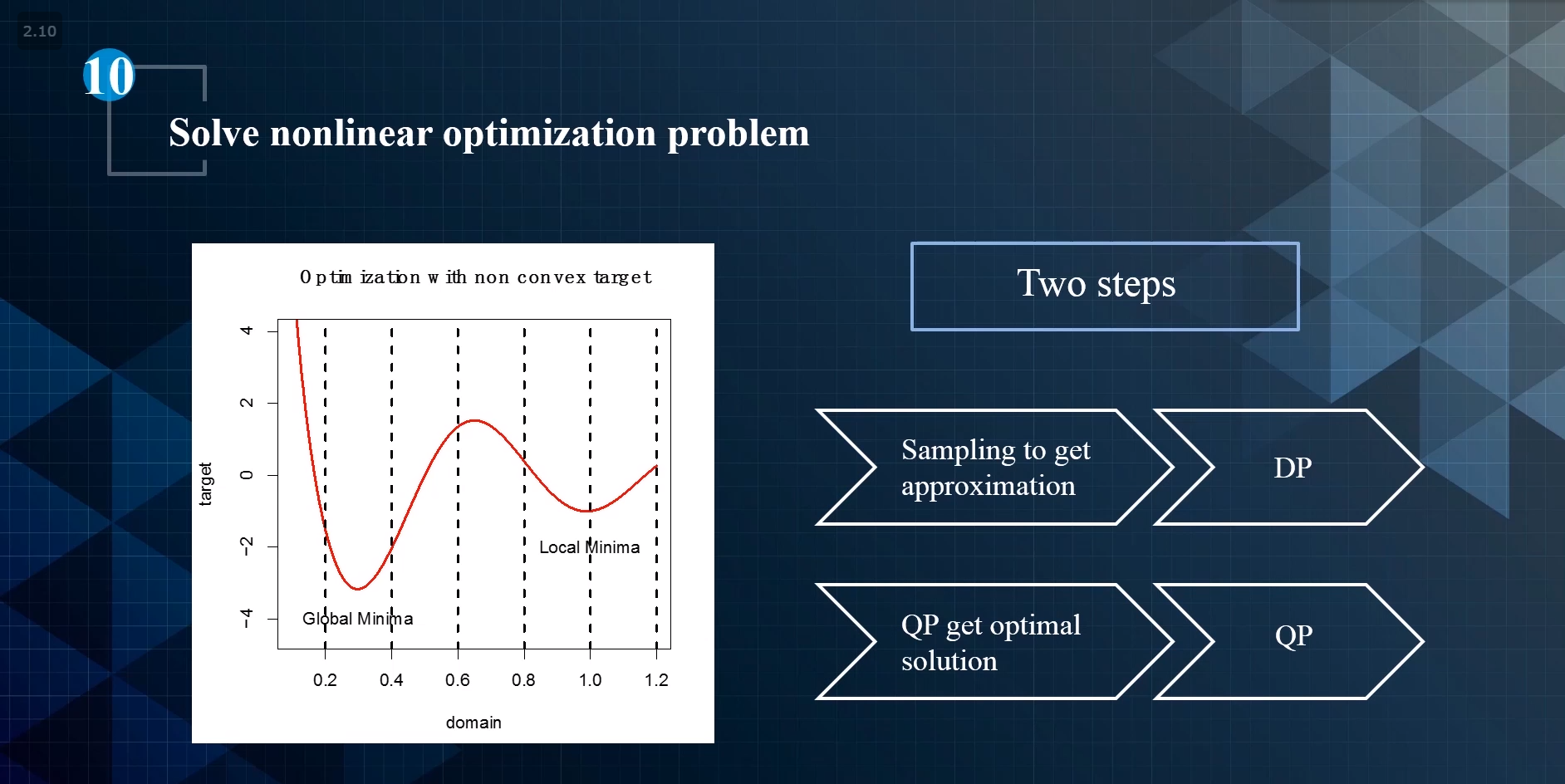
solve nonlinear optimization problem
分两步:
1.DP。初步进行规划
2.QP。在初步规划的基础上找到最优解
6.understand more on the MP difficulty
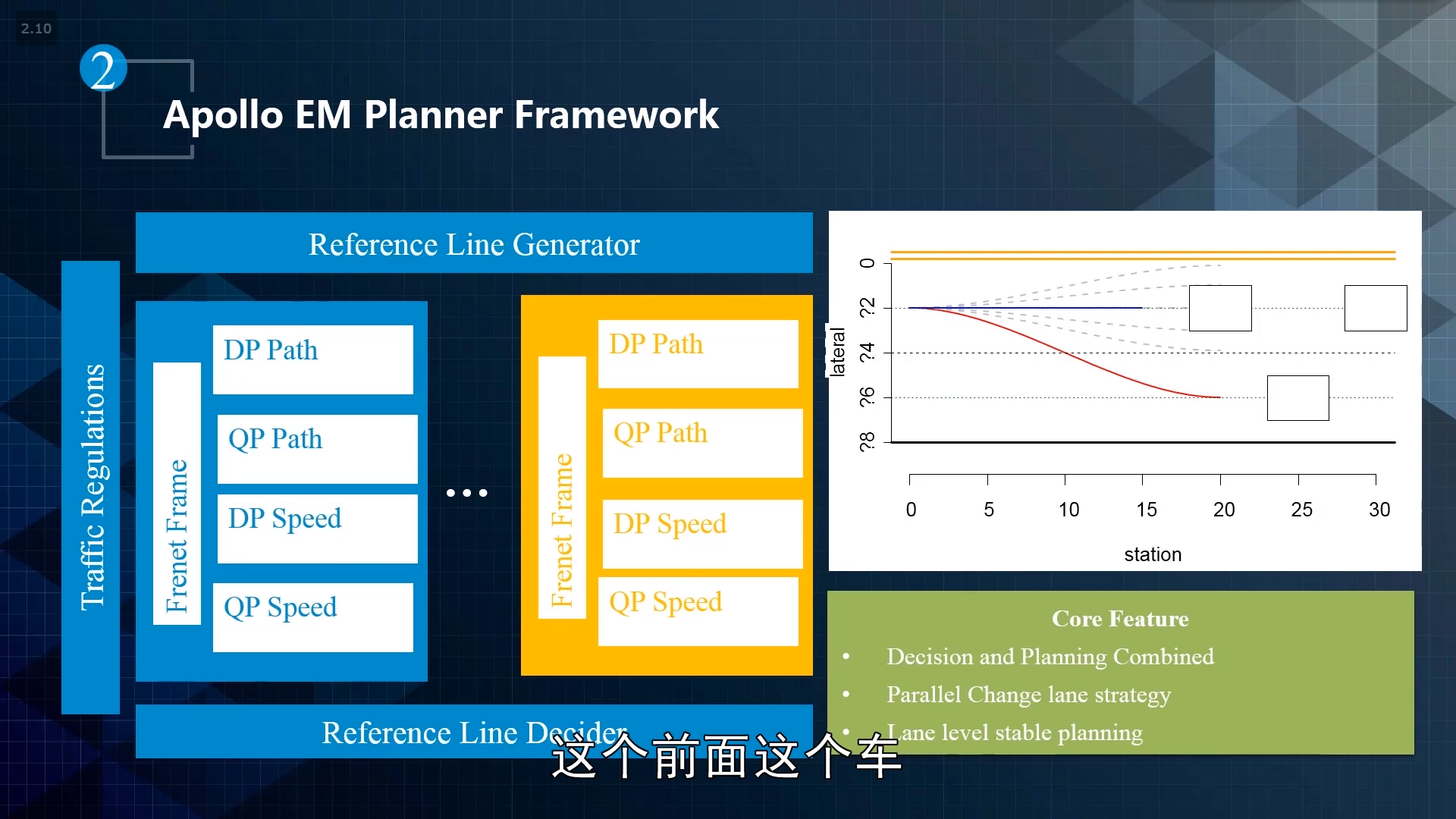
约束:
1.traffic regulations Hard Code regulations
2.Decisions From hard code to DP
3.Best Trajectory Spline Based QP

Apollo EM Planner Framework

path speed iterative的核心:类似于贪心的算法
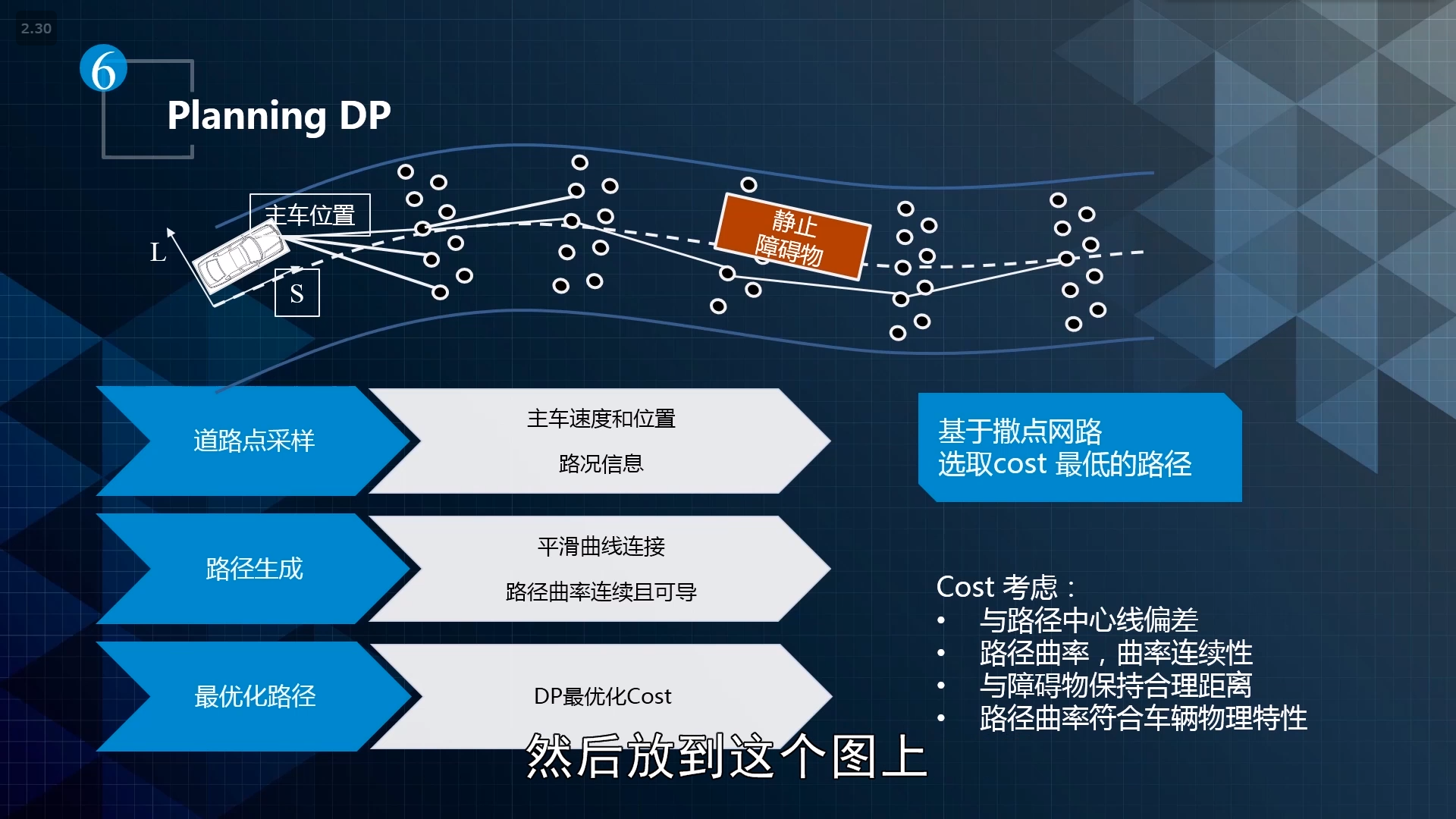
具体的nonlinear 决策规划问题做法:
DP path:
planning path DP
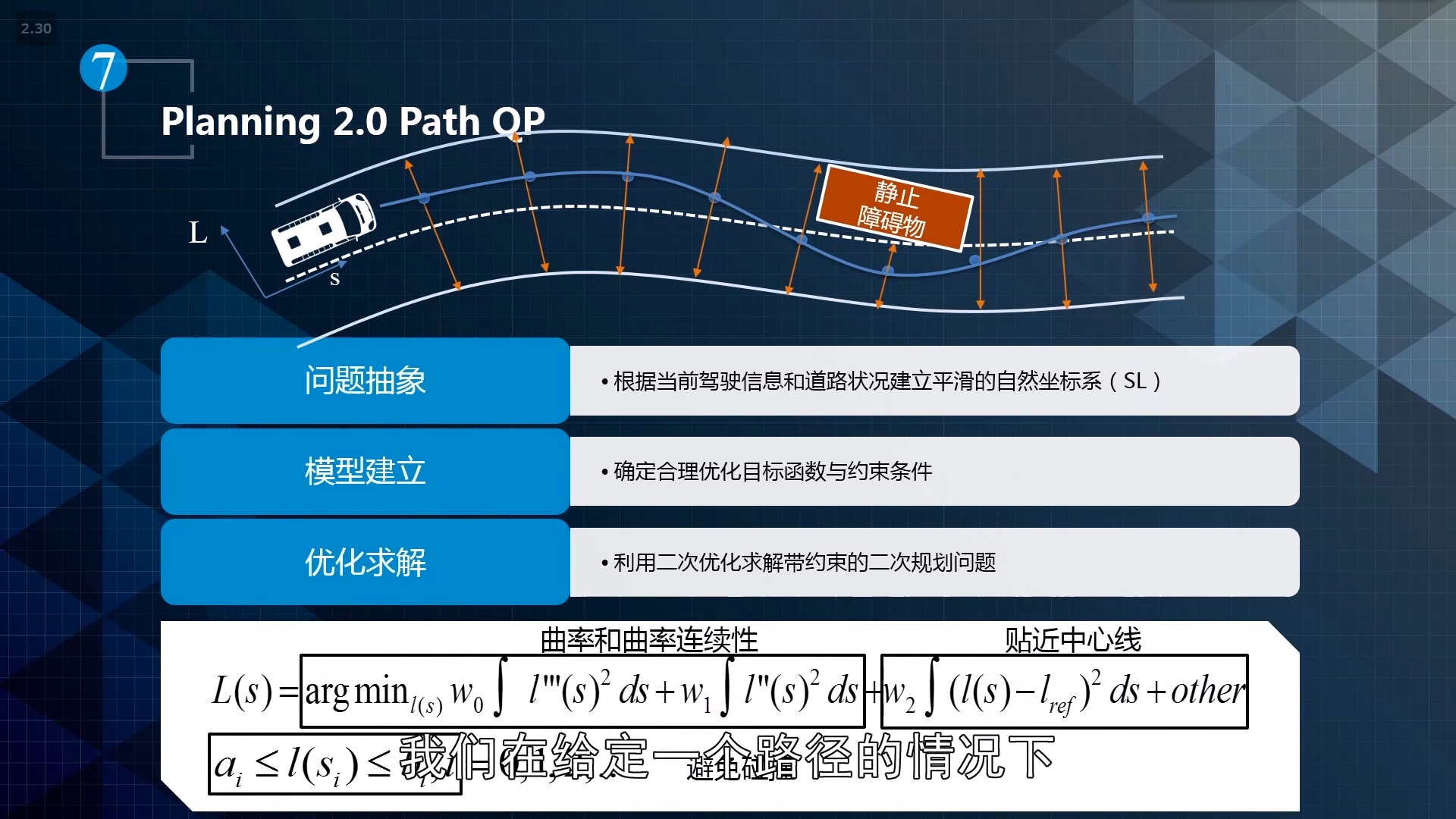
path QP
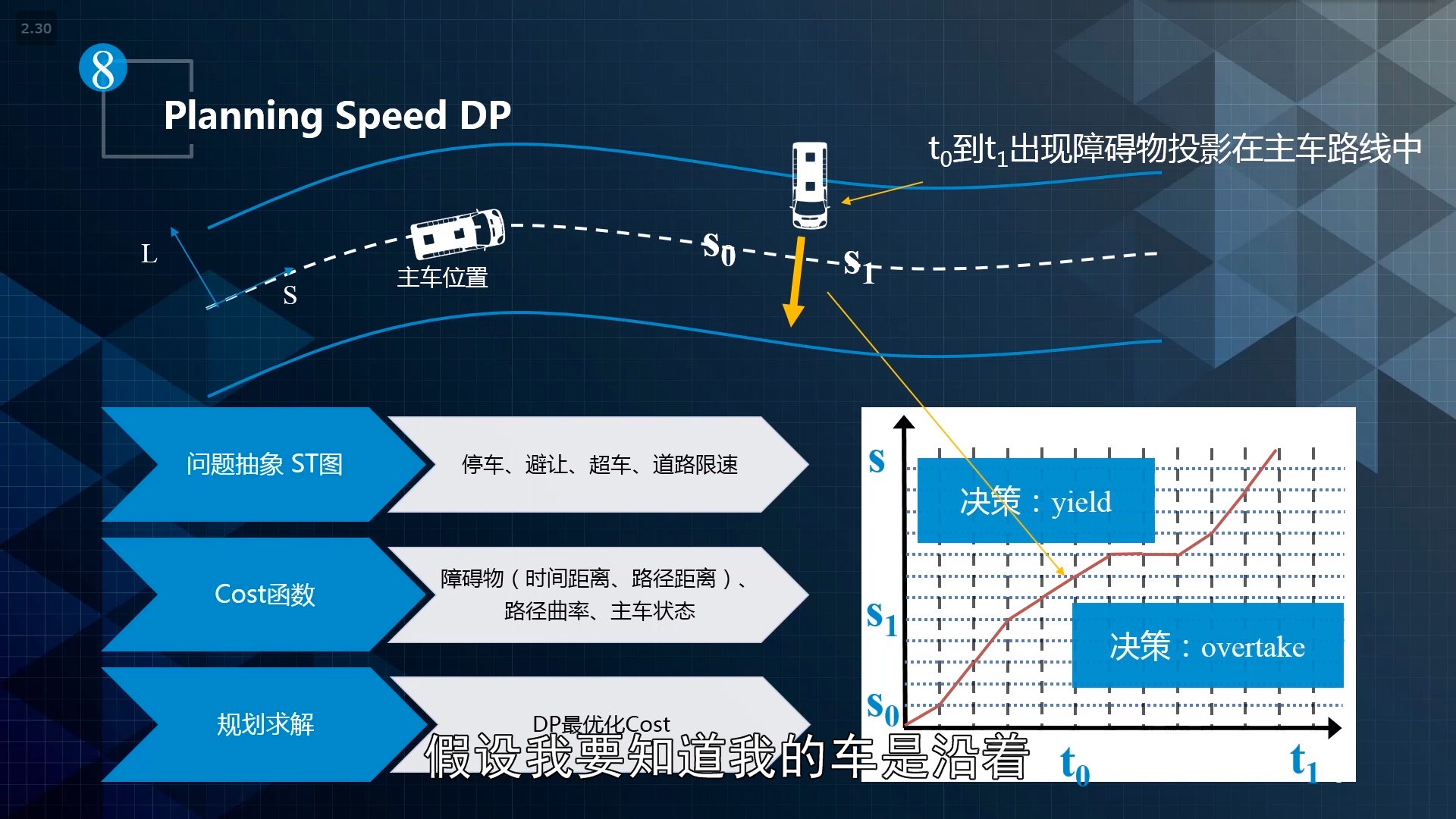
speed DP
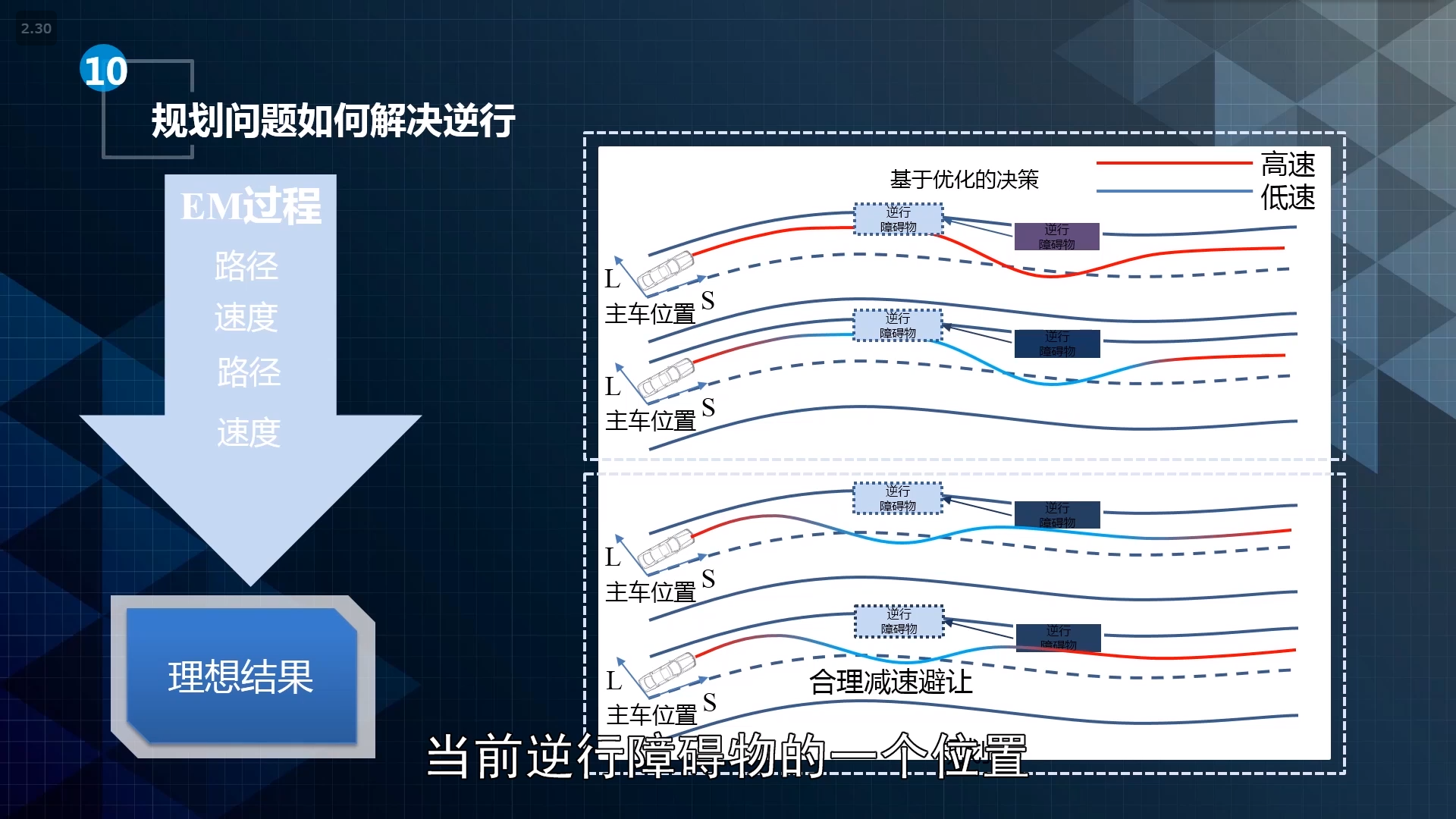
解决逆行问题:
7.reinforcement learning and data driven approaches
rule based->optimization->data driven
Reforce learning: create mapping
不断的实现更好的目标,最终希望通过一个mapping能够优化处理所有的问题
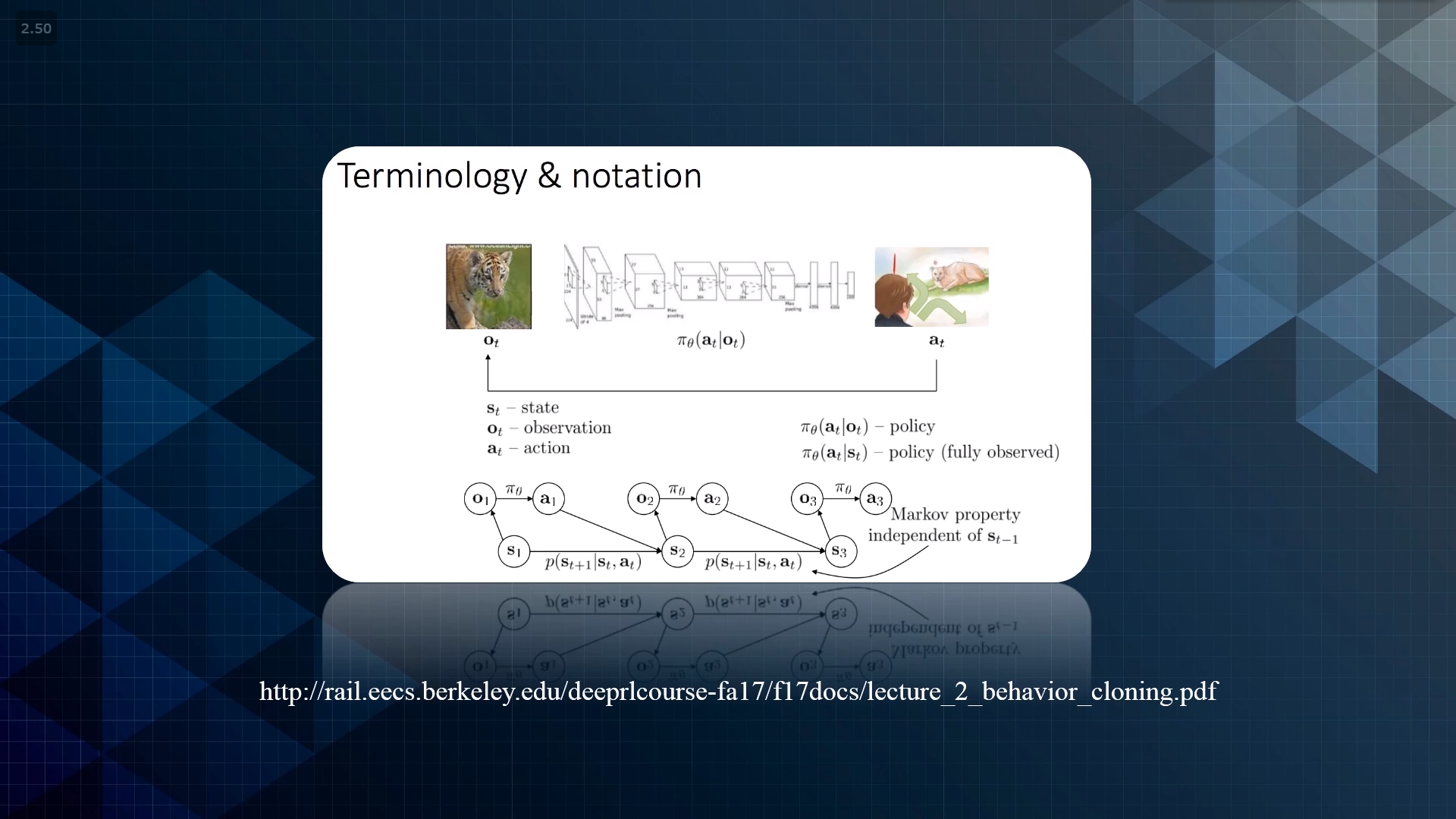
imitation learning
直接的、模仿的过程,然后做出mapping
本质上可以说是一种supervised learning

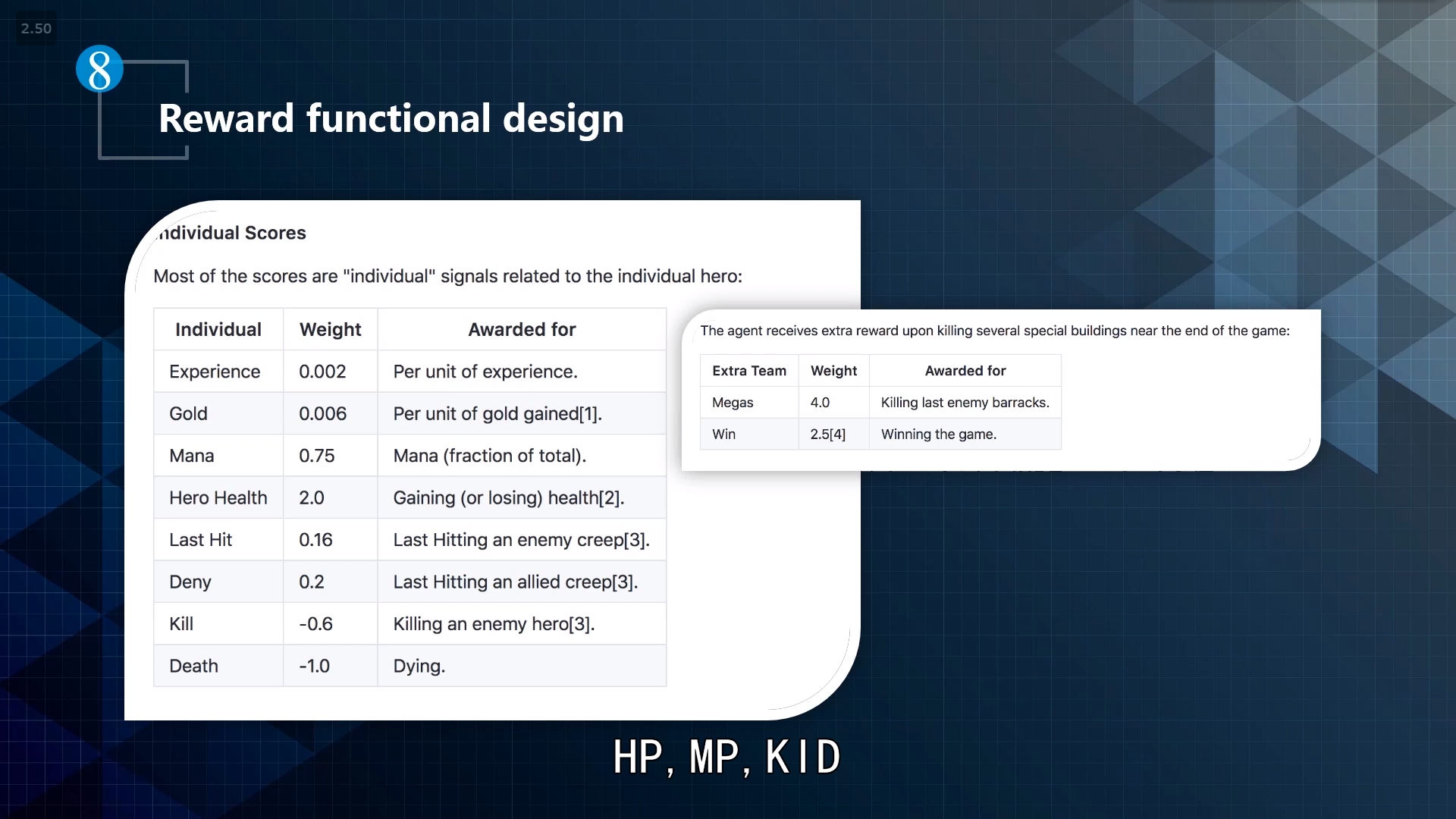
- reward functional design
手动调整
- RL的步骤
通过当前的最优结果去生成一些sample。估计和optimal reward 之间的差距,然后对policy进行一些调整