2019年OO第二单元总结
写在前面
这单元的三次作业,让我感觉收获良多。总体感觉,三次作业中第一次作业很简单,但是让我开始入门多线程;第二次作业和第一次作业在线程控制方面基本不变,但是锻炼了我设计高效算法并且将算法不出bug实现的能力;第三次作业由于有三部电梯,电梯之间存在协同的关系,所以线程控制复杂的很多。同时,为了提高性能,电梯间的协作策略也很关键。这对我们算法设计与实现的能力提出了更高的要求。
接下来,我想从线程控制,程序结构设计和bug的发现与解决三个方面来分析我的三次作业。
1. 线程控制
1.1 总体分析
这三次作业,我的程序结构如下图所示。由于在下一个部分将要分析程序结构的设计,所以这里只介绍我的设计中有关线程的部分。
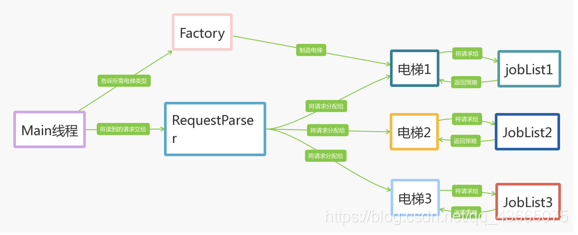
如图,我程序中的线程主要分为两部分:第一个部分是Main线程,其中包括读入请求的Main函数、分发请求的RequestParser(也就是调度器)和可以构建不同种类的电梯的Factory;第二部分是电梯线程。
线程之间的交互过程如下:当一个请求输入时,Main线程会通过RequestParser,按照一定的策略把请求分给相应的电梯。然后判断相应的电梯线程是否isAlive,如果不是,则重新为电梯分配一个线程,并调用start函数将该线程激活。
我的线程设计与其他人的一个非常大的不同是,我没有用线程之间的wait和notify方法,而是通过isAlive函数判断电梯线程是否已经死亡,如果死亡则为其重新创建一个Thread。
这种方法有利有弊,好处有以下几点:
- 程序退出方便。如果用wait和notify的方法,在判断程序是否应该退出时,需要用比较复杂的逻辑判断当前任务是否都已经完成,尤其是第三次作业有多部电梯时。而我这种方法则根本不需要判断,因为当电梯没有任务时,它的线程会自然死亡。所以当所有电梯线程都已经死亡,而且主线程读到null也结束时,程序就会自然地结束;
- 不会有死锁的风险。如果用wait和notify的方法,则在wait和notify之前必须拿到对应对象的同步锁,很容易造成同步锁嵌套获取的情况,从而出现死锁。然而如果用我的方法,当判断到一个线程死亡,需要将其复活时,不需要得到任何同步锁,也就防止了死锁的发生。
当然,这种方法的坏处也很明显:为一个电梯重新创建一个Thread类的代价比notify一个线程大很多。但是经过实验,对于一般的数据,每个电梯线程死亡-复活的次数不会大于3次,所以相对来说代价并不是很大。综合考虑利弊,我觉得这种方法更加安全,于是采用了这种方法。
对于程序中的临界资源,比如每部电梯里的jobList,我用的是每部电梯自己的同步锁来控制互斥。当电梯要从自己的jobList中得到任务时,首先要得到自己的同步锁;当requestParser要往电梯里放入指令时,也要获得目的电梯的同步锁。这样就保证了读写互斥。
从结果来看,这种方法并没有出bug,从一定程度上来说是比较可靠的。
1.2 UML结构图展示线程协作关系

2. 程序结构分析
2.1 总体分析
这三次作业我程序结构大致基本相同,如下图所示:
其中,Main线程读入指令后,将指令传给RequestParser(主要负责指令的拆分与分发),然后RequestParser再按照一定的策略将指令拆分(在多电梯作业里)、分发给电梯。
这一单元的作业,相比于上一单元,我程序的可扩展性好了很多。具体表现在以下几点:
- 使用了工厂方法,针对不同的参数,创建不同的策略的电梯方法,使替换策略变得很灵活;
- 将电梯的调度策略抽象成一个jobList,电梯创建不同的jobList,就对应了不同的调度策略,将电梯的运行机制(上下行、开关门、每层刷新)和策略(调度方法)分离,减少耦合。
在这次作业的编写中,我也发现了一些我代码扩展性不好的地方。例如,在单电梯扩展到多电梯的时候,由于RequestParser拆解、分发任务时要获取更多电梯当前状态信息,这就要求电梯和jobList提供更多的接口。然而,我第二次作业中的电梯和jobList的继承关系如下:


当veryCleverElevator 和 veryCleverJobList要扩展接口时,由于在其他requestParser里,为了保证统一性,用的是Elevator和JobList这两个父类和接口,这就要求在父类和接口里增加新的方法。但是,其他的电梯和JobList原本并不需要这些方法,这时却迫使它们实现这些扩展的方法。当时我由于时间紧张,干脆就把除veryCleverElevator和veryCleverJobList以外的所有类都删掉了。
现在我反思起来,觉得正确的做法应该是让需要扩展的veryCleverElevator多实现一个接口。这一点我将重点在下文的Interface Segregation Principle中分析。
2.2 指标度量分析
(由于方法较多,下图只展示前面有问题的一小部分)


运用idea的第三方插件metrics进行分析,method metrics 和 class metrics 分别如上两图所示。与上个单元作业相比,这次代码结构分析结果有了很大的改善。
然而,一些方法和类的设计仍然存在问题。其中问题最大的,是负责电梯内部方案设计的simulator类。由于我是通过模拟的方法,制定当前最优的方案,而模拟的复杂度比较高,所以我把过程分为了许多层,每一层中有几个方法,上一层的方法调用下一层的方法完成特定的任务。其中代码分层情况如下图所示:


可能是这种分层、上层调用下层的方式,在metrics分析时表现得代码耦合度太高。然而我现在还不知道将如何改进,使每个方法的代码不复杂的同时,尽量减少方法之间的调用。这是我以后课程学习之中需要思考的一个问题。
2.3 SOLID分析
- Single Responsibility Principle
这一次在编写代码时,我特意注意了这个原则。在第二次作业中,由于每部电梯做决策时不需要考虑人员超载和只能停靠特定楼层的问题,所以相对代码实现较为简单,所以我是直接用JobList中的一个函数完成做决策的工作。然而到了第三题作业时,代码量变得多了很多,导致如果直接写在JobList里时,会让JobList类的代码超过300行。于是我将做决策的部分单独提取出来,作为一个新类Simulator,并在Simulator中,将做决策时的过程按照顶层抽象和底层实现的关系,从上到下分为了四层,上层函数通过调用下层函数完成功能。 - Open Close Principle
这一点我有做得好的地方,也有做得不太好的地方。
做得好的地方是,在我扩展RequestParser(也就是调度器)时,我只是增加了在原来单电梯的基础上增加了负责拆分任务、分发任务的功能,分别用一个新增的类和一个新增的方法实现,而没有改动以前单电梯的代码;
做得不好的地方是,在我为我的电梯增加楼层限制、人员限额的特性时,原有的电梯父类和JobList接口所定义的公共方法已经不够用,这就逼迫我去改动以前的代码。这说明我在当初设计时,并没有考虑得很周全,在出现意想不到的需求时,不得不部分地重构。这也是我以后作业中要努力避免的。 - Liskov Substitution Principle 与 Interface Segregation Principle
之所以将这两点放在一起分析,是因为我觉得前者和后者在很大程度上是一个目的和手段的关系。而这一点也是我这次做第三次电梯作业时,很需要反思的地方。
在这次单电梯扩展成多电梯时,由于增加了很多功能与限制,如人员限制、楼层限停等,导致我的电梯类必须扩展很多方法。然而,由于我RequestParser类中用的是电梯的抽象父类Elevator,为了不更改RequestParser的代码,我不得不在Elevator中增加了很多其他的方法,而这些方法对于单部电梯来说根本不必要,但是它们却必须实现这些方法。在做作业时,为了避免麻烦,我直接将以前的单部电梯的代码全部都删除了。
然而,我现在反思起来,当时我的做法违反了这两条原则。正确的做法应该是,为需要扩展的多部电梯的电梯类新增一个接口,把要扩展的方法放到新增的接口中去实现,然后为RequestParser增加一个子类,在这个子类中使用这个新增的接口去获取电梯的新增的信息。这次犯的错误,我在以后的作业中一定会尽可能地避免。 - Dependency Inversion Principle
这一点我做的还算不错。例如,我的调度器分为单部电梯的调度器和多部电梯的调度器,两种调度器都是实现了一个公共的接口,并通过工厂来创建。这就保证了在我从单部电梯转换到多部电梯时,并不需要更改Main函数中的代码,只需要更改传入Factory的参数,即可实现转换。
3. 分析bug
这三次作业中,我找bug主要都是靠自己写的评测机来自动完成,辅以人工构造的数据。机器自动测试相对于人工测试的优势在于,能够构造大量的样例,而且我可以通过更改我的数据生成器改变生成数据的“风格”。当然,人工构造数据也有独到之处,那就是可以人为地构造一些非常刁钻的数据,从边界条件上测试线程安全。
通常在自己完成代码的编写后,我会首先自己构造一些样例,人工检查电梯输出的结果的正确性(防止我的数据检查器有疏漏)。然后会将我的程序在我的评测机上挂一晚上,以不同的概率生成风格不同的随机数据。此外,为了测试性能分,我还会将我自己所实现的不同调度策略一起测试,通过实验来验证哪种方法更为地高效。
在互测阶段,我主要是通过自动评测来进行。因为我的评测机在经过我自己自测时的检验与修改,已经较为地完善,对于有问题的程序,给予足够长的测试时间,基本上可以找到其问题。所以一般我都会将我们房间所有人的程序在我的评测机上挂两个晚上,白天用电脑时也会顺便挂上。这样,我既可以检测别人程序的bug,也可以顺便和各路大神比拼一下性能分。
采用这样的策略,我在三次电梯作业的强测和互测中都没有出过错误,而且在第三次多电梯作业中找到了同屋一位大佬的bug。
心得体会
实现这三次电梯作业的过程,对我来说,是我编程能力的一次新的飞跃。在这三次作业中,我主要有以下几点收获:
- 学会了使用多线程,并且具备了一定的保护线程安全的观念;
- 开始将课上所讲的方法和《设计模式》上的一些模式用于实际,提高代码的可重用性和可维护性;
- 学会了使用python多线程的方法进行定时投放测试。
最后,感谢老师和助教们这三次作业中的辛勤付出!