- 1、什么是天线效应?怎么修复?
- 2、 请说一下memory的摆放规则??
- 3、 Place之后有timing violation,应该怎么办?
- 4、 后端的时序约束相对于综合版本需要修改吗?
- 4、 APR之前需要做什么样的检查?
- 5、做floorplan时要考虑哪些因素?
- 5、route_opt执行哪些步骤?
- 6、APR每一步都干什么?
- 7、在CTS后,如果ICG放在离clock root很近(clock insertion delay很短)的地方,为什么enable信号的setup不容易收敛?
- 8、数字树为什么需要balance?
- 9、什么是闩锁效应,如何解决?
- 10、写个脚本统计人名
- 11、PVT全称是什么?如何影响我们的芯片
- 12、STA和动态仿真的区别?
- 13、STA在什么阶段做,各个阶段的STA都有什么区别?
- 14、如何解决x-talk?
- 15、如何设计PAD Ring?
- 16、分析X-talk后都输出哪些报告和结果?如何利用这些结果改善设计?
- 17、设计的哪些地方容易出现IR-drop的问题?
- 18、什么叫克隆(cloning)和缓冲(buffering),什么情况下用到这2种技术?
- 19、大扇出net的buffer tree和CTS在时序和做法上的区别?
- 20、LEF是什么?与GDS的区别是什么?
- 21、对标准单元所说的9 track和12track是什么意思?(同一种工艺下)这两种单元有什么区别?
- 22、 时钟走线一般用那层金属?
- 23、设置虚拟时钟的作用?
- 24、什么是ESD?在什么地方需要插入ESD 电路?
- 25、DFM包含什么?
- 26、怎么增强FloorPlan和Placement的相关性?
- 27、ICC是怎么计算Congestion的?怎么分析和解决Congestion?
- 28、怎么分析IR-drop?
- 29、在FloorPlan阶段如何去优化timing?
- 30、DC-T怎么做?
上海几大外企数字后端PRAPR面试终极资料!!你懂的!! - 道客巴巴:https://www.doc88.com/p-7408979805181.html
数字后端面试问题:https://blog.csdn.net/mikiah/article/details/7929669
1、什么是天线效应?怎么修复?
在芯片生产过程中,暴露的金属线或者多晶硅(polysilicon)等导体,就象是一根根天线,会收集电荷(如等离子刻蚀产生的带电粒子)导致电位升高。天线越长,收集的电荷也就越多,电压就越高。若这片导体碰巧只接了MOS 的栅,那么高电压就可能把薄栅氧化层击穿,使电路失效,这种现象我们称之为“天线效应”。
跳线,而且最好是往上跳线
增加对地反向偏置diode,
在信号线上加一组buffer,这个方法既可以规避antena,也可以为信号增加驱动能力
2、 请说一下memory的摆放规则??
调整Macro的位置、摆放方向,注意出Pin的方向,为出pin的区域留出足够的空间,避免产生狭窄的通道。另外当多个Memory共用相同的数据线或者地址线时,可以调整它们的位置,使它们的Pin对齐,这样连线会比较规整,对Congestion有帮助。
3、 Place之后有timing violation,应该怎么办?
出现timing violation后的第一步是分析那条path,找出违反的原因,然后才是解决办法。造成timing violation的原因很多,随便列几个常见的,
(a)clock tree不平衡:CTS的定义有错误;不合理的FF位置,比如,放在了一个很细很长的通道中。利用useful skew消除setup违反
(b)起始FF与终点FF的距离太长:用group把它们拉近
(c)xtalk的干扰:加大线间距离,不要用infinit timing window算xtalk
(d)detour走线造成的大的延迟:解决congestion问题
(e)fanout太大:忘记set_max_fanout,或者设定不合理,或者对某些net set_dont_touch了
(f)单元的驱动能力太小:upsizeing cell,去掉大驱动能力cell的dont_use属性,检查是否局部placement太密,没有空间sizeup了;或者换阈值,HVT-SVT-LVT
(g)hold timing violation与setup violation同时存在,工具无法做了。这种情况多半是SDC的问题,很少是真的,除非那是一个非常特殊的IO timing
后端修timing的一些手段:
setup https://zhuanlan.zhihu.com/p/32713278
hold https://zhuanlan.zhihu.com/p/34254237
4、 后端的时序约束相对于综合版本需要修改吗?
有时需要,
如果综合时使用了过小的clock period,要还原回来
可以去掉SDC里面的wire load, operation condition, ideal net, max area
有些为综合而设置的dont_touch, dont_use
有些为综合而设置的clock latency
4、 APR之前需要做什么样的检查?
检查所有库是否一致,版本是否一样,使用单位是否一样,是否有重名
用zero wire load model 来 report timing,结果应该和同样条件下DC/RC的结果非常一致
check timing 保证所有的单元都有约束
check design,不能看到任何input悬空,不能有3态门以外的ouput短路
5、做floorplan时要考虑哪些因素?
IO的排放顺序
power和IR-drop
模拟信号与数字信号的隔离
内部数据的流向
macro的面积和连接
critical timing模块的距离
congestion模块的走线资源
5、route_opt执行哪些步骤?
(a)Global Routing
GR将net分配给特定的金属层和global routing cells(Gcells),这一步没有实际布线
(b)Track Assignment
TA将每条net分配到特定的track,并且布下实际的金属线,TA不检查或遵守物理设计规则
(c)Detailed Routing
DR fix物理设计规则违规
6、APR每一步都干什么?
place之后,只优化setup。使用粗糙的RC抽取,global route
CTS之后,可以只优化setup,也可以优化setup和hold。使用粗糙的RC抽取,global route,如果clock net 已经route过了,clock就用detail route的结果。 时钟走线要double width和double space,高速(>500MHz)时钟要shielding
route之后,要优化setup和hold
7、在CTS后,如果ICG放在离clock root很近(clock insertion delay很短)的地方,为什么enable信号的setup不容易收敛?
因为一般enable信号来自某个FF,那个FF是clock tree上的一个叶子节点,那么到FF的clock path就是整个clock tree的delay(假设skew很小),而那个ICG的clock path不足一个clock tree的delay,当然就容易出现setup的违法了。也就是launching path太长, capture path只是clock path的部分(因为icg)的原因造成的,
这也就是icg 放的位置的tradeoff问题,
放的前面(high level), clock gating的效果好,可以关断更多的flops, 但是setup timing难收敛
放在后面(low level) , timing好收敛, gating效果一般
一般都是有多级ICG,可以控制各个级别的gating, tradeoff一下
icg 时钟⻔控单元,是 clock tree 的⼀部分。icg 的 clk pin 在路径中默认为 non-stop pin (ignore pin),即不会和其他 sink reg 或者 ram 的 clk pin 做 balance。 因此, 从 icg 的 Q pin 到 sink reg/ram 的clk pin 之间的延时, 就成为了 icg 和 reg/ram 之间天然存在的 skew。 极易导致 icg 的 setup 问题。⽽在 cts 之前, icg ⽆法被⼯具看到, 因此这部分延时在⼯具做 timing 分析时候会被忽略。 所以reg2icg 或者 ram2icg 的路径优化过于乐观, 导致 datapath 很⻓。 当后续 cts 看到 icg 之后, launch clock + datapath更⻓,对setup⾮常不利且很难修掉。因此,place阶段需要对icg进⾏overconstrain,引导⼯具考虑实际存在的 clock tree delay, 将 datapath 做短。
做法是在 icg 的 clk pin 上进⾏设置⼀段负的延时(set_clock_latency), ⽬的是告诉⼯具, 这边实际存在⼀段延时, 需要在 timing 分析时候在 capture 端加上⼀个负延时, 使得 setup 约束更紧,从⽽把 datapath 做短。在 place 之后, 这段 latency 需要 remove 掉, ⼯具会使⽤实际的 clock tree 来进⾏优化。对于 place 阶段的, icg overconstrain 来说, 对 reg2icg 和 ram2icg 等 to icg 的路径⽣效, 其他类似 reg2reg 的路径, 实际上 launch 和 capture 上的 overconstrain 会抵消掉, 因此没有影响。
8、数字树为什么需要balance?
对于快速设计,时钟树的skew和latency影响时序收敛、功耗和面积。balance 可以使得timing收敛简单些
对于慢速设计,时钟树的skew和latency对时序收敛的影响重要性下降。但是对于skew大的时钟树,工具修复时序会增加更多的面积和功耗。创造一个skew小的时钟树,虽然看似在时钟树上多用了buffer,但是会减少在修复时序问题时需要的buffer
所以,一个balance对于时序收敛、面积和功耗都是有好处的。
除了PPA(performance、power、area)之外,时钟树还应该robust。即所谓设计中的时钟树在任意设计需求的corner下都能满足时序。这点对提高良率的意义重大。
考虑OCV等因素后,对称使得时钟树更加强壮。到达每个Reg的时钟路径拓扑结构、级数和Inverter/Buf都一样是最理想的。(不考虑usefull skew的需求)
使用专用的、较少的Inverter/Buf也可以降低OCV对时钟树鲁棒性的影响
9、什么是闩锁效应,如何解决?
闩锁效应是CMOS工艺所特有的寄生效应,严重会导致电路的失效,甚至烧毁芯片。闩锁效应是由NMOS的有源区、P衬底、N阱、PMOS的有源区构成的n-p-n-p结构产生的,当其中一个三极管正偏时,就会构成正反馈形成闩锁。避免闩锁的方法就是要减小衬底和N阱的寄生电阻,使寄生的三极管不会处于正偏状态。
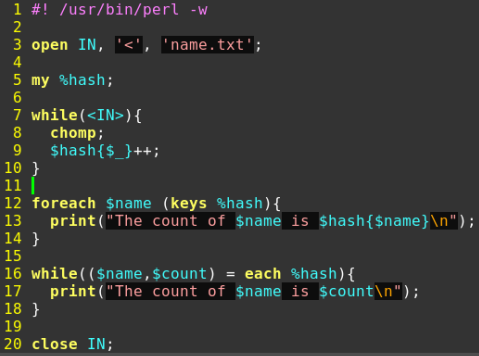
10、写个脚本统计人名
11、PVT全称是什么?如何影响我们的芯片
Process: FF,FNSP,TT,SNFP,SS
Voltage: 电压降低,延时变大
Tenperature: 具有温度反转效应,工艺在90nm以上的时候,随着温度的升高,delay增大,所以worst corner是PVTmax,但是65nm以下,随着温度的降低,delay也会增大,worst corner可能是PVTmax,也可能是PVTmin,这就是温度反转效应(Temperature Inversion Effect)

12、STA和动态仿真的区别?
第一点是激励波形,STA是不需要的激励波形的,但是需要SDC(Synopsys Design ConstrAInt,时序约束), 而时序仿真时严重依赖激励波形的;第二点是完整度,STA能够对数字电路中所有的时序路径进行全面的检查,而时序仿真在覆盖率上有一定限制;第三点是效率,STA的比较简单,速度更快,而生成仿真需要的激励,建立仿真环境可能费时费力;第四点是鲁棒性,STA能够考虑到电路中串扰噪声以及OCV(On Chip Violation, 片上偏差)的影响,提高芯片制成后的良率,而时序仿真做不到这一点。
13、STA在什么阶段做,各个阶段的STA都有什么区别?
| 阶段 | place | cts | route |
|---|---|---|---|
| clock设置 | ideal clock | propagated clock | propagated clock |
| clock uncertainty -max | skew+jitter+margin | jitter+margin | jitter+margin |
| clock uncertainty -min | skew+margin | margin | margin |
| 关注点 | setup | setup+hold | setup+hold |
14、如何解决x-talk?
1)upsize victim net driver, downsize aggressor net driver
2)increase wire space, shielding, change layer,change wire width
3)insert butter in victim net
能答出以上3条的,在工作中已经基本够用,但是还有两个不常用到的,是AMD的一个大牛告诉我的。
4)把与victim net相连的输入端改成Hi-Vth的单元
5)改变信号的timing window。这个不易做到,但是也是解决方法
15、如何设计PAD Ring?
大的流程是:
1)根据系统(其他芯片的)要求,芯片内部的floorplan,决定信号PAD的位置
2)计算出power PAD的个数,插入到信号PAD里面
3)加其他的PAD,比如IO filler,powercut,power on control,corner PAD,ESD等
细节可以包括:
1)如何计算core power PAD:估算corepower,再加50%,算出电流,除以每个core power IO的最大电流,就是大致的PAD个数。插入到信号PAD ring后,还要再计算powerEM,防止一根电源线上的电流过大。
2)如何计算IO powerPAD:从信号IO的功耗算起,同时计算SSO,取2个结果里面较大的
3)在什么地方插入powercut:不同的core电压和不同的IO电压之间,power island之间,数字和模拟电源之间。
4)power on control PAD,一般每个IOring需要一个
5)ESD一般要加在每个不同的电源之间
16、分析X-talk后都输出哪些报告和结果?如何利用这些结果改善设计?
X-talk的分析结果中,至少要包含X-talk glitch和X-talk delay 的报告和数据,
可以把glitch报告读回到P&Rtool里面,让tool自动解决这些问题,也可以手动
X-talk delay就是incrementaldelay,反标回网表中以后,再做一次时序优化
17、设计的哪些地方容易出现IR-drop的问题?
1)从电源布线的角度看,那些远离电源端的地方,布线少的地方,比如wire bond芯片的中间,flip chip的四角
2)从switching activity的角度看,toggle rate高并且celldensiy高的地方IRdrop大,频率高的地方动态IR drop大
18、什么叫克隆(cloning)和缓冲(buffering),什么情况下用到这2种技术?
cloning:有多个sink的情况下,不改变逻辑功能把当前cell复制一份,分别驱动下一级的cell,这样可以减少当前单元的负载,从而获得更好的时序,缺点是会增加上一级的负载
buffering:不改变信号的情况下对信号再生,提高它的驱动能力,通常是两级反相器构成,可以提高电路的运行速度,有时也用来当延时单元,特点是不会增加上一级的负载
在多个sink的时序都比较紧的情况下适合用cloning,如果sink对timing的要求区别挺大的,一部分时序较紧的由上一级直接驱动,剩下的可以加一级buffer后驱动
19、大扇出net的buffer tree和CTS在时序和做法上的区别?
buffer tree和clocktree的共同点是它们都是解决high fanout net的问题,只不过要求不同而已
buffer tree要求满足maxtrans/fanout/cap,有时还要满足setup/hold timing
clocktree不但要满足上面的所有要求,还有skew,max/min latency的要求
20、LEF是什么?与GDS的区别是什么?
LEF是一种简化版的GDS,它只包括size和metal层有关的信息,比如pin,blockage等,其他baselayer的东西只在GDS里面可以看到。
同时LEF还有一些GDS里面没有的信息,比如,metal的R,C,routing and placement rule等
LEF是一个文本文件,可以修改编辑。GDS是二进制文件,比较难修改
21、对标准单元所说的9 track和12track是什么意思?(同一种工艺下)这两种单元有什么区别?
一般site width就是metal 2 pitch,比如SMIC18 的 0.56 x 5.04 , 0.56 就是metal 2pitch,
因为std cell pin基本上都是由metal 2连接出来的,高度一般都是 site width的整数倍,比如7, 8, 9 ,10 ,12 倍,也就叫做7/8/9/10/12 track单元,比如 0.56 x 5.04 的就是9 track, 0.56 x 3.92 的就是 7 track,0.2 x 2.4 ( SMIC 65 ) 是12 track, 0.2 x 1.8 ( TSMC65) 是9 track,
一般来说9 track是 属于标准size,7 track属于小size,也就是低功耗一些,速度慢些,10、12 track 是高速,一般 metal1的rail做的更宽,管子好像没啥区别,rail做的宽自然能走更多的电流,自然速度就快了功耗大了,有的还添加metal2 rail比如65nm以下的库,这样速度更快了,选几个track 是由设计目标决定的,如果简单些 ,就选9track标准带tap的,比较方便低功耗选7 track,timing不够就选12 track的,
22、 时钟走线一般用那层金属?
假设共有8层金属层
最底层M1/2一般很薄,走线宽度最小,RC一般最大,而且会被cell的pin占去很多资源,肯定不适合做clockwire。
最高1/2层M7/8一般很厚,走线宽度大,RC很小,适合大驱动的clockbuffer走线。如果是用铜做金属层的话,最上面还会有一层极厚的铝金属层,一般不用做信号线的走线。
中间几层M3/4/5/6的厚度,宽度都适中,如果使用doublewidth,double space的走线的话,RC也比较小,也可以做clock wire。
如果考虑到VIA增加的电阻,一味地使用最高层不一定会得到最快的clocktree。
但是一般信号走线大多是先用下层的金属,所以建议根据各层的RC和整个设计的congestion来选择clockwire的层数。
如果最高1/2层M7/8的RC远小于中间几层M3/4/5/6的RC,就选最高1/2层
如果最高1/2层M7/8的RC与中间几层M3/4/5/6的RC相差不大,在很拥堵时,还是选最高1/2层;不太拥堵时,选中间几层里面的高层M5/6;根本没有拥堵时,用中间层里面的底层M3/4
23、设置虚拟时钟的作用?
上图是一个block (不是chip),问
1)有多少timing path?
2)place之后,假设setup和hold都正好为0ns,然后插入时钟树,树的完全平衡的,WC的时钟树insertiondelay是0.2ns,BC的insertion delay是0.1ns,这时做STA,会看到timing violation吗?有多少条violation,各违反了多少ns?他们是真的吗?如何解决?
答案:input hold -0.1, output setup0.2
如何修复违法是有些难度的问题,
简单的回答是:
在input delay上加clock insertiondelay的值(BC 0.1 WC 0.2),
在output delay上减去clock insertiondelay的值(BC 0.1 WC 0.2)
但是当有上千个input和output port时,做起来比较麻烦,有个非常简单的方法,想到了,就是满分!
设一个虚拟时钟,与clk同频同相,把所有input,output delay都指定到那个虚拟时钟上,CTS后,只要在虚拟时钟上加上(BC 0.1 WC 0.2)的latency就好了
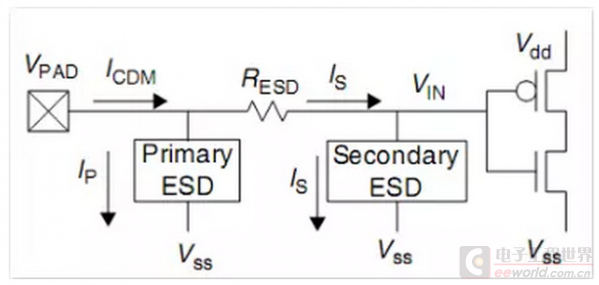
24、什么是ESD?在什么地方需要插入ESD 电路?
ESD(Electro-Static discharge)指静电释放,一般在IO 的Input 加ESD电路,在IC的测试、封装、运输、使用等过程中可以把静电有效泄放避免对CMOS 栅极的损伤,从而有效地保护IC。
二极管有一个特性:正向导通反向截止(不记得就去翻前面的课程),而且反偏电压继续增加会发生雪崩击穿(Avalanche Breakdown)而导通,我们称之为钳位二极管(Clamp)。这正是我们设计静电保护所需要的理论基础,我们就是利用这个反向截止特性让这个旁路在正常工作时处于断开状态,而外界有静电的时候这个旁路二极管发生雪崩击穿而形成旁路通路保护了内部电路或者栅极(是不是类似家里水槽有个溢水口,防止水龙头忘关了导致整个卫生间水灾)。PN结的击穿分两种,分别是电击穿和热击穿,电击穿指的是雪崩击穿(低浓度)和齐纳击穿(高浓度),而这个电击穿主要是载流子碰撞电离产生新的电子-空穴对(electron-hole),所以它是可恢复的。
25、DFM包含什么?
后端主要是double via, spead wire width/space, 还有add dummy metal,使metal desity更均匀
26、怎么增强FloorPlan和Placement的相关性?
可以使用命令create_fp_placement、legalize_fp_placement来执行VF(Virtual Flat)Placement,提高floorplan对congestion和timing的影响
它的特点是:
(a)标准单元和non-fixed的macro被legally place
(b)摆放默认是wirelength驱动的
(c)不作逻辑优化
(d)默认执行hierarchy-aware摆放

27、ICC是怎么计算Congestion的?怎么分析和解决Congestion?
用穿过GRC(global routing cell)的nets数目除以GRC中可供使用的routing tracks
分析:
(a)使用命令report_congestion -grc_based -by_layer -routing_stage global生成congestion map(heat map)来进行可视化,map上越红越亮的地方表示阻塞越大
(b)对比cell density map和congestion map,如果两者有一致性的话,可能是High cell density引起了阻塞
解决:https://www.cnblogs.com/wt-seu/p/12812651.html

28、怎么分析IR-drop?
1、指定(a)Power/Ground net pair和target IR-drop,(b)power budget,(c)power pad information后,做PNS(power network synthesis),synthesize_fp_rail。通过IR-drop heat map进行可视化,帮助分析,analyze_fp_rail。
2、如果不满足target IR-drop,修改power network约束重新综合。
3、可以创建Virtual Power/Ground pads进行分析,如果添加新的pad有用且必要的话,那就重做floorplan,加入更多的power pad cell
29、在FloorPlan阶段如何去优化timing?
执行in-place优化,optimize_fp_timing -fix_design_rule <-effort high>
具体地:
(a)cell sizing,buffer insertion,AHFS(Automatic high fanout synthesis)
(b)改善timing和DRC违规
(c)合法化placement
如果timing仍然不可接受,就修改Floorplan,或者修改设计约束或partitioning重新综合(DC-T)

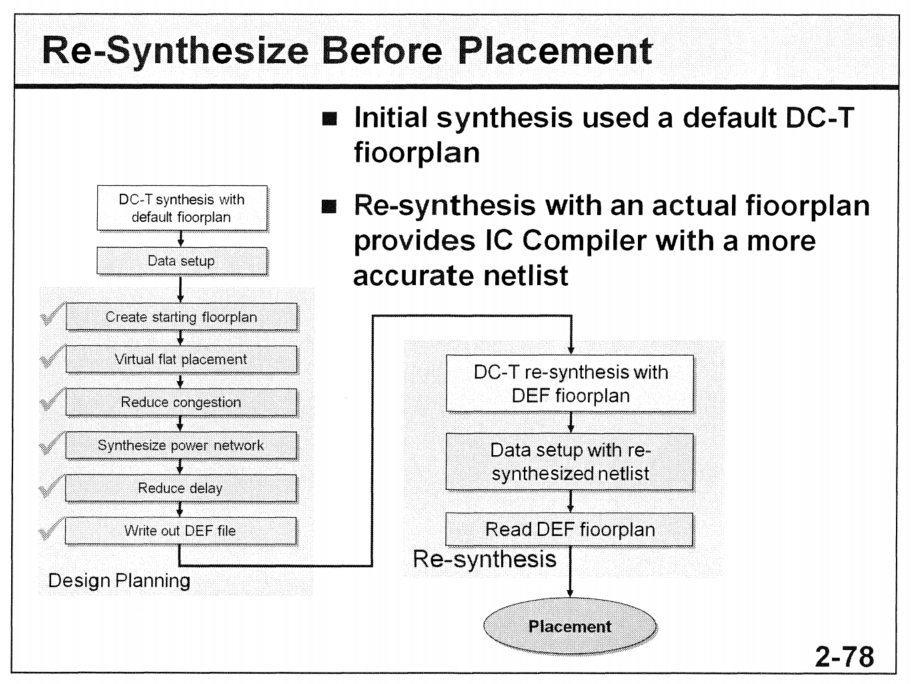
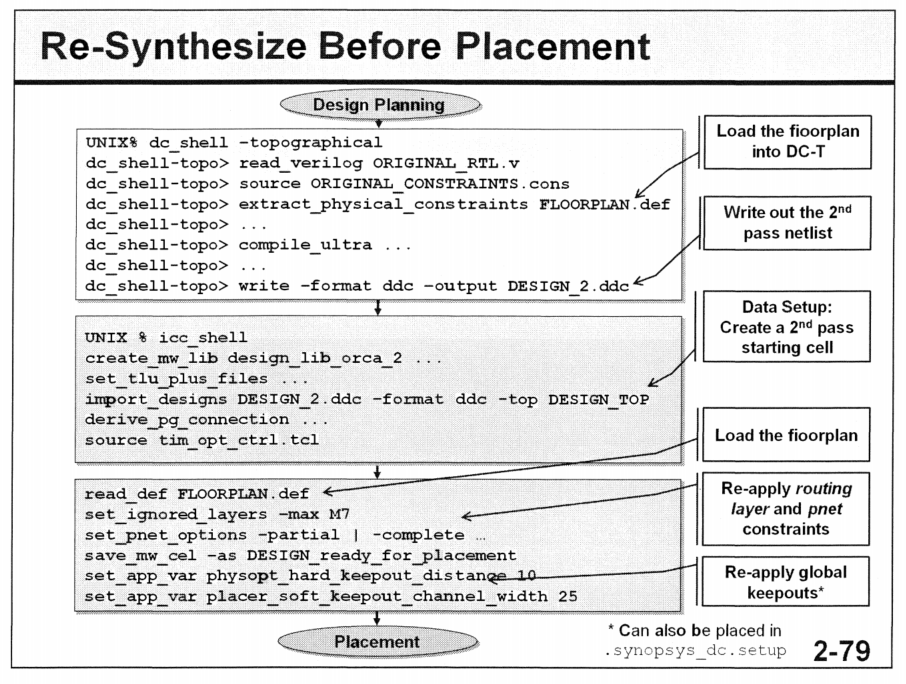
30、DC-T怎么做?