Linux内核中的虚拟文件系统用来管理挂接各种具体文件系统。具体的文件系统可设计成可加载模块,在系统需要时进行加载。
挂载具体文件系统时,VFS读取它的超级块,得到具体文件系统的拓扑结构,并将这些信息映射到VFS超级块结构中。
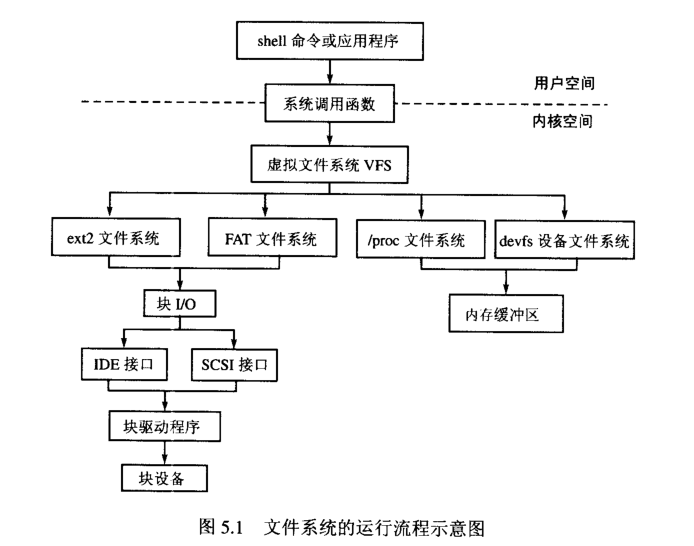
当进程或shell命令访问目录和文件时,shell命令及应用程序分解成系统调用,系统调用进入内核空间,遍历虚拟文件系统的VFS节点(inode),而VFS节点指向了具体文件系统的节点。通过底层块I/O函数调用IDE接口,再通过块驱动程序访问块设备(如硬盘),得到文件数据。文件系统的运行流程如图所示。
1 VFS的超级块、dentry和节点结构
Linux的目录和文件实际上都是一种文件,目录应称为目录文件,一个目录文件就是一个目录项的列表,其中的每一个目录项都有一个数据结构来描述。每个目录的头两项总是标准目录项“.”和“..”,分别指向目录、父目录的inode。
VFS超级块
VFS超级块是在这些文件系统中描整个文件系统信息的全局数据结构。VFS超级块是各种逻辑文件系统在安装时建立,并在这些文件系统卸载时自动删除。可见,VFS超级块确实只存在于内存中。
超级块结构super_block列出如下:


dentry
为保持从目录访问inode的高效率,Linux维护了表达路径与inode对应的关系的dentry结构。dentry结构描述了路径信息并链接到结点inode。每个文件有一个dentry结构,被文件系统使用过的目录将会存入dentry结构中。这样,同一目录被再次访问时,可直接从dentry中得到,不必重复访问存储文件系统的设备。
dentry结构列出如下:

inode
VFS中的每个文件、目录文件等都有惟一的VFS inode表示。每个VFS inode中的信息通过文件系统从实际文件系统中得到。
结构inode列出如下:


2 与进程联系的文件系统相关结构
进程是通过文件描述符而不是文件名来访问文件的,文件描述符实际上是一个整数,规定每个进程最多能同时使用NR_OPEN个文件描述符,这个值在fs.h中定义为256.每个进程用一个file_struct的结构来记录文件描述符的使用情况,它是进程的私有数据。
每个文件都有一个32位的整数来表示下一个读写的字节位置,即文件位置。每次打开一个文件,默认是从文件的开始处操作,可以通过系统调用lseek对这个文件位置进行修改。
在进程的task_struct中的文件系统相关的数据成员,列出如下:

结构fs_struct给出了文件系统信息,列出如下:

结构files_struct是用户打开文件描述符表,它给出了文件描述符的使用情况,其file结构成员给出了每个文件描述符的信息,结构files_struct分析如下:


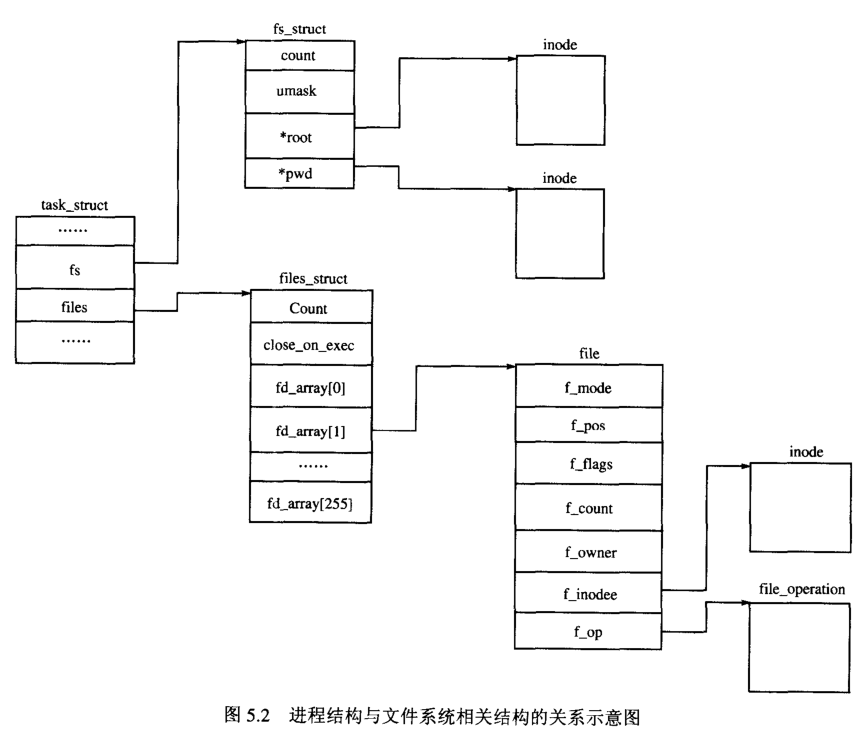
结构files_struct中成员fd_array主要是一个256项的file结构数组,数组的下标是文件描述符,而其内容就是对应的file结构。在一个进程启动后,文件描述符0,1,2,已经被分配并可供使用:0表示标准输入设备,1表示标准输出设备,2表示标准错误输出设备。所以,能使用的第一个文件描述符是3.
结构file保存打开文件的信息,通过文件描述符查找文件描述符数组fd_arrayfile可得到file结构。结构file分析如下:

3 系统有关操作函数集的结构
VFS毕竟是虚拟的,它无法 设计具体文件系统的细节,所以,必须在VFS和具体结构文件系统之间有一些接口。VFS的数据结构就好像是一个标准,具体文件系统要想被Linux支持,就必须提供VFS标准应具有的结构及操作函数。实际上,具体文件系统在使用前,必须将自己的结构及操作函数映射到VFS中,这样才能被访问到。
super_operatirons
结构super_operations是对文件系统超级块进行操作的函数集。这个结构分析如下:


inode_operations
结构inode_operations定义了节点的操作函数集,分析如下:

file_operations
结构file_operations中存有对文件进行操作的函数,这个结构分析如下:


4 文件系统的各种缓存
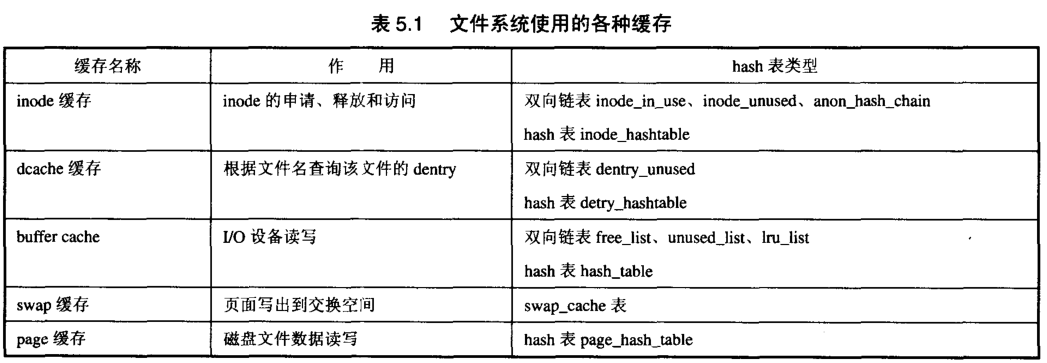
Linux能支持多种文件系统并且保持很高的性能,这是因为文件系统有各种各种的缓存,组织成了各种hash表,有效地提高了访问速度。文件系统使用的各种缓存如下:
块缓存buffer
为加速对物理设备的访问,Linux维护一组缓冲区,用做对块设备上的数据的块缓存。需要使用块设备上的数据时,系统把数据块调入块缓存中。下次再访问该数据块时,不必访问物理设备了。常用的数据块会一直留在块缓存中,这样减少了访问设备的时间。
Linux以struct buffer_head规定的数据格式封装缓存。buffer_head结构对块缓存进行管理,多个块缓存组成了块缓存页,每页中的块缓存buffer_head结构形成了一个环形链表,页的私有数据指针指向这个环形链表的头部。
结构buffer_head包含了用于描述缓冲区内容的信息,例如,所在设备号,起始物理块号,包含在缓冲区的字节数,还包含了缓冲区状态,例如,是否有用数据,是否正在使用,重新利用之前是否要写回磁盘等。
结构buffer_head分析如下:


块缓存独立于任何类型的文件系统。文件系统中凡涉及磁盘读写,几乎都要通过块缓存;有些甚至直接利用缓冲区缓存保存信息。
每个块缓存由两部分组成:第一部分称为块缓存首部,用数据结构buffer_head表示;第二部分是块缓存数据区,结构buffer_head与块缓存数据分别存储,结构buffer_head用b_page来指明数据区所在的页,b_size表示数据的大小。