作业链接地址:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139
一、效能分析
要求0:GIT仓库地址:https://git.coding.net/wudb527/wfAnalysis.git
要求1:第一次分析消耗时间(原来没有使用命令行作参数,此时经过了稍稍修改)


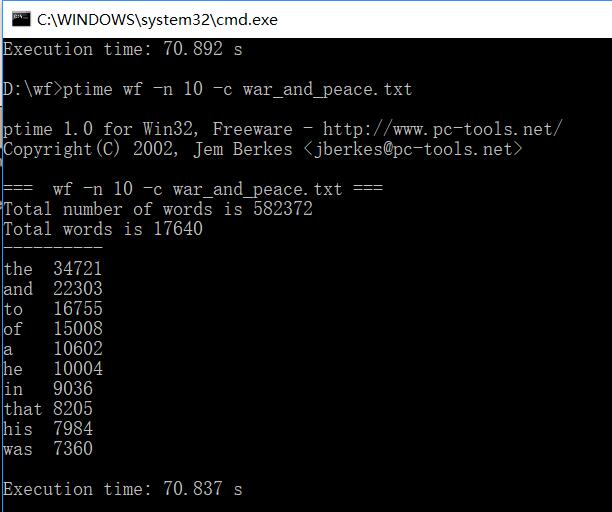
三次消耗时间整理如下:
| 次数 | 耗时(s/秒) |
| 第一次 | 70.991 |
| 第二次 | 70.892 |
| 第三次 | 70.837 |
| 平均 | 70.907 |
瓶颈猜测一:在打开文件之后,我是将文件内所有的字符拼接为一个string类型的串(如下):
1 ifstream infile; 2 string file_txt = "", str; 3 infile.open(File_Name.c_str());//打开文件 4 while (getline(infile, str)) 5 { 6 file_txt = file_txt + str + ' '; 7 } 8 infile.close();
而当文本非常大是,所拼接操作的字符串也会非常大,我觉得会造成严重的耗时。
瓶颈猜测二:在将字符串按照空格分割时,我使用的是sstream 里的stringstream,这等于又进行了一次输入,花费了时间
stringstream ss(file_txt);
while (ss >> str) { if (str[0] >= '0' && str[0] <= '9') continue; Max_wordsize = Max(Max_wordsize, str.size());//寻找最长单词的长度 if (Map[str] == 0) Vstr.push_back(str);//把每一个单词不重复的保存起来 Map[str]++; ++sum_word; }
要求2:性能分析

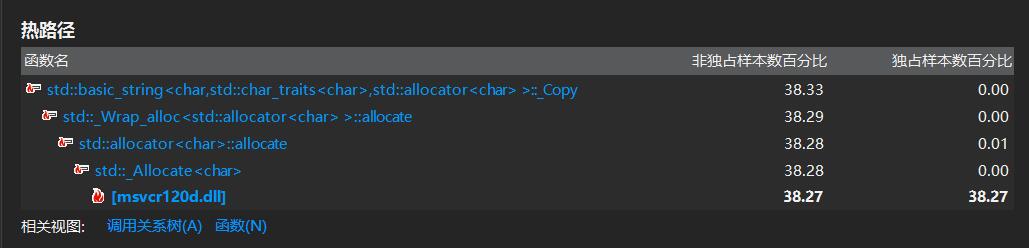
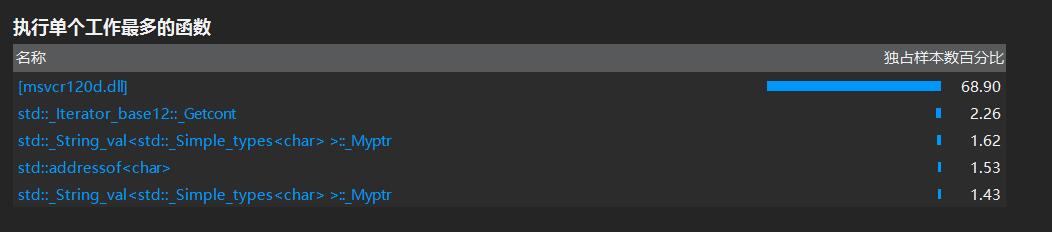
最耗时的三个代码片段



分析:
(1)正如猜测的一样,在代码拼接时消耗了太多时间
(2)用stringstream重定向数据流时间耗费较大
优化:
(1)用C语言打开文件,直接把数据保存在一个字符数组里
(2)顺序遍历整个字符串,然后在拼接为单个string类型,O(n)复杂度
要求3:优化方法:
(1)用C语言打开文件,直接把数据保存在一个字符数组里,在只有只要遍历一次拼装成string串放入map
const int maxn = 10000000+100; char Buffer[maxn];
FILE *fp; fp = fopen(File_Name.c_str(),"rb"); int size_file = fread(Buffer,1,maxn,fp); Buffer[size_file] = '�'; fclose(fp);
(2)顺序遍历整个字符串,然后在拼接为单个string类型,O(n)复杂度
1 for(int i = 0 ; i < size_file; ++i) 2 { 3 ch = Buffer[i]; 4 if(ch >= 'A' && ch <= 'Z') ch = ch + 32; 5 if((ch >= 'a' && ch <= 'z') || (ch >= '0' && ch <='9')) 6 { 7 str += ch; 8 continue; 9 } 10 if(!str.empty()) 11 { 12 if(str[0] >= 'a' && str[0] <= 'z') 13 { 14 if(Map.count(str)) ++Map[str]; 15 else 16 { 17 Vstr.push_back(str); 18 ++Map[str]; 19 } 20 ++sum_word; 21 } 22 str = ""; 23 } 24 25 }
再次profile分析
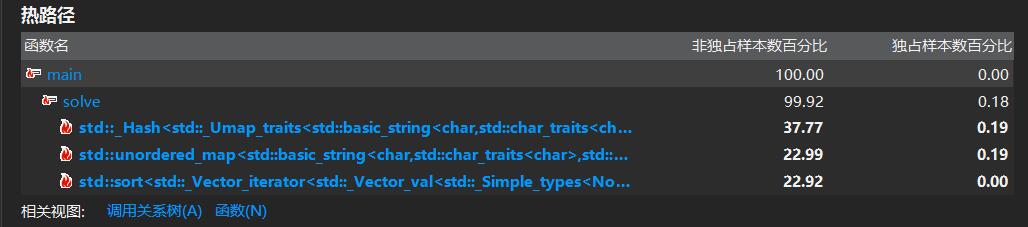

下面是三个最耗时的代码片段占用百分比

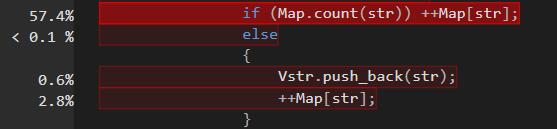

下面是最后三次测试的时间
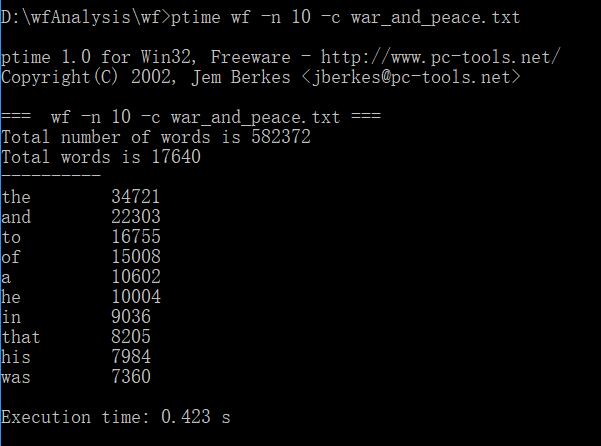
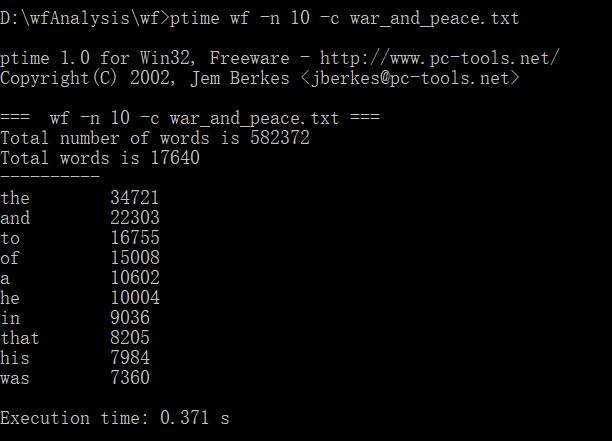
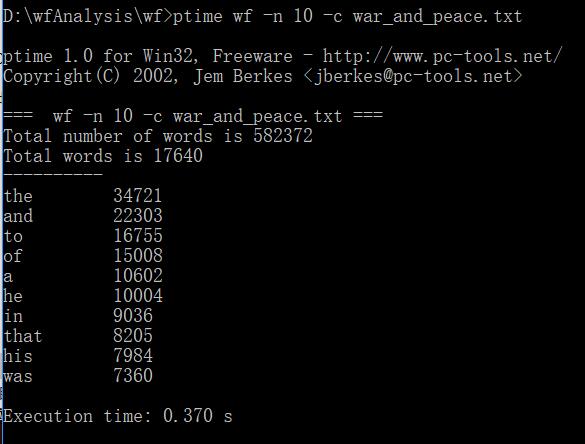
下面是表格
时间加快了进一百多倍
| 次数 | 耗时(s/秒) |
| 第一次 | 0.432 |
| 第二次 | 0.371 |
| 第三次 | 0.370 |
| 平均 | 0.391 |
要求4:(助教测试)
二、自我评估
1.首先通过这次作业我认识到了应用合适的数据结构,方法会是速度加快很多。比如这次使用C语言里的文件读取函数会使读取速度大大加快(但是C++写起来很快,就是运行有时候会很慢),所以学会在合适的时候选择合适的方法是一件重要的事情。其次就是掌握了控制台程序命令行输入参数的方法( int main(int argc, char * argv[]) ),这在以前将C语言的时候虽然知道有,但是却不知道作用。
2.大一、大二两年,上过的课程确实很多,有C/C++,Java,HTML,python等等,但是感觉都是只学了基本语法和简单的函数,我感觉我现在连一个小软件都还写不出来。之前是在用C/C++做算法题目,只是一直在写控制台程序,没有使用什么界面,而且用不到什么内置函数,算法都是自己用最基本的语法敲出来的。所以实用性较小,而通过这种作业我学会了许多C语言里面的实用性较大函数。学过了许多门课程数据结构、算法、操作系统等等,一直都是各自为营,没有把这几种结合起来。
关于能力的话,我感觉我也就是对C/C++语言比较了解(感觉也只能称为了解),大概就是因为写算法题目的原因。这学期,我打算增强一下面向对象编程能力,重新再学一下java。

|
skill 技能 |
课前评估(0..9) | 课后评估(0..9) |
|
Programming:Comprehension (程序理解)(如何理解已有程序,通过阅读,分析,debug) |
3 | 4 |
|
Programming:Design (架构设计,模块化设计,接口设计) |
1 | 1 |
| Programming:Test(单元测试、代码覆盖率) | 2 | 1 |
|
Programming:Code Review/Code Quality (代码复审/代码规范/代码质量) |
2 | 4 |
|
Programming:Command line and files (处理命令行参数和文件系统) |
1 | 2 |
|
Programming Language(C/C++/C#/Java) (pick one language) |
3 | 4 |
|
Programming:cutting edge techn (最新发现如C++11) |
3 | 3 |
Fitting