重写equals 必须重写hashcode
前言
在程序设计中,有很多的“公约”,遵守约定去实现你的代码,会让你避开很多坑,这些公约是前人总结出来的设计规范。
Object类是Java中的万类之祖,其中,equals和hashCode是2个非常重要的方法。
这2个方法总是被人放在一起讨论。最近在看集合框架,为了打基础,就决定把一些细枝末节清理掉。一次性搞清楚!
下面开始剖析。
public boolean equals(Object obj)
Object类中默认的实现方式是 : return this == obj 。那就是说,只有this 和 obj引用同一个对象,才会返回true。
而我们往往需要用equals来判断 2个对象是否等价,而非验证他们的唯一性。这样我们在实现自己的类时,就要重写equals.
按照约定,equals要满足以下规则。
自反性: x.equals(x) 一定是true
对null: x.equals(null) 一定是false
对称性: x.equals(y) 和 y.equals(x)结果一致
传递性: a 和 b equals , b 和 c equals,那么 a 和 c也一定equals。
一致性: 在某个运行时期间,2个对象的状态的改变不会不影响equals的决策结果,那么,在这个运行时期间,无论调用多少次equals,都返回相同的结果。
一个例子

1 class Test
2 {
3 private int num;
4 private String data;
5
6 public boolean equals(Object obj)
7 {
8 if (this == obj)
9 return true;
10
11 if ((obj == null) || (obj.getClass() != this.getClass()))
12 return false;
13
//能执行到这里,说明obj和this同类且非null。
14 Test test = (Test) obj;
15 return num == test.num&& (data == test.data || (data != null && data.equals(test.data)));
16 }
17
18 public int hashCode()
19 {
20 //重写equals,也必须重写hashCode。具体后面介绍。
24 }
25
26 }
equals编写指导
Test类对象有2个字段,num和data,这2个字段代表了对象的状态,他们也用在equals方法中作为评判的依据。
在第8行,传入的比较对象的引用和this做比较,这样做是为了 save time ,节约执行时间,如果this 和 obj是 对同一个堆对象的引用,那么,他们一定是qeuals 的。
接着,判断obj是不是为null,如果为null,一定不equals,因为既然当前对象this能调用equals方法,那么它一定不是null,非null 和 null当然不等价。
然后,比较2个对象的运行时类,是否为同一个类。不是同一个类,则不equals。getClass返回的是 this 和obj的运行时类的引用。如果他们属于同一个类,则返回的是同一个运行时类的引用。注意,一个类也是一个对象。
1、有些程序员使用下面的第二种写法替代第一种比较运行时类的写法。应该避免这样做。
if((obj == null) || (obj.getClass() != this.getClass()))
return false; if(!(obj instanceof Test))
return false; // avoid 避免!
它违反了公约中的对称原则。
例如:假设Dog扩展了Aminal类。
dog instanceof Animal 得到true
animal instanceof Dog 得到false
这就会导致
animal.equls(dog) 返回true
dog.equals(animal) 返回false
仅当Test类没有子类的时候,这样做才能保证是正确的。
2、按照第一种方法实现,那么equals只能比较同一个类的对象,不同类对象永远是false。但这并不是强制要求的。一般我们也很少需要在不同的类之间使用equals。
3、在具体比较对象的字段的时候,对于基本值类型的字段,直接用 == 来比较(注意浮点数的比较,这是一个坑)对于引用类型的字段,你可以调用他们的equals,当然,你也需要处理字段为null 的情况。对于浮点数的比较,我在看Arrays.binarySearch的源代码时,发现了如下对于浮点数的比较的技巧:
if ( Double.doubleToLongBits(d1) == Double.doubleToLongBits(d2) ) //d1 和 d2 是double类型 if( Float.floatToIntBits(f1) == Float.floatToIntBits(f2) ) //f1 和 f2 是d2是float类型
4、并不总是要将对象的所有字段来作为equals 的评判依据,那取决于你的业务要求。比如你要做一个家电功率统计系统,如果2个家电的功率一样,那就有足够的依据认为这2个家电对象等价了,至少在你这个业务逻辑背景下是等价的,并不关心他们的价钱啊,品牌啊,大小等其他参数。
5、最后需要注意的是,equals 方法的参数类型是Object,不要写错!
===================================================================================================================
Java中的浮点数比较 == equals 和 compare
前几天有位同学问我一个问题,为什么float和double不能直接用==比较?
例如:
- System.out.println(0.1d == 0.1f);
结果会是flase
当时我只是简单的回答,因为精度丢失,比较结果是不对的。
那么,到底为什么不对呢? 此文略作整理记录。
类型升级(type promotion)
首先,来看看java中的几种原生的数值类型进行==或!=比较运算的时候会发生什么。
如果运算符两边的数值类型不同,则首先会进行类型升级(type promotion),规则如下:
- 如果运算符任意一方的类型为double,则另一方会转换为double
- 否则,如果运算符任意一方的类型为float,则另一方会转换为float
- 否则,如果运算符任意一方的类型为long,则另一方会转换为long
- 否则,两边都会转换为int
详情见官方文档 http://docs.oracle.com/javase/specs/jls/se7/html/jls-5.html#jls-5.6.2
然后,浮点数执行浮点数相等比较(int或者long执行整型相等比较)
那么,上面那个例子,float首先会被升级为double,然后执行浮点数相等比较。那为什么会返回flase呢?
- System.out.println(0.1d == (double) 0.1f);
结果为false
舍入误差(round-off error)
我们知道,根据IEEE 754,单精度的float是32位,双精度的double为64位,如下图:

其中,第一部分(s)为符号位,第二部分(exponent)为指数位,第三部分(mantissa)为基数部分。 这是科学计数法的二进制表示。
那么,既然位数是固定的,要表示像 1/3=0.3333333333333...或者pi=3.1415926..... 这样的无限循环小数,就变得不可能了。
根据规范,则需要将不能标识的部分舍掉。
第二,还与10进制不同的是,二进制对于一些有限的小数,也不能精确的标示。比如像0.1这样的小数,用二进制也无法精确表示。所以,也需要舍掉。
关于0.1无法用二进制精确表示,可以参见文章: http://en.wikipedia.org/wiki/Floating_point
补充:科学计数法及浮点数的二进制表示
首先,再来回忆一下,科学计数法是什么样子的。一个数,可以有多重表示方法。
例如,254可以有但不仅仅有以下几种表示:

上面这是10进制的表示方式,也就是基数为10的表示方式。 基数,就是上面例子中 25.4 * 10 这里的10,当然,指数是1.
但是如果基数是2,需要怎么转换呢?
看下面这个例子:

所以,经过这个转换,就可以用IEEE 754表示一个浮点数了。
单精度转换为双精度会发生什么
首先,我们来看,单精度浮点数0.1表示成二进制会是什么样子的:
- System.out.println(Integer.toBinaryString(Float.floatToIntBits(0.1f)));
结果是:111101110011001100110011001101
然后,双精度的浮点数0.1的二进制会是什么样子呢:
- System.out.println(Long.toBinaryString(Double.doubleToLongBits(0.1d)));
然后,在比较float==double的时候,首先,会将float进行类型升级,得到的新的double 的值会是什么样子:
- System.out.println(Long.toBinaryString(Double.doubleToLongBits(0.1f)));
我们可以看到,经过转换后的double的值已经和直接赋值的double的值不相等了。所以这样用==比较返回的值是false
- System.out.println(Integer.toBinaryString(Float.floatToIntBits(0.1f)));
- System.out.println(Long.toBinaryString(Double.doubleToLongBits(0.1d)));
- System.out.println(Long.toBinaryString(Double.doubleToLongBits(0.1f)));

用equals方法进行比较
既然,用==或者!=来比较非常坑爹,那可以用equals来进行比较吗? 我的答案是一定不能。
看看下面2个例子。
- Double a = Double.valueOf("0.0");
- Double b = Double.valueOf("-0.0");
- System.out.println(a.equals(b));
这是经常出现的场景,不过我简化了。试想,经过一系列运算过后,一个结果为0,一个结果为-0,结果不等。很难接受是吧?
如果上面那个列子只是坑,下面这个简直就是地雷了。
- Double a = Math.sqrt(-1.0);
- Double b = 0.0d / 0.0d;
- Double c = a + 200.0d;
- Double d = b + 1.0d;
- System.out.println(a.equals(b));
- System.out.println(b.equals(c));
- System.out.println(c.equals(d));
其实,在Java里面,a和b表示为NaN(Not a Number),既然不是数字,就无法比较嘛。
但是equals方法是比较2个对象是否等值,而不是对象的值是否相等,所以equals方法设计的初衷根本就不是用来做数值比较的。勿乱用。
关于equals方法,我另外一篇记录会做更多解释。
用compareTo方法进行比较
虽然说它在设计上是用于数值比较的,但它表现跟equals方法一模一样——对于NaN和0.0与-0.0的比较上面。
另外,由于舍入误差的存在,也可能会导致浮点数经过一些运算后,结果会有略微不同。
所以最好还是不要直接用Float.compareTo和Double.compareTo方法。
结论
在进行浮点数比较的时候,主要需要考虑3个因素
- NaN
- 无穷大/无穷小
- 舍入误差
NaN和无穷出现的可能场景如下

所以,要比较浮点数是否相等,需要做的事情是:
- 排除NaN和无穷
- 在精度范围内进行比较
- public boolean isEqual(double a, double b) {
- if (Double.isNaN(a) || Double.isNaN(b) || Double.isInfinite(a) || Double.isInfinite(b)) {
- return false;
- }
- return (a - b) < 0.001d;
- }
它什么都好,就是效率略低。需要自行在性能和精度之间取舍。
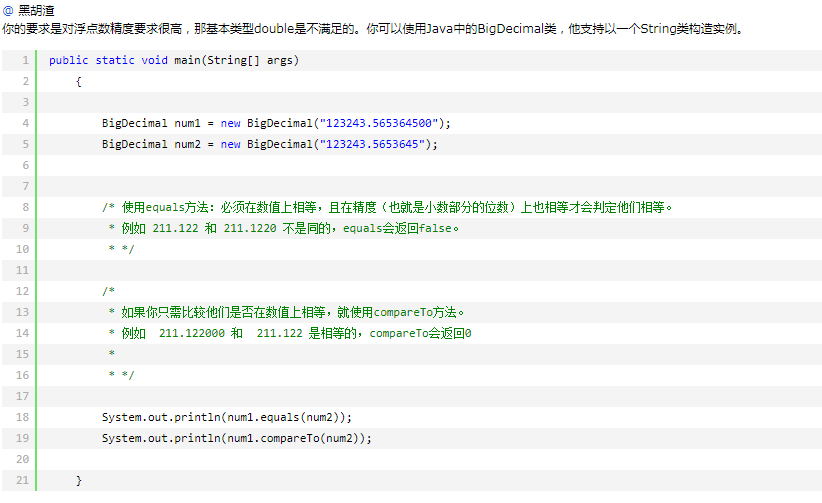
为什么下面这种方式可能会出现精度问题
- BigDecimal.valueOf(0.1d);
- new BigDecimal(0.1d);
====================================================================================================
特别注意:
double a = 0.1;
所创建的new BigDecimal(a);并不正好等一0.1,而是 0.1000000000000000055511151231257827021181583404541015625
这是因为doule不能表示为任何有限长度的二进制小数。
String b = "0.1";
所创建的new BigDecimal(b),正好等于0.1.
=================================================================================================
public int hashCode()
这个方法返回对象的散列码,返回值是int类型的散列码。
对象的散列码是为了更好的支持基于哈希机制的Java集合类,例如 Hashtable, HashMap, HashSet 等。
关于hashCode方法,一致的约定是:
重写了euqls方法的对象必须同时重写hashCode()方法。
如果2个对象通过equals调用后返回是true,那么这个2个对象的hashCode方法也必须返回同样的int型散列码
如果2个对象通过equals返回false,他们的hashCode返回的值允许相同。(然而,程序员必须意识到,hashCode返回独一无二的散列码,会让存储这个对象的hashtables更好地工作。)
在上面的例子中,Test类对象有2个字段,num和data,这2个字段代表了对象的状态,他们也用在equals方法中作为评判的依据。那么, 在hashCode方法中,这2个字段也要参与hash值的运算,作为hash运算的中间参数。这点很关键,这是为了遵守:2个对象equals,那么 hashCode一定相同规则。
也是说,参与equals函数的字段,也必须都参与hashCode 的计算。
合乎情理的是:同一个类中的不同对象返回不同的散列码。典型的方式就是根据对象的地址来转换为此对象的散列码,但是这种方式对于Java来说并不是唯一的要求的
的实现方式。通常也不是最好的实现方式。
相比 于 equals公认实现约定,hashCode的公约要求是很容易理解的。有2个重点是hashCode方法必须遵守的。约定的第3点,其实就是第2点的
细化,下面我们就来看看对hashCode方法的一致约定要求。
第一:在某个运行时期间,只要对象的(字段的)变化不会影响equals方法的决策结果,那么,在这个期间,无论调用多少次hashCode,都必须返回同一个散列码。
第二:通过equals调用返回true 的2个对象的hashCode一定一样。
第三:通过equasl返回false 的2个对象的散列码不需要不同,也就是他们的hashCode方法的返回值允许出现相同的情况。
总结一句话:等价的(调用equals返回true)对象必须产生相同的散列码。不等价的对象,不要求产生的散列码不相同。
hashCode编写指导
在编写hashCode时,你需要考虑的是,最终的hash是个int值,而不能溢出。不同的对象的hash码应该尽量不同,避免hash冲突。
那么如果做到呢?下面是解决方案。
1、定义一个int类型的变量 hash,初始化为 7。
接下来让你认为重要的字段(equals中衡量相等的字段)参入散列运,算每一个重要字段都会产生一个hash分量,为最终的hash值做出贡献(影响)
| 重要字段var的类型 | 他生成的hash分量 |
|---|---|
| byte, char, short , int | (int)var |
| long | (int)(var ^ (var >>> 32)) |
| boolean | var?1:0 |
| float | Float.floatToIntBits(var) |
| double | long bits = Double.doubleToLongBits(var); 分量 = (int)(bits ^ (bits >>> 32)); |
| 引用类型 | (null == var ? 0 : var.hashCode()) |
最后把所有的分量都总和起来,注意并不是简单的相加。选择一个倍乘的数字31,参与计算。然后不断地递归计算,直到所有的字段都参与了。
int hash = 7; hash = 31 * hash + 字段1贡献分量; hash = 31 * hash + 字段2贡献分量; ..... return hash;