cuGraph-GPU图形分析
所述RAPIDS cuGraph库是GPU的集合加速图形算法,在GPU DataFrames中发现过程数据。cuGraph的愿景是使图分析无处不在,以至于用户只是根据分析而不是技术或框架来思考。为了实现这一构想,cuGraph操作时,在Python的层,在GPU上DataFrames,从而允许无缝传递ETL任务之间的数据的cuDF和机器学习任务cuML。熟悉Python的数据科学家将迅速了解cuGraph如何与cuDF的类似Pandas的API集成。同样,熟悉NetworkX的用户将迅速认识cuGraph中提供的类似NetworkX的API,其目标是允许以最小的努力将现有代码移植到RAPIDS中。对于熟悉C ++ / CUDA和图形结构的用户,还提供了C ++ API。但是,C ++层的类型和结构检查较少。
有关更多项目详细信息,请参见Rapids.ai。
注意:有关最新的稳定README.md,确保位于最新的分支上。
进口 书法
#使用read_csv数据读入一个cuDF数据帧
GDF = cudf。read_csv(“ graph_data.csv”,名称= [ “ src”,“ dst” ],dtype = [ “ int32”,“ int32” ])
import cugraph
# read data into a cuDF DataFrame using read_csv
gdf = cudf.read_csv("graph_data.csv", names=["src", "dst"], dtype=["int32", "int32"])
# We now have data as edge pairs
# create a Graph using the source (src) and destination (dst) vertex pairs
G = cugraph.Graph()
G.from_cudf_edgelist(gdf, source='src', destination='dst')
# Let's now get the PageRank score of each vertex by calling cugraph.pagerank
df_page = cugraph.pagerank(G)
# Let's look at the PageRank Score (only do this on small graphs)
for i in range(len(df_page)):
print("vertex " + str(df_page['vertex'].iloc[i]) +
" PageRank is " + str(df_page['pagerank'].iloc[i]))
支持的算法
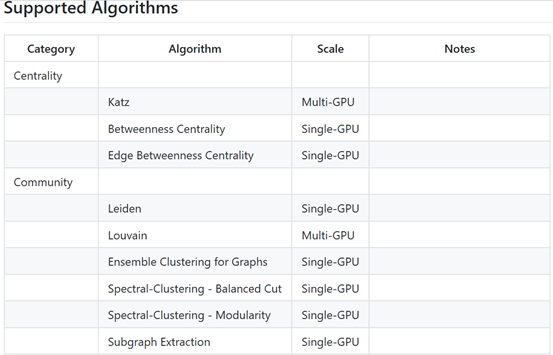
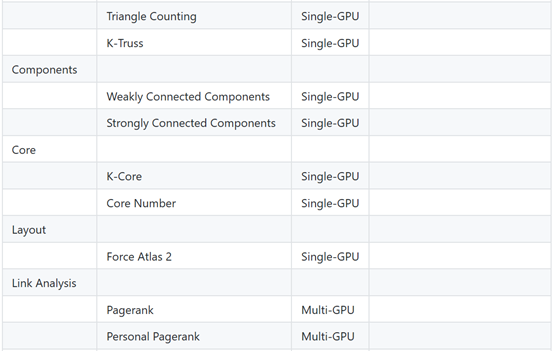
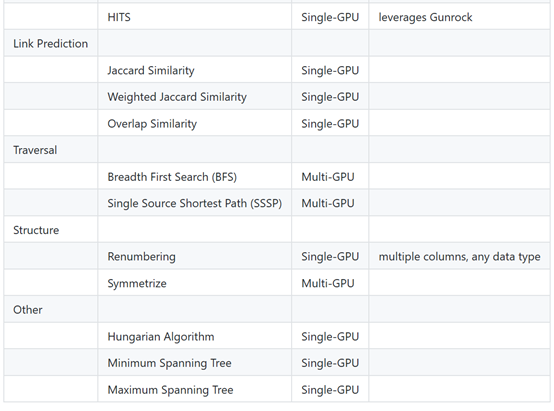
支持图

支持的数据类型
cuGraph支持创建几种数据类型的图形:
- cuDF DataFrame
- Pandas DataFrame
cuGraph支持执行来自不同图形对象的图形算法
- cuGraph图类
- NetworkX图类
- CuPy稀疏矩阵
- SciPy稀疏矩阵
cuGraph尝试根据输入类型匹配返回类型。因此,NetworkX输入将返回与NetworkX相同的数据类型。
cuGraph注意
当前版本的cuGraph有一些限制:
- 顶点ID应该是从0开始的连续整数。
cuGraph提供了重新编号功能来缓解此问题,默认情况下,将数据添加到图形时会自动调用该功能。重编号函数的输入顶点ID可以是任何类型,可以是非连续的,可以是多列,并且可以从任意数字开始。重新编号功能将提供的输入顶点ID映射到从0开始的32位连续整数。cuGraph仍然要求重新编号的顶点ID必须以32位整数表示。这些限制已得到解决,将很快修复。
此外,使用自动重编号功能时,结果中的顶点会自动取消编号。
cuGraph不断更新和改进。如果新版本遇到错误,请参阅《Transition Guide》
图形大小和GPU内存大小
所需的内存量取决于图形结构和执行的分析。根据一条简单的经验法则,GPU内存量应约为数据大小的两倍。这给CSV 数据读取和其它转换功能带来了开销。有很多方法可以使用规则,但是使用较小的数据块。
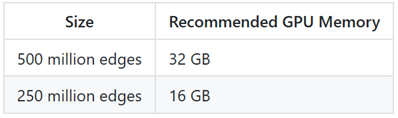
使用托管内存进行超额预订也可以超出上述内存限制。
获取cuGraph
介绍
有三种获取cuGraph的方法:
l Quick start with Docker Demo Repo
快速开始
参阅Demo Docker Repository,根据运行的NVIDIA CUDA版本选择一个标签。这提供了一个带有示例笔记和数据的可立即运行的Docker容器,展示了如何利用所有RAPIDS库:cuDF,cuML和cuGraph。
Conda
使用conda安装cuGraph很容易。可以使用Miniconda进行最小的conda安装,也可以使用Anaconda进行完整的安装。
使用conda命令安装和更新cuGraph:
# CUDA 10.1
conda install -c nvidia -c rapidsai -c numba -c conda-forge -c defaults cugraph cudatoolkit=10.1
# CUDA 10.2
conda install -c nvidia -c rapidsai -c numba -c conda-forge -c defaults cugraph cudatoolkit=10.2
# CUDA 11.0
conda install -c nvidia -c rapidsai -c numba -c conda-forge -c defaults cugraph cudatoolkit=11.0
注意:此conda安装仅适用于Linux和Python版本3.7 / 3.8。
https://github.com/rapidsai/cugraph