微信公众号中(这里)看到一个关于MySQL的innodb_deadlock_detect与并发相关的细节,觉得比较有意思,也即innodb_deadlock_detect这个参数的设置问题

死锁检测是一个MySQL Server层的自动检测机制,可以及时发现两个或者多个session间互斥资源的申请造成的死锁,且会自动回滚一个(或多个)事物代价相对较小的session,让执行代价最大的先执行。
该参数默认就是打开的,按理说也是必须要打开的,甚至在其他数据库中没有可以使其关闭的选项。
innodb_deadlock_detect
如果关闭innodb_deadlock_detect,也即关闭了死锁自动监测机制时,当两个或多个session间存在死锁的情况下,MySQL怎么去处理?
这里会涉及到另外一个参数:锁超时,也即innodb_lock_wait_timeout,该参数指定了“锁申请时候的最长等待时间”
官方的解释是:The length of time in seconds an InnoDB transaction waits for a row lock before giving up.
innodb_lock_wait_timeout默认值是50秒,也就是意味着session请求时,申请不到锁的情况下最多等待50秒钟,然后呢,就等价于死锁,自动回滚当前事物了?其实不是的,事情没有想象中的简单。
innodb_rollback_on_timeout
这里就涉及到另外一个参数:innodb_rollback_on_timeout,默认值是off,该参数的决定了当前请求锁超时之后,回滚的是整个事物,还是当前语句,
官方的解释是:InnoDB rolls back only the last statement on a transaction timeout by default。
默认值是off,也就是回滚当前语句(放弃当前语句的锁申请),有人建议打开整个选项(on),也就是一旦锁申请超时,就回滚整个事物。
需要注意的是,默认情况下只回滚当前语句,而不是整个事物,当前的事物还在继续,连接也还在,与死锁自动监测机制打开之后会主动牺牲一个事物不同,锁超时后并不会主动牺牲其中任何一个事物。
这意味着会出现一种非常严重的情况,举个例子,可以想象一下如下这种情况:
session1 session2
start transaction; start transaction;
update A set val = 'xxx' where id = 1 update B set val = 'yyy' where id = 1
…… ……
update B set val = 'xxx' where id = 1 update A set val = 'yyy' where id = 1
if 锁超时 if 锁超时
#继续申请锁 #继续申请锁
update B set val = 'xxx' where id = 1 update A set val = 'xxx' where id = 1
关闭了死锁监测机制后,在innodb_rollback_on_timeout保持默认的off的情况下,session1和session2都是无法正常执行下去的,且永远都无法执行下去。
任意一个session出现锁超时,放弃当前的语句申请的锁,而不是整个事物持有的锁,当前session并不释放其他session请求的锁资源,
即便是继续下去,依旧如此,两者又陷入了相互等待,相互锁请求超时,继续死循环。
从这里可以看到,与死锁自动检测机制在发现死锁是主动选择一个作为牺牲品不同,一旦关闭了innodb_deadlock_detect,Session中的任意一方都不会主动释放已经持有的锁。
此时如果应用程序如果不足够的健壮,继续去申请锁(比如重试机制,尝试重试相关语句),session双方会陷入到无限制的锁超时死循环之中。
事实上推论是不是成立的?做个测试验证一下,数据库环境信息如下
模拟事物双方在当前语句的锁超时之后,继续申请锁,确实是会出现无限制的锁超时的死循环之中。
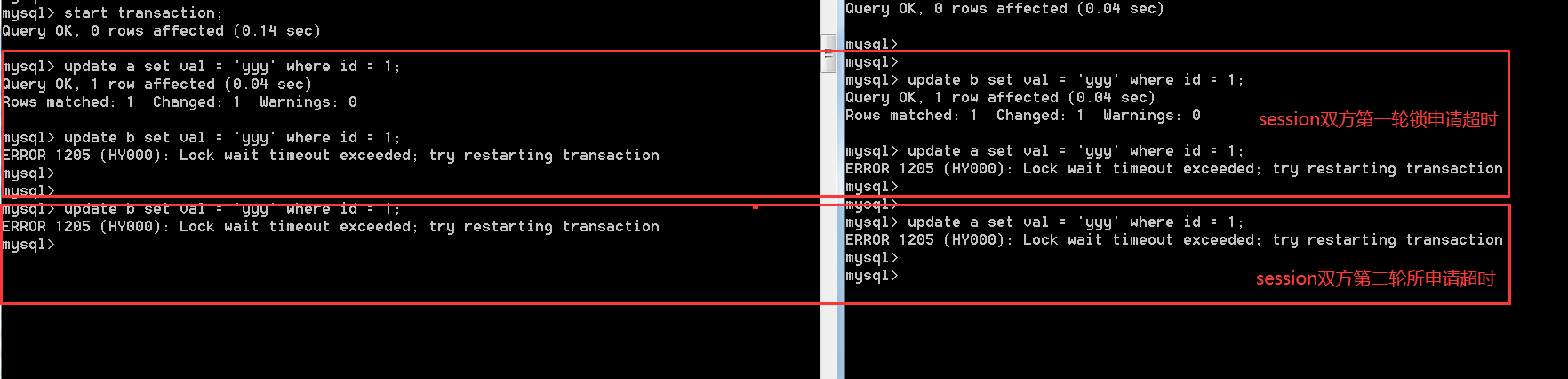
以上就比较有意思了,与死锁主动监测并牺牲其中一个事物不同,此时事物双方互不相让,当然也都无法成功执行。
这只不过是一个典型的负面场景,除此之外,还会有哪些问题值得思考?
1,因为事物无法快速提交或者回滚,那么连接持有的时间会增加,一旦并发量上来,连接数可能成为一个问题。
2,锁超时时间肯定要设置为一个相对较小的时间,但具体又设置为多少靠谱。
3,关闭死锁检测,带来的收益,与副作用相比哪个更高,当前业务类型是否需要关闭死锁检测,除非数据库中相关操作大部分都是短小事物且所冲突的可能性较低。
4,面对锁超时,应用程序端如何合理地处理锁超时的情况,是重试还是放弃。
5,与此关联的innodb_rollback_on_timeout如何设置,是保持默认的关闭(锁超时的情况下,取消当前语句的所申请),还是打开(锁超时的情况下,回滚整个事物)
最后,其实这个问题属于一个系统工程,不是一个单点问题,除此之外还有可能潜在一些其他的问题,原作者是大神,当然是一个整体方案,需要在整体架构上做处理,作者也给出了一个客观的处理方式。
参考链接
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_lock_wait_timeout
关于innodb_deadlock_detect参数,这里有一篇比较好的文章,来源:https://www.fromdual.com/comment/1018
以下为译文:
最近,我们有一位新客户,他时不时遇到大量他无法理解的数据库问题。当我们查看 MySQL 配置文件 (my.cnf) 时,我们发现此客户已禁用 InnoDB 死锁检测 (innodb_deadlock_detect)。
因为到目前为止,我们建议不要这样做,但在实践中我从未偶然发现过这个问题,所以我对MySQL变量innodb_deadlock_detect进行了更多的调查。
MySQL 文档告诉我们以下 {1}:
禁用死锁检测
在高并发系统上,当许多线程等待同一锁时,死锁检测可能会导致速度变慢。有时,禁用死锁检测并依赖于innodb_lock_wait_timeout设置以在发生死锁时进行事务回滚可能更有效。可以使用innodb_deadlock_detect配置选项禁用死锁检测。
关于参数innodb_deadlock_detect本身 [2] :
此选项用于禁用死锁检测。在高并发系统上,当许多线程等待同一锁时,死锁检测可能会导致速度变慢。有时,禁用死锁检测并依赖于innodb_lock_wait_timeout设置以在发生死锁时进行事务回滚可能更有效。
问题是,每次 MySQL 执行 (行)锁或表锁时,如果锁导致死锁,都会进行检查。这个检查的代价很高。顺便说一下:禁用InnoDB死锁检测的功能是由Facebook为WebScaleSQL开发的[3]。
相关功能可在 [4] 中找到:
class DeadlockChecker, method check_and_resolve (DeadlockChecker::check_and_resolve) Every InnoDB (row) Lock (for mode LOCK_S or LOCK_X) and type ORed with LOCK_GAP or LOCK_REC_NOT_GAP, ORed with LOCK_INSERT_INTENTION Enqueue a waiting request for a lock which cannot be granted immediately. lock_rec_enqueue_waiting()
和
Every (InnoDB) Table Lock Enqueues a waiting request for a table lock which cannot be granted immediately. Checks for deadlocks. lock_table_enqueue_waiting()
这意味着,如果变量innodb_deadlock_detect为每个锁定(行或表)启用(= 默认值),则检查该变量(如果导致死锁)。
如果禁用该变量,则检查未完成(速度更快),事务将挂起(死)锁定,直到释放锁定或超过innodb_lock_wait_timeout时间(默认 50 秒)。然后 InnoDB 锁定等待超时(探测器?)罢工并杀死事务。
SQL> SHOW GLOBAL VARIABLES LIKE 'innodb_lock_wait%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 50 |
+--------------------------+-------+
这意味着,停用 InnoDB 死锁检测是有趣的,如果你有许多(如 Facebook一样)短小事物,你期望现在很少发生冲突。此外,建议将 MySQL 变量innodb_lock_wait_timeout设置为非常小的值(几秒)。
因为我们的大多数客户没有 Facebook 的规模,因为他们没有那么多并发的短交易和小交易,而是很少但交易多(可能有许多锁,因此存在高死锁概率),我可以想象,禁用此参数是客户系统的hickup(锁堆积)的原因。
这导致超过max_connections,最后整个系统崩溃。
因此,我强烈建议,让InnoDB死锁检测启用。除了你知道你在做什么(经过大约2周的广泛测试和测量)。
参考文献
- [1] Deadlock Detection and Rollback
- [2] InnoDB Startup Options and System Variables: innodb_deadlock_detect
- [3] Introduction of the variable
innodb_deadlock_detectin WebScaleSQL by Facebook on Github - [4] MariaDB/MySQL Source Code:
storage/innobase/lock/lock0lock.cc - [5] MariaDB InnoDB System Variables: innodb_deadlock_detect