1.环境
CDH 5.16.1
Spark 2.3.0.Cloudera4
2.SparkStreaming整合Kafka
地址:http://spark.apache.org/docs/2.3.0/streaming-kafka-integration.html
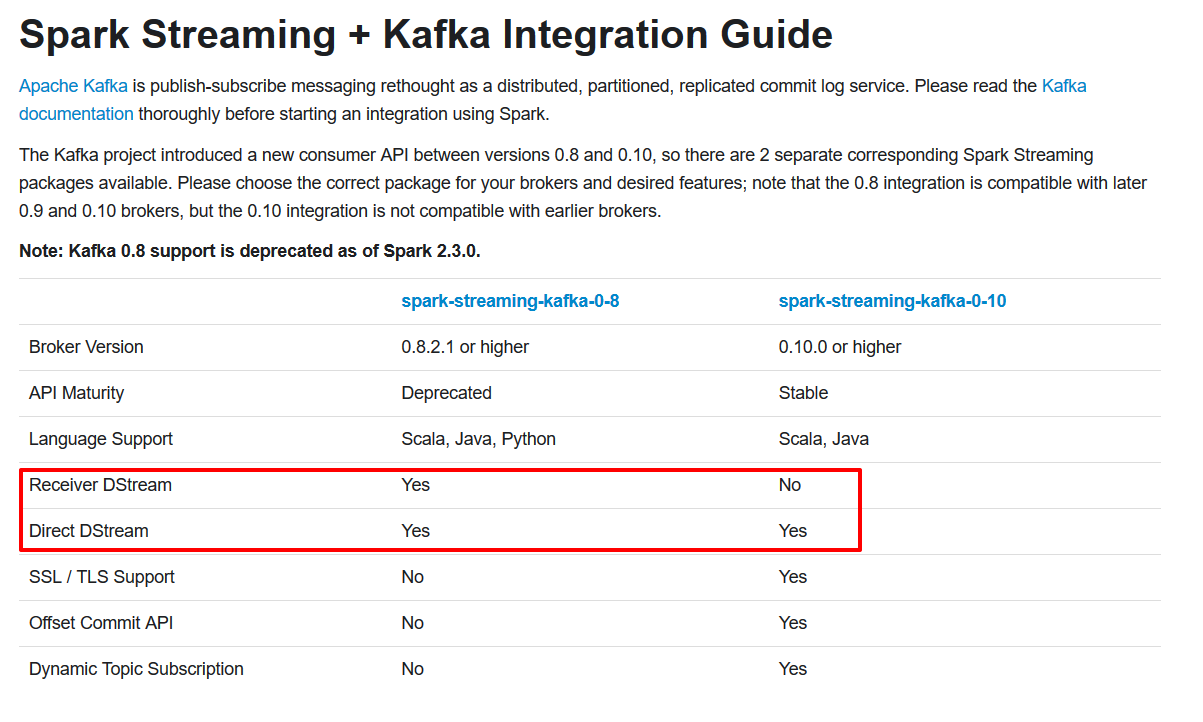
两种方式整合:
- Receiver
- Direct
3. Receiver整合
SparkStreaming采用Receiver方式整合Kafka
3.1 案例 Demo
package com.monk.sparkstreamingkafka
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @ClassName KafakReceiveWordCouont
* @Author wuning
* @Date: 2020/2/1 23:42
* @Description:
**/
object KafakReceiveWordCouont {
def main(args: Array[String]): Unit = {
if(args.length != 4){
System.err.println("Usage:KafakReceiveWordCouont <zkQuorum> <group> <topics> <numThreads>")
}
val Array(zkQuorum,group,topics,numThreads) = args
val sparkConf:SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getName)
val ssc: StreamingContext = new StreamingContext(sparkConf,Seconds(10))
ssc.sparkContext.setLogLevel("ERROR")
val topicMap:Map[String,Int] = topics.split(",").map((_,numThreads.toInt)).toMap
//TODO... Sparkstreaming 采用 receiver方式 对接 kafka
val msg: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(
ssc,
zkQuorum,
group,
topicMap,
StorageLevel.MEMORY_AND_DISK_SER_2
)
msg.map(_._2)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
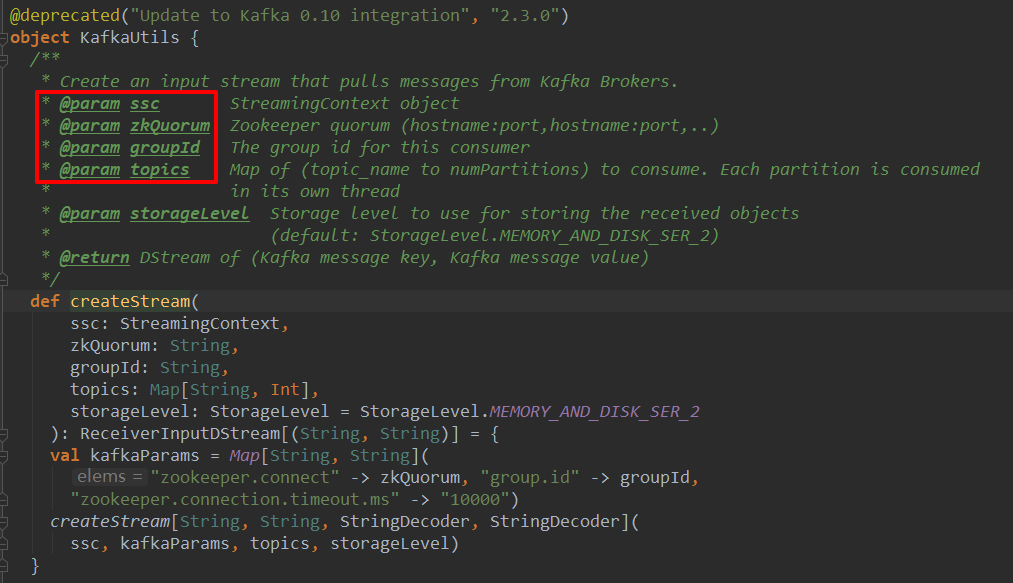
KafkaUtils 的 createStream 方法:
3.2 整合服务器环境联调
/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/bin/spark2-submit
--class com.monk.sparkstreamingkafka.KafakReceiveWordCouont
--master local[2]
--name KafakReceiveWordCouont
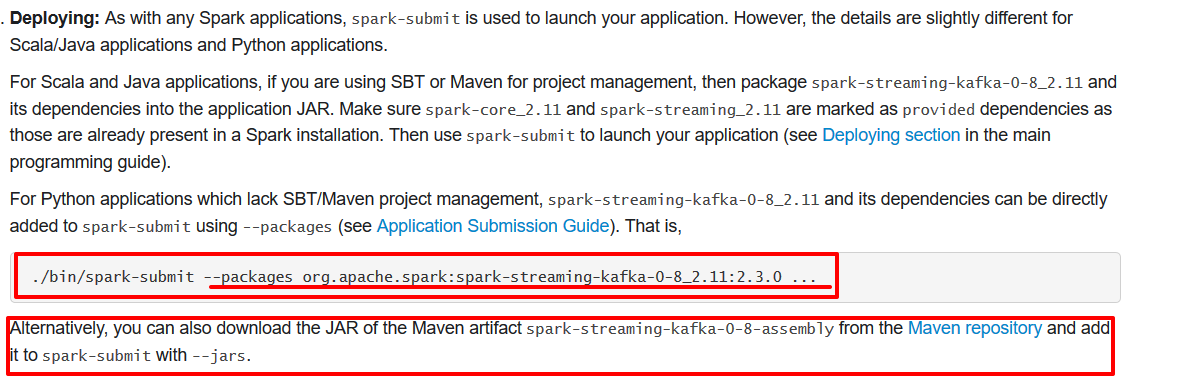
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.3.0
/opt/module/job/spark-1.0-SNAPSHOT.jar cdh01:2181/kafka test kafka_streaming_topic 2
注意:
- org.apache.spark:spark-streaming-kafka-0-8_2.11:2.3.0 依赖的jar包第一次下载会比较慢
- 最后参数记得带上

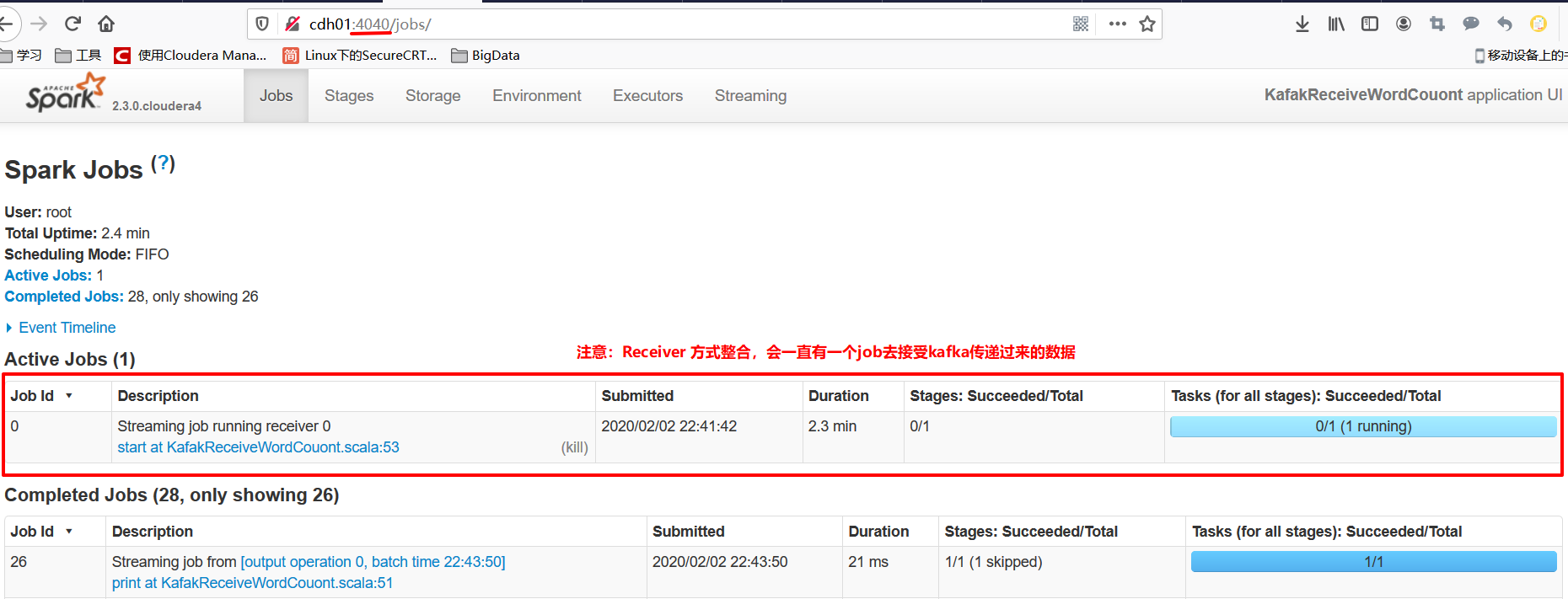
Spark后台:
4. Direct 方式整合
4.1 Direct 方式的优缺点

4.2 案例 Demo
package com.monk.sparkstreamingkafka
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @ClassName KafkaDirectWordCount
* @Author wuning
* @Date: 2020/2/2 23:25
* @Description:
**/
object KafkaDirectWordCount {
def main(args: Array[String]): Unit = {
if (args.length != 2) {
System.err.println("Usage:KafkaDirectWordCount <brokers> <topics>")
System.exit(1)
}
val Array(brokers, topics) = args
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getName)
val ssc: StreamingContext = new StreamingContext(sparkconf, Seconds(15))
ssc.sparkContext.setLogLevel("ERROR")
val kafkaMap: Map[String, String] = Map[String, String](
"metadata.broker.list" -> brokers,
"auto.offset.reset" -> "largest",
//Kafka 的参数可以在 Kafka.clients下的ConsumerConfig 找
ConsumerConfig.GROUP_ID_CONFIG -> "test")
val topicSet: Set[String] = topics.split(",").toSet
val message: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
kafkaMap,
topicSet
)
message.map(_._2)
.flatMap(_.split(""))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
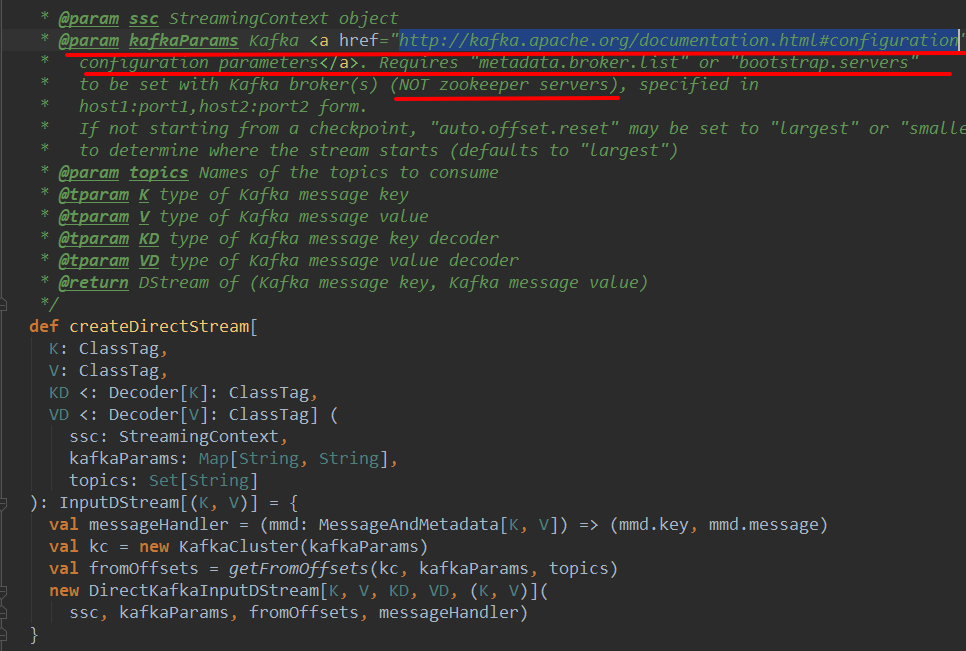
KafkaUtils 的 createDirectStream方法: