何为爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
我们平时的上网就是浏览器提交请求->下载网页代码->解析/渲染成页面。而我们的爬虫就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中。所以,我们的爬虫程序只提取网页代码中对我们有用的数据。
爬虫的基本流程

请求与响应
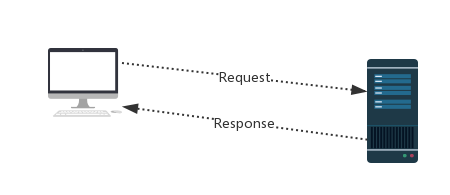
http协议:https://home.cnblogs.com/u/wusir66/
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
总结
1、总结爬虫流程:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:urllib.request,urllib.parse,requests,selenium
解析库:正则,beautifulsoup,lxml
存储库:文件,MySQL,Mongodb,Redis
3、爬虫常用框架:
scrapy