我的个人博客:https://www.wuyizuokan.com
介绍:
ZSet数据结构类似于Set结构,只是ZSet结构中,每个元素都会有一个分值,然后所有元素按照分值的大小进行排列,相当于是一个进行了排序的链表。
如果ZSet是一个链表,而且内部元素是有序的,在进行元素插入和删除,以及查询的时候,就必须要遍历链表才行,时间复杂度就达到了O(n),这个在以单线程处理的Redis中是不能接受的。所以ZSet采用了一种跳跃表的实现。这个实现有点类似于Kafka存储消息是使用的稀疏索引,kafka这个相对较简单,可以用来介绍类比学习。
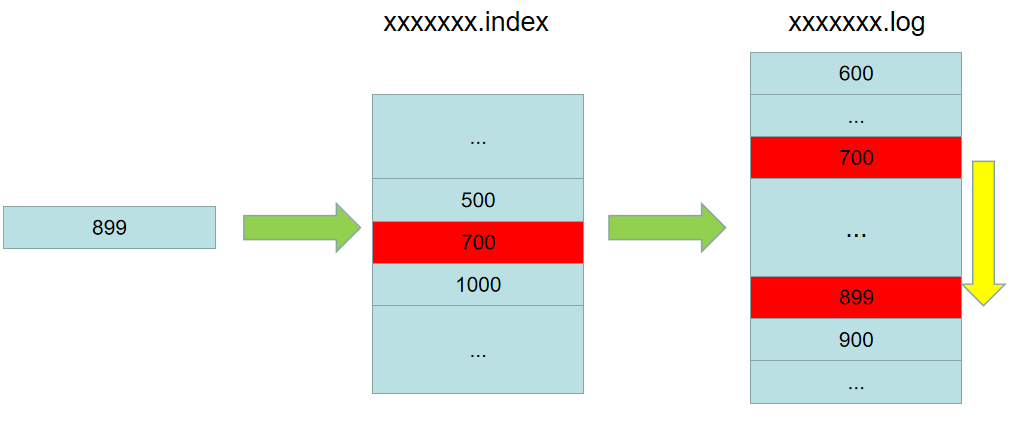
如果熟悉Kafka,就知道Kafka在进行持久化的时候,生成了两个文件,一个是xxxxxxx.log,一个是xxxxxxx.index,这其中log文件中以链表的形式保存着消息的详细信息,而index文件中,则是保存着这些消息的索引,或者说偏移量,但又不是每一条消息的索引都在index文件中存在,而是稀疏的,比如log文件中的消息的索引从0-10000,那么index文件中存储的索引可能是100, 500, 700, 1000, 5000, 6500,每一个索引中都保存着对应的log文件中的消息的具体位置,如图:

当要访问偏移量为899的这条消息时,先去index文件中查找,找到了700和1000这个区间,根据700这个索引中的信息,找到log文件中700这条消息的具体位置,然后顺序往下查找,直到找到索引为899的这条消息为止。从这个实现中我们可以看到,Kafka并没有进行log文件的整个遍历,而是通过index中的稀疏索引,找到消息在log中的大概位置,然后顺序遍历找到消息,这样就大大提高了查找的效率,如图:
Redis的跳跃表和上面类似,只是更加复杂一些,Kafka的稀疏索引只有一层,而Redis的索引被提取为多层。如图:
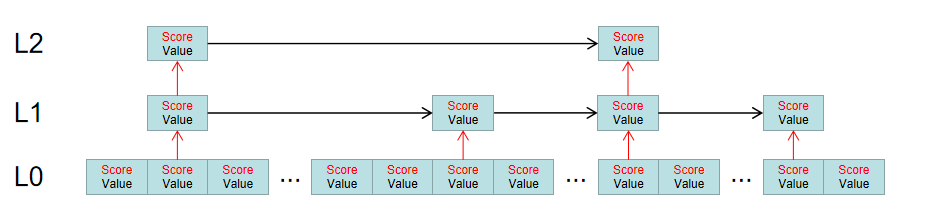
所有的元素都会在L0层的链表中,根据分数进行排序,同时会有一部分节点有机会被抽取到L1层中,作为一个稀疏索引,同样L1层中的索引也有一定机会被抽取到L2层中,组成一个更稀疏的索引列表。
下面用图来演示一下在对快速链表进行插入、删除、查询时,是如何定位到L0层中的具体位置的。
首先,假定有这么一个链表,注意这里只展示分数,而不展示具体的值了:
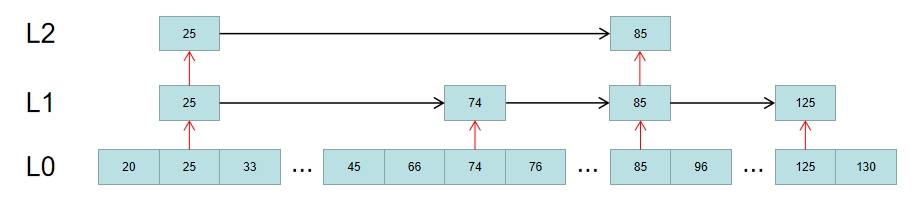
如果要查找分数为66的元素,首先在L2层的索引找。很明显,66位于25和85中间,这时就缩小了查找区间:
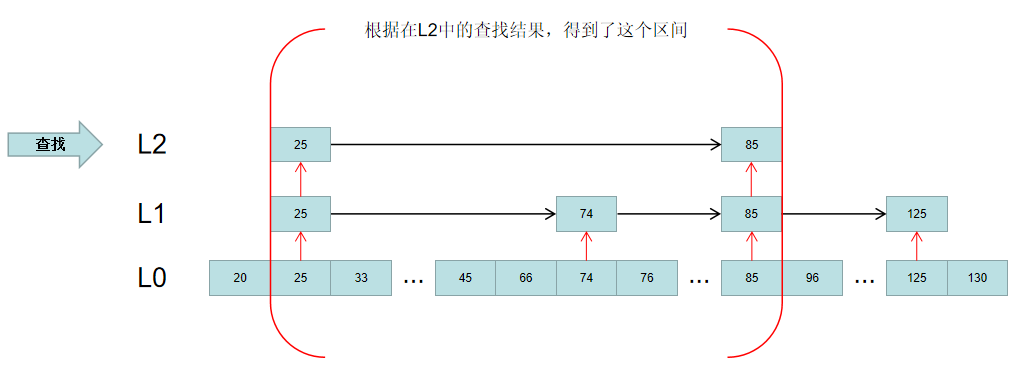
然后根据获得的区间,去L1对应的区间中查找,得到一个更精确的区间:
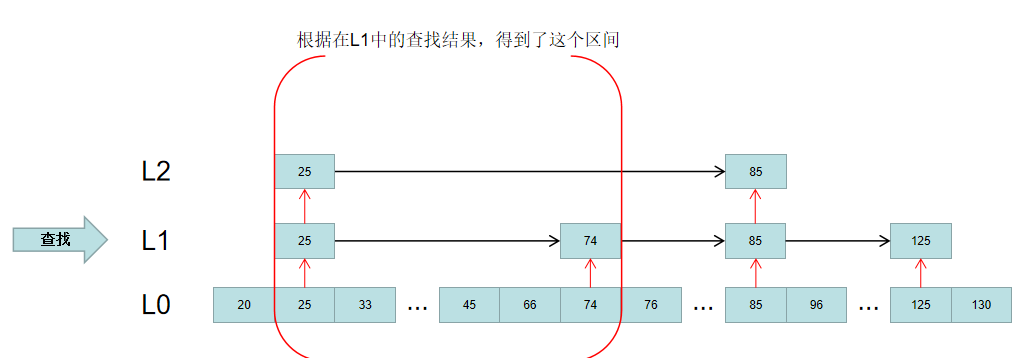
最终,根据这个更精确的区间,去L0层顺序遍历,即可得到要查找的元素:
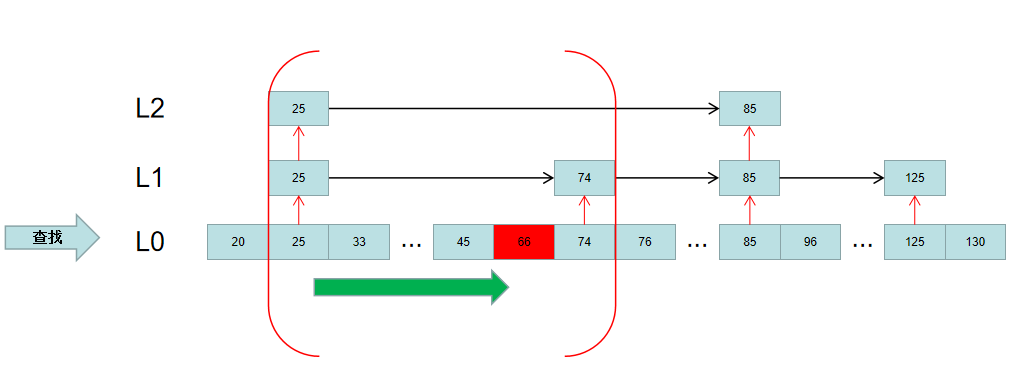
上述即是对Redis的跳跃表的原理的一个简述。
这种跳跃表的实现,其实和二分查找的思路有点接近,只是一方面因为二分查找只能适用于数组,而无法适用于链表,所以为了让链表有二分查找类似的效率,就以空间换时间来达到目的。
跳跃表因为是一个根据分数权重进行排序的列表,可以再很多场景中进行应用,比如排行榜,搜索排序等等。
命令操作:
添加元素,zadd zsetName score1 value1 score2 value2 score3 value3 .....

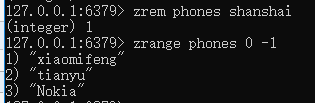
查看所有元素,zrange zsetName 0 -1

查看所有元素,按score逆序排列, zrevrange zsetName 0 -1

元素数量,zcard zsetName
获取指定value的分数, zscore zsetName value

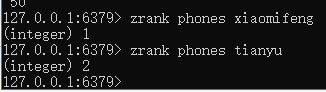
获取指定value的排名,zrank zsetName value(从0开始)
获取指定分值区间中的元素, zrangebyscore zsetName scoreStart scoreEnd(包含上下区间)(注意inf表示无穷大,-inf表示服务券大)

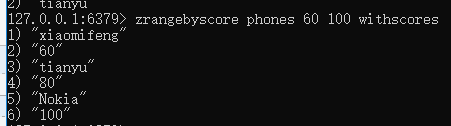
获取指定分值区间中的元素,并且返回分数, zrangebyscore zsetName scoreStart scoreEnd withscores
删除元素,zrem zsetName value
代码调用:
package main
import (
"fmt"
"github.com/garyburd/redigo/redis"
)
func main(){
// 连接redis
conn,err := redis.Dial("tcp", "localhost:6379")
if err != nil {
fmt.Errorf("connection redis failed. error info: ", err)
return
}
// zadd
_,err = conn.Do("zadd", "phones", "100", "Nokia", "80", "tianyu", "60", "xiaomifeng", "50", "shangshai")
if err != nil {
fmt.Errorf("sadd failed, error info: ", err)
return
}
// zrange
result,err := redis.Strings(conn.Do("zrange", "phones", "0", "-1"))
if err != nil {
fmt.Errorf("zrange failed, error info: ", err)
return
}
fmt.Println(result)
// zrevrange
result,err = redis.Strings(conn.Do("zrevrange", "phones", "0", "-1"))
if err != nil {
fmt.Errorf("zrange failed, error info: ", err)
return
}
fmt.Println(result)
// zcard
size,err := conn.Do("zcard", "phones")
if err != nil {
fmt.Errorf("zrange failed, error info: ", err)
return
}
fmt.Println(size)
// zscore
score,err := redis.Int(conn.Do("zscore", "phones", "shangshai"))
if err != nil {
fmt.Errorf("zrange failed, error info: ", err)
return
}
fmt.Println(score)
// zrem
_,err = conn.Do("zrem", "phones", "shangshai")
if err != nil {
fmt.Errorf("zrange failed, error info: ", err)
return
}
fmt.Println("delete shangshai success.")
// 关闭连接
defer conn.Close()
}
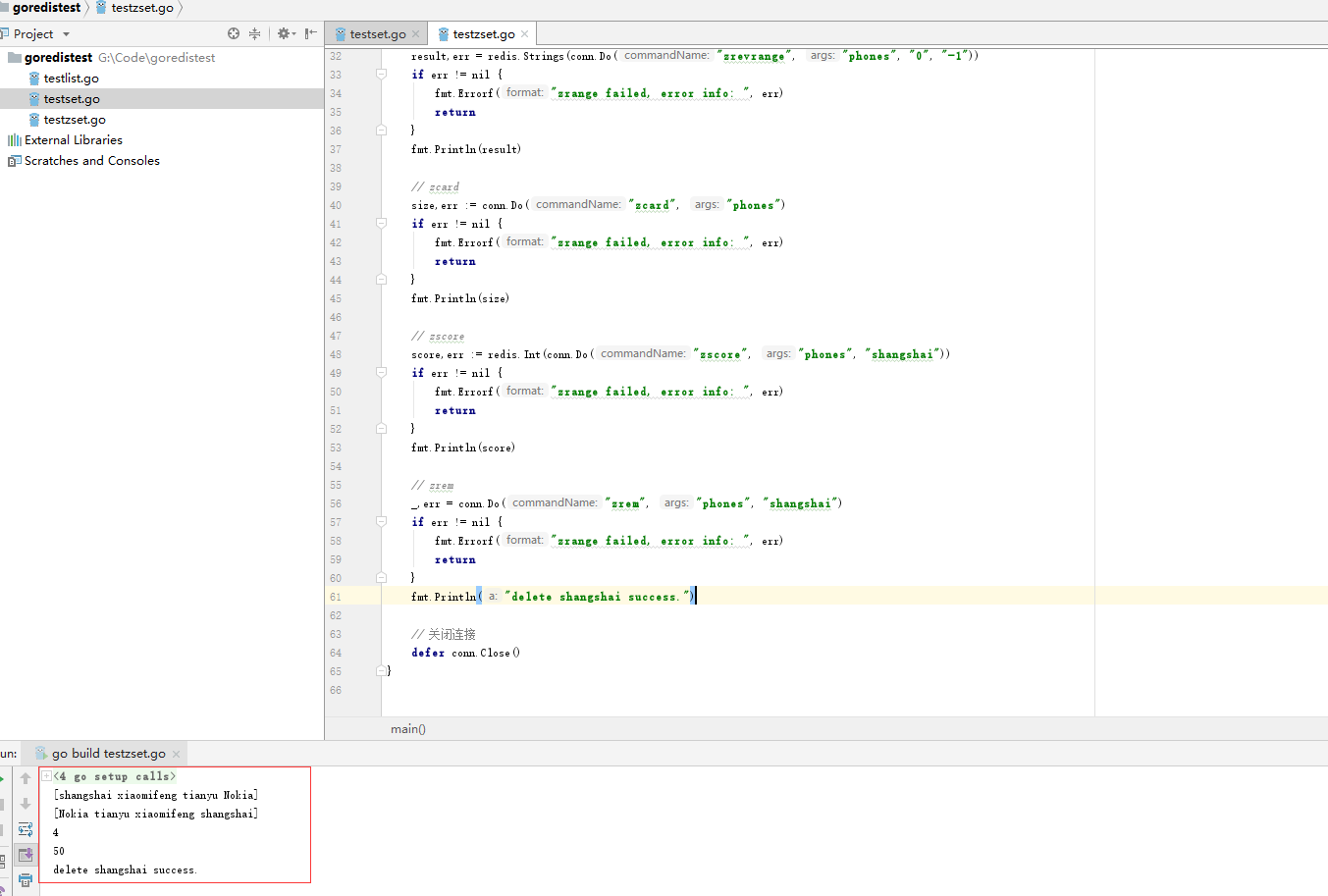
执行效果: