主从复制简介
单机 redis 的风险与问题
- 问题1,机器故障
- 现象:硬盘故障、系统崩溃
- 本质:数据丢失,很可能对业务造成灾难性打击
- 结论:基本上会放弃使用 redis
- 问题2,容量瓶颈
- 现象:内存不足
- 本质:穷,硬件条件跟不上
- 结论:放弃使用 redis
- 结论:为了避免单点 Redis 服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服务器上,连接在一起,并保证数据是同步的。即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现 Redis 的高可用,同时实现数据冗余备份
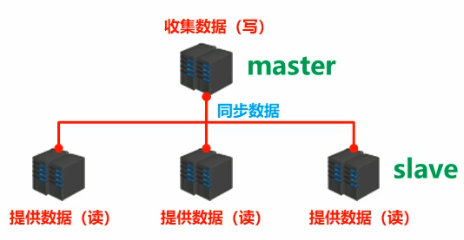
多台服务器连接方案
-
提供数据方:master
主服务器,主节点,主库
主客户端 -
接收数据方:slave
从服务器,从节点,从库
从客户端 -
需要解决的问题:数据同步
-
核心工作:master 的数据复制到 slave 中
-
如果主服务器挂掉的话,我们会在从服务器中选出一个用作主服务器
-
其余方案:
- 多个主服务器(用到哨兵)
- 某些从服务器向下拓扑(会带来一些问题)
主从复制
主从复制即将 master 中的数据即时、有效的复制到 slave 中
特征:一个 master 可以拥有多个 slave,一个 slave 只对应一个 master
职责:
- master:
- 写数据
- 执行写操作时,将出现变化的数据自动同步到 slave
- 读数据(可忽略)
- slave:
- 读数据
- 写数据(禁止)
主动复制作用
- 读写分离:master 写、slave 读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由 slave 分担 master 负载,并根据需求的变化,改变 slave 的数量,通过多个从节点分担数据读取负载,大大提高 Redis 服务器并发量与数据吞吐量
- 故障恢复:当 master 出现问题时,由 slave 提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现 Redis 的高可用方案
主从复制工作流程
总述
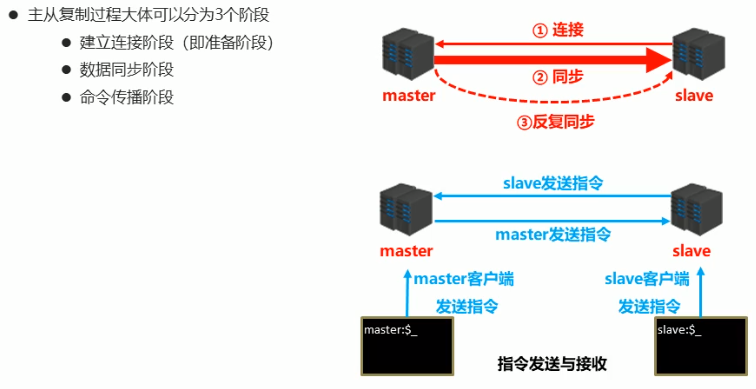
阶段一:建立连接阶段
- 建立 slave 到 master 的连接,使 master 能够识别 slave,并保存 slave 端口号
建立连接阶段工作流程
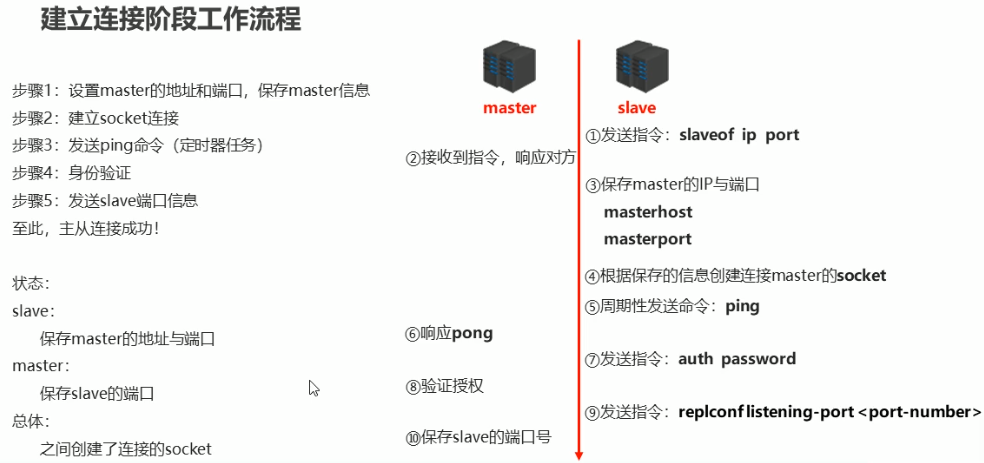
主从连接(slave 连接 master)
-
方式一:slave 客户端发送命令
slaveof <masterip> <masterport> -
方式二:slave 服务器启动参数
redis-server --slaveof <masterip> <masterport> -
方式三:slave 服务器配置文件
slaveof <masterip> <masterport>
连接建立成功后,在 master 服务器的客户端中对数据进行 set age 100 操作后,我们在 slave 服务器的客户端中 get name 就会返回 100,同步数据是他们内部进行的,不需要我们管
主从断开(从服务器主动断开)
- slave 客户端发送命令:
slaveof no one
断开后,slave 中的数据不会再被更新
授权访问
-
master 配置文件设置密码
requirepass <password> -
master 客户端发送命令设置密码
config set requirepass <password> config get requirepass -
slave 客户端发送命令设置密码
auth <password> -
slave 配置文件设置密码
masterauth <password> -
启动客户端设置密码
redis-cli -a <password>
阶段二:数据同步阶段工作流程
- 在 slave 初次连接 master 后,复制 master 中的所有数据到 slave
- 将 slave 的数据库状态更新或 master 当前的数据库状态
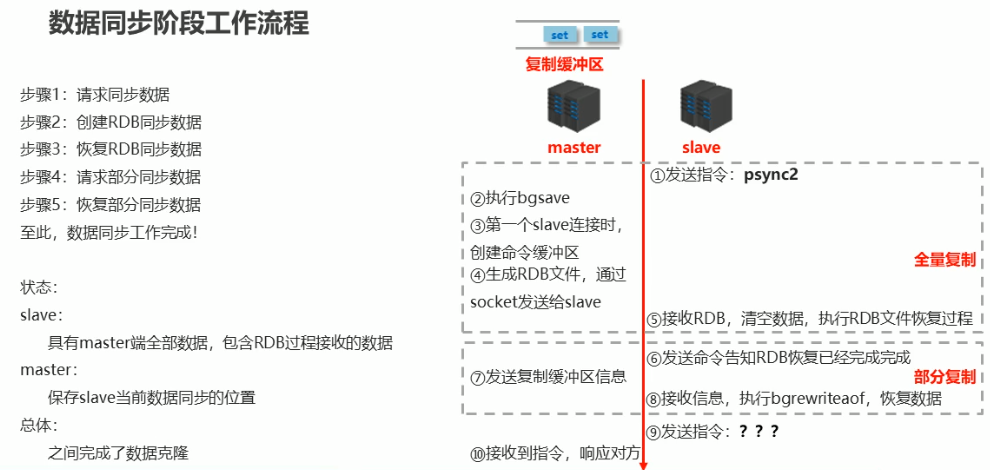
数据同步阶段 master 注意事项
- 如果 master 数据量巨大,数据同步阶段应避开流量高峰期,避免造成 master 阻塞,影响业务正常进行
- 复制缓冲区(环形内存)大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制(也叫增量复制)时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使 slave 陷入死循环状态
repl-backlog-size 1mb - master 单机内存占用主机内存的比例不应过大,建议使用 50%~70% 的内存,留下 30%~50% 的内存用于执行 bgsave 命令和创建复制缓冲区
数据同步阶段 slave 注意事项
- 为避免 slave 进行全量复制、增量复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|no从服务器是否提供过时数据 - 数据同步阶段,master 发送给 slave 信息可以理解 master 是 slave 的一个客户端,主动向 slave 发送命令
- 多个 slave 同时对 master 请求数据同步,master 发送的 RDB 文件增多,会对带宽造成巨大冲击,如果 master 带宽不足,数据同步需要根据业务需求,适量错峰
- slave 过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是 master,也是 slave。注意使用树状结构时,由于层级较深,导致深度越高的 slave 与最顶层 master 间数据同步延迟较大,数据一致性变差,应谨慎选择
阶段三:命令传播阶段
- 当 master 数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
- master 将接收到的数据变更命令发送给 salve, slave 接收命令后执行命令
命令传播阶段的部分复制
- 命令传播阶段出现了断网现象
- 网络闪断闪联 忽略
- 短时间网络中断 部分复制
- 长时间网络中断 全量复制
- 部分复制的三个核心要素
- 服务器的运行id(run_id)
- 主服务器的复制积压缓冲区
- 主从服务器的复制偏移量
服务器运行 ID (run_id)
- 概念:服务器运行 ID 是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行 id
- 组成:运行 id 由 40 位字符组成,是一个随机的十六进制字符
- 作用:运行 id 被用于在服务器间进行传输,识别身份
- 实现方式:运行 id 在每台服务器启动时自动生成,master 在首次连接 slave 时,会将自己的运行 id 发送给 slave,slave 保存此 id,通过 info server 命令,可以查看 run_id
复制缓冲区
- 概念:复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命令,每次传播命令,master 都会将传播的命令记录下来,并存储在复制缓冲区
- 复制缓冲区默认数据存储空间大小是 1M,由于存储空间大小是固定的,当入队元素的数量大于队列长度时,最先入队的元素会被弹出,而新元素会被放入队列
- 由来:每台服务器启动时,如果开启有 AOF 或 被连接成为 master 节点,即创建复制缓冲区
- 作用:用于保存 master 收到的所有指令(仅影响数据变更的指令,例如set, select)
- 数据来源:当 master 接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓存区中
复制缓冲区内部工作原理
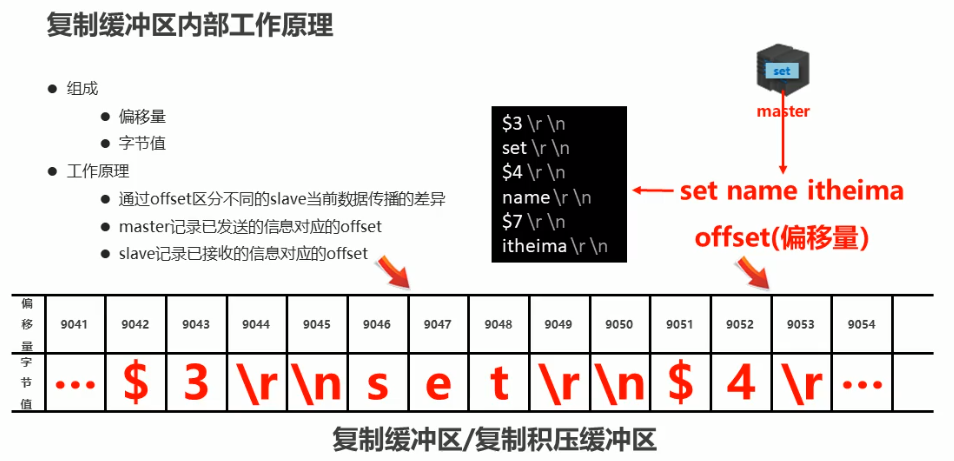
注意:偏移量(offset)是服务端和客户端都会记录的
复制偏移量
- 一个数字,描述复制缓冲区中的指令字节位置
- 分类:
- master 复制偏移量:记录发送给所有 slave 的指令对应的位置(多个)
- slave 复制偏移量:记录 slave 接受 master 发送过来的指令字节对应的位置(一个)
- 数据来源:
master 端:发送一次记录一次
slave 端:接收一次记录一次 - 作用:同步信息,比对 master 与 slave 的差异,当 slave 断线后,恢复数据使用
数据同步 + 命令传播阶段工作流程

心跳机制
- 进入命令传播阶段,master 与 slave 间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
- master 心跳:
- 指令:PING
- 周期:由 repl-ping-slave-period 决定,默认 10 秒
- 作用:判断 slave 是否在线
- 查询:INFO replication 获取 slave 最后一次连接时间间隔,lag 项维持在 0 或 1 视为正常
- slave 心跳任务
- 指令:REPLCONF ACK{offset}
- 周期:1 秒
- 作用1:汇报 slave 自己的复制偏移量,获取最新的数据变更指令
- 作用2:判断 master 是否在线
心跳阶段注意事项
-
当 slave 多数掉线,或延迟过高时,master 为保障数据稳定性,拒绝所有信息同步操作
min-slaves-to-write 2 min-salves-max-lag 8slave 数量少于 2 个,或者所有 slave 的延迟都大于等于10秒时,强制关闭 master 写功能,停止数据同步
-
slave 数量由 slave 发送 REPLCONF ACK 命令做确认
-
slave 延迟由 slave 发送 REPLCONF ACK 命令做确认
主从复制工作流程(完整)

主从复制常见问题
频繁的全量复制


频繁的网络中断


数据不一致
-
问题现象:多个 slave 获取相同数据不同步
-
问题原因:网络信息不同步,数据发送有延迟
-
解决方案
-
优化主从间的网络环境,通常放置在同一个机房,如使用阿里云等云服务要注意此现象
-
监控主从节点延迟(通过 offset)判断,如果 slave 延迟过大,暂时屏蔽程序对该 slave 的数据访问
slave-serve-stale-data yes|no开启后仅响应 info、slaveof等少数命令(慎用,除非对数据一致性要求很高)
-