Kafka是由Linkedin公司开发的,它是一个分布式的,支持多分区、多副本,基于Zookeeper的分布式消息流平台,它同时也是一款基于发布订阅模式的消息引擎系统;Linkedin于2010年将Kafka贡献给了Apache基金会并成为Apache顶级项目。本文主要包括Zookeeper简介、安装、简单操作等;文中所使用到的软件版本:Java 1.8.0_191、Zookeeper 3.6.0、kafka 2.13-2.4.1、Centos 7.6。
1、简介
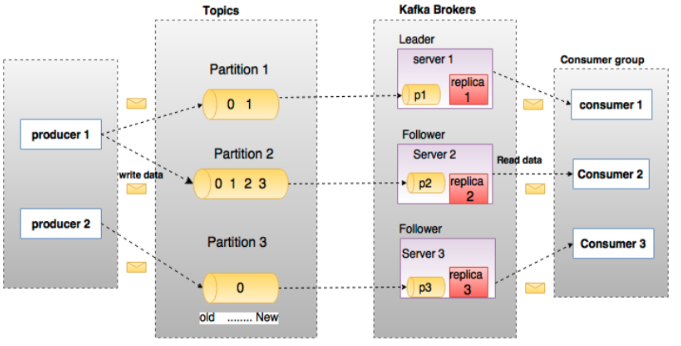
1.1、Broker
Kafka集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据;如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
1.2、Topic(主题)
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。类似于数据库的表名。
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据:一是基于时间,二是基于Partition文件大小。
1.3、Partition(分区)
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
1.4、Producer(生产者)
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
1.5、Consumer(消费者)
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
1.6、Consumer Group(消费者群组)
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group,若不指定group则属于默认的group)。
1.7、Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
1.8、Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower挂掉、卡住或与Leader同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
2、安装
2.1、单机版安装
2.1.1、下载并解压Kafka
http://kafka.apache.org/downloads
tar zxvf kafka_2.13-2.4.1.tgz -C ../app
2.1.2、Zookeeper配置及启停
Kafka依赖Zookeeper需先启动Zookeeper;这里使用Kafka自带的Zookeeper,也可以使用自己单独安装的Zookeeper。
修改config/zookeeper.properties:
dataDir=/home/app/kafka_2.13-2.4.1/data #根据实际情况修改
启停Zookeeper:
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties #启动zookeeper ./zookeeper-server-stop.sh #停止zookeeper
2.1.3、Kafka配置及启停
对应的配置文件为config/server.properties,这里使用默认配置;实际使用过程中可以根据情况修改里面的参数。
启停Kafka:
./kafka-server-start.sh -daemon ../config/server.properties #启动kafka ./kafka-server-stop.sh #停止kafka
2.2、集群安装
这里使用自己单独安装的zookeeper,版本为3.6.0,假设已经安装好了,地址为:10.49.196.20:2181,10.49.196.21:2181,10.49.196.22:2181。安装方法可以参见:Zookeeper入门实战(1)-概念、安装及命令行
2.2.1、集群规划
主机:10.49.196.20,10.49.196.21,10.49.196.22
安装目录都为:/home/hadoop/app
2.2.2、下载并解压Kafka
http://kafka.apache.org/downloads
tar zxvf kafka_2.13-2.4.1.tgz -C /home/hadoop/app
在其中一台机器上解压,然后把解压的包拷贝到其他的机器。
2.2.3、修改配置文件
10.49.196.20:/home/hadoop/app/kafka_2.13-2.4.1/server.properties:
broker.id=1 log.dirs=/home/hadoop/app/kafka_2.13-2.4.1/kafka-logs #该目录需新建 zookeeper.connect=10.49.196.20:2181,10.49.196.21:2181,10.49.196.22:2181/kafka
10.49.196.21:/home/hadoop/app/kafka_2.13-2.4.1/server.properties:
broker.id=2
log.dirs=/home/hadoop/app/kafka_2.13-2.4.1/kafka-logs #该目录需新建
zookeeper.connect=10.49.196.20:2181,10.49.196.21:2181,10.49.196.22:2181/kafka
10.49.196.22:/home/hadoop/app/kafka_2.13-2.4.1/server.properties:
broker.id=3
log.dirs=/home/hadoop/app/kafka_2.13-2.4.1/kafka-logs #该目录需新建
zookeeper.connect=10.49.196.20:2181,10.49.196.21:2181,10.49.196.22:2181/kafka
2.2.4、Kafka启停
启停kafka,依次在各机器上执行:
./kafka-server-start.sh -daemon ../config/server.properties #启动kafka ./kafka-server-stop.sh #停止kafka
3、简单使用
3.1、创建主题
创建一个单分区单副本的主题
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
3.2、查看主题列表
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
3.3、查看主题信息
bin/kafka-topics.sh --bootstrap-server --describe --topic test
3.4、使用生产者发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message #发送的消息
This is another message#发送的消息
3.6、查看消费组信息
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group A
3.5、使用消费者接受消息
4、分区原理
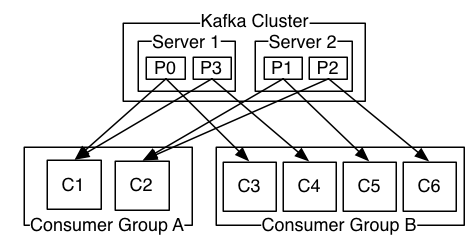
一个topic可以配置几个partition,produce发送的消息分发到不同的partition中,consumer接受数据的时候是按照group来接受,kafka确保每个partition只能被同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费。当consumer的数量大于分区的数量的时候,有的consumer会读取不到数据。
假设一个topic test被groupA消费了,现在启动另外一个新的groupB来消费test,默认test-groupB的offset不是0,而是没有新建立,除非当test有新数据的时候,groupB会收到该数据,该条数据也是第一条数据,groupB的offset也是刚初始化的ofsert, 可以显式的用--from-beginnging 来获取从0开始数据。查看消费组对应topic的offset:
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group A
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。