InputFormat 主要用于描述输入数据的格式, 它提供以下两个功能。
❑数据切分:按照某个策略将输入数据切分成若干个 split, 以便确定 Map Task 个数以及对应的 split。
❑为 Mapper 提供输入数据: 给定某个 split, 能将其解析成一个个 key/value 对。
本文将介绍 Hadoop 如何设计 InputFormat 接口,以及提供了哪些常用的 InputFormat实现。
1 .旧版 API 的 InputFormat 解析
如图所示:

在旧版 API 中, InputFormat 是一个接口 , 它包含两种方法:
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; RecordReader<K, V> getRecordReader(InputSplit split, JobConf job, Reporter reporter) throws IOException;
getSplits 方法主要完成数据切分的功能, 它会尝试着将输入数据切分成 numSplits 个InputSplit。 InputSplit 有以下两个特点。
❑逻辑分片:它只是在逻辑上对输入数据进行分片, 并不会在磁盘上将其切分成分片进行存储。 InputSplit 只记录了分片的元数据信息,比如起始位置、长度以及所在的
节点列表等。
❑可序列化:在 Hadoop 中,对象序列化主要有两个作用:进程间通信和永久存储。 此处,InputSplit 支持序列化操作主要是为了进程间通信。 作业被提交到 JobTracker 之前,Client 会调用作业 InputFormat 中的 getSplits 函数, 并将得到的 InputSplit 序列化到文件中。这样,当作业提交到 JobTracker 端对作业初始化时,可直接读取该文件,解析出所有 InputSplit, 并创建对应的 MapTask。
getRecordReader 方法返回一个RecordReader 对象,该对象可将输入的 InputSplit解析成若干个 key/value 对。 MapReduce 框架在 MapTask 执行过程中,会不断调用RecordReader 对象中的方法, 迭代获取 key/value 对并交给 map() 函数处理, 主要代码(经过简化)如下:
//调用 InputSplit 的 getRecordReader 方法获取 RecordReader<K1, V1> input …… K1 key = input.createKey(); V1 value = input.createValue(); while (input.next(key, value)) { //调用用户编写的 map() 函数 } input.close();
前面分析了 InputFormat 接口的定义, 接下来介绍系统自带的各种 InputFormat 实现。为了方便用户编写 MapReduce 程序, Hadoop 自带了一些针对数据库和文件的 InputFormat实现, 具体如图所示。通常而言用户需要处理的数据均以文件形式存储到 HDFS 上,所以这里重点针对文件的 InputFormat 实现进行讨论。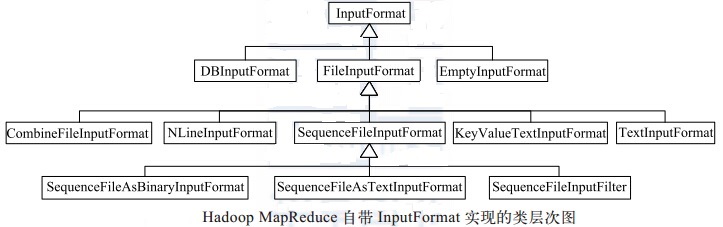
如图所示, 所有基于文件的 InputFormat 实现的基类是 FileInputFormat, 并由此派生出针对文本文件格式的 TextInputFormat、 KeyValueTextInputFormat 和 NLineInputFormat,针对二进制文件格式的 SequenceFileInputFormat 等。 整个基于文件的 InputFormat 体系的设计思路是,由公共基类FileInputFormat 采用统一的方法 对各种输入文件进行切分,比如按照某个固定大小等分,而由各个派生 InputFormat 自己提供机制将进一步解析InputSplit。 对应到具体的实现是,基类 FileInputFormat 提供 getSplits 实现, 而派生类提供getRecordReader 实现。
为了深入理解这些 InputFormat 的实现原理, 选取extInputFormat 与SequenceFileInputFormat 进行重点介绍。
首先介绍基类FileInputFormat的实现。它最重要的功能是为各种 InputFormat 提供统一的getSplits 函数。该函数实现中最核心的两个算法是文件切分算法和 host 选择算法。
(1) 文件切分算法
文件切分算法主要用于确定 InputSplit 的个数以及每个 InputSplit 对应的数据段。FileInputFormat 以文件为单位切分生成 InputSplit。 对于每个文件, 由以下三个属性值确定其对应的 InputSplit 的个数。
❑goalSize : 它是根据用户期望的 InputSplit 数目计算出来的, 即 totalSize/numSplits。其中, totalSize 为文件总大小; numSplits 为用户设定的 MapTask 个数, 默认情况下是 1。
❑minSize: InputSplit 的最小值, 由配置参数 mapred.min.split.size 确定, 默认是 1。
❑blockSize: 文件在 HDFS 中存储的 block 大小, 不同文件可能不同, 默认是 64 MB。这三个参数共同决定 InputSplit 的最终大小, 计算方法如下:
splitSize = max{minSize, min{goalSize, blockSize}}
一旦确定 splitSize 值后, FileInputFormat 将文件依次切成大小为 splitSize 的 InputSplit,最后剩下不足 splitSize 的数据块单独成为一个 InputSplit。
【实例】 输入目录下有三个文件 file1、file2 和 file3,大小依次为 1 MB,32 MB 和250 MB。 若 blockSize 采用 默认值 64 MB, 则不同 minSize 和 goalSize 下, file3 切分结果如表所示(三种情况下, file1 与 file2 切分结果相同, 均为 1 个 InputSplit)。
表-minSize、 goalSize、 splitSize 与 InputSplit 对应关系
| minSize | goalSize | splitSize | file3 对应的 InputSplit 数目 | 输入目 录对应的 InputSplit 总数 |
| 1 MB | totalSize (numSplits=1 ) |
64 MB | 4 | 6 |
| 32 MB | totalSize/5 | 50 MB | 5 | 7 |
| 128 MB | totalSize/2 | 128 MB | 2 | 4 |
结合表和公式可以知道, 如果想让 InputSplit 尺寸大于 block 尺寸, 则直接增大配置参数 mapred.min.split.size 即可。
(2) host 选择算法
待 InputSplit 切分方案确定后,下一步要确定每个 InputSplit 的元数据信息。 这通常由四部分组成:<file, start, length, hosts>, 分别表示 InputSplit 所在的文件、起始位置、长度以及所在的 host(节点)列表。 其中,前三项很容易确定,难点在于 host 列表的选择方法。
InputSplit 的 host 列表选择策略直接影响到运行过程中的任务本地性。 HDFS 上的文件是以 block 为单位组织的,一个大文件对应的block 可能遍布整个 Hadoop 集群, 而 InputSplit 的划分算法可能导致一个 InputSplit 对应多个 block , 这些 block 可能位于不同节点上, 这使得 Hadoop 不可能实现完全的数据本地性。为此,Hadoop 将数据本地性按照代价划分成三个等级:node locality、rack locality 和 datacenter locality(Hadoop 还未实现该 locality 级别)。在进行任务调度时, 会依次考虑这 3 个节点的 locality, 即优先让空闲资源处理本节点上的数据,如果节点上没有可处理的数据,则处理同一个机架上的数据, 最差情况是处理其他机架上的数据(但是必须位于同一个数
据中心)。
虽然 InputSplit 对应的 block 可能位于多个节点上, 但考虑到任务调度的效率,通常不会把所有节点加到 InputSplit 的 host 列表中,而是选择包含(该 InputSplit)数据总量最大的前几个节点(Hadoop 限制最多选择 10 个,多余的会过滤掉),以作为任务调度时判断任务是否具有本地性的主要凭证。为此,FileInputFormat 设计了一个简单有效的启发式算法 :首先按照 rack 包含的数据量对 rack 进行排序, 然后在 rack 内部按照每个 node 包含的数据量对 node 排序, 最后取前 N个node 的 host 作为InputSplit 的 host 列表, 这里的 N为 block副本数。这样,当任务调度器调度 Task 时,只要将 Task 调度给位于 host 列表的节点,就认为该 Task 满足本地性。
【实例】某个 Hadoop 集群的网络拓扑结构如图所示, HDFS中block 副本数为3,某个InputSplit 包含 3 个 block,大小依次是100、150 和 75,很容易计算,4 个rack 包
含的(该 InputSplit 的)数据量分别是175、250、150 和 75。rack2 中的 node3 和 node4,rack1 中的 node1 将被添加到该 InputSplit 的 host 列表中。
从以上 host 选择算法可知, 当 InputSplit 尺寸大于 block 尺寸时, Map Task 并不能实现完全数据本地性, 也就是说, 总有一部分数据需要从远程节点上读取, 因而可以得出以下结论:
当使用基于 FileInputFormat 实现 InputFormat 时, 为了提高 Map Task 的数据本地性,应尽量使 InputSplit 大小与 block 大小相同。
分析完 FileInputFormat 实现方法, 接下来分析派生类 TextInputFormat 与 SequenceFileInputFormat 的实现。前面提到, 由派生类实现 getRecordReader 函数, 该函数返回一个 RecordReader 对象。它实现了类似于迭代器的功能, 将某个 InputSplit 解析成一个个 key/value 对。在具体实现时, RecordReader 应考虑以下两点:
❑定位记录边界:为了能够识别一条完整的记录,记录之间应该添加一些同步标识。对于 TextInputFormat, 每两条记录之间存在换行符;对于 SequenceFileInputFormat,每隔若干条记录会添加固定长度的同步字符串。 通过换行符或者同步字符串, 它们很容易定位到一个完整记录的起始位置。另外,由于FileInputFormat 仅仅按照数据量多少对文件进行切分, 因而 InputSplit 的第一条记录和最后一条记录可能会被从中间切开。 为了解决这种记录跨越 InputSplit 的读取问 题, RecordReader 规定每个InputSplit 的第一条不完整记录划给前一个 InputSplit 处理。
❑解析 key/value:定位到一条新的记录后, 需将该记录分解成 key 和 value 两部分。对于TextInputFormat, 每一行的内容即为 value,而该行在整个文件中的偏移量为key。对于 SequenceFileInputFormat, 每条记录的格式为:
[record length] [key length] [key] [value]
其中, 前两个字段分别是整条记录的长度和 key 的长度, 均为 4 字节, 后两个字段分别是 key 和 value 的内容。 知道每条记录的格式后, 很容易解析出 key 和 value。
2. 新版 API 的 InputFormat 解析
新版API的InputFormat 类图如图所示。新 API 与旧 API 比较,在形式上发生了较大变化,但仔细分析,发现仅仅是对之前的一些类进行了封装。 正如前面介绍的那样,通过封装,使接口的易用性和扩展性得以增强。
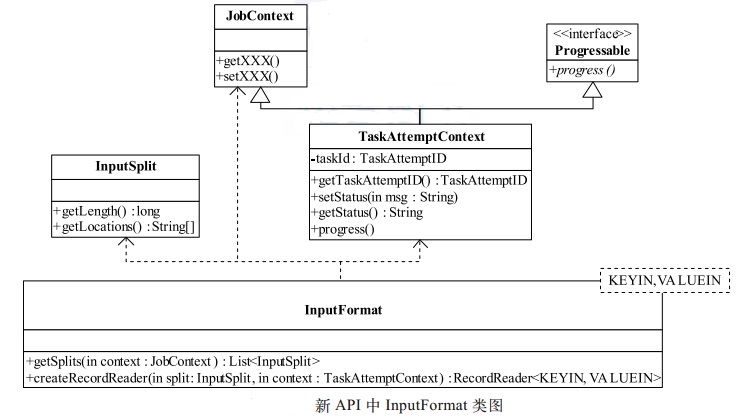
public abstract class InputFormat<K, V> { public abstract List<InputSplit> getSplits(JobContext context ) throws IOException, InterruptedException; public abstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context ) throws IOException, InterruptedException; }
查看InputSplit.java文件源代码:
public abstract class InputSplit { /** * 获取split的大小, 这样就能将输入的splits按照大小排序. * @return split的字节大小 * @throws IOException * @throws InterruptedException */ public abstract long getLength() throws IOException, InterruptedException; /** * 通过name获取那些及将定位的nodes列表,其中的数据为split准备 * 位置不必序列化 * @return a new array of the node nodes. * @throws IOException * @throws InterruptedException */ public abstract String[] getLocations() throws IOException, InterruptedException; }
此外, 对于基类 FileInputFormat, 新版 API 中有一个值得注意的改动 : InputSplit 划分算法不再考虑用户设定的 Map Task 个数, 而用 mapred.max.split.size( 记为 maxSize) 代替,即 InputSplit 大小的计算公式变为:
splitSize = max{minSize, min{maxSize, blockSize}}
参考资料
《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》