SubPage 级别的内存分配:
通过之前的学习我们知道, 如果我们分配一个缓冲区大小远小于page, 则直接在一个page 上进行分配则会造成内存浪费, 所以需要将page 继续进行切分成多个子块进行分配, 子块分配的个数根据你要分配的缓冲区大小而定, 比如只需要分配1KB 的内存, 就会将一个page 分成8 等分。简单起见, 我们这里仅仅以16 字节为例, 跟踪其分配逻辑。在分析其逻辑前, 首先看PoolArean 的一个属性:
private final PoolSubpage<T>[] tinySubpagePools;
这个属性是一个PoolSubpage 的数组, 有点类似于一个subpage 的缓存, 我们创建一个subpage 之后, 会将创建的subpage 与该属性其中每个关联, 下次在分配的时候可以直接通过该属性的元素去找关联的subpage。我们其中是在构造方法中初始化的, 看构造方法中其初始化代码:
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools); for (int i = 0; i < tinySubpagePools.length; i ++) { tinySubpagePools[i] = newSubpagePoolHead(pageSize); }
这里为numTinySubpagePools 为32,跟到newSubpagePoolArray(numTinySubpagePools)方法中:
private PoolSubpage<T>[] newSubpagePoolArray(int size) { return new PoolSubpage[size]; }
这里直接创建了一个PoolSubpage 数组, 长度为32,在构造方法中创建完毕之后, 会通过循环为其赋值。继续跟到newSubpagePoolHead()方法中:
private PoolSubpage<T> newSubpagePoolHead(int pageSize) { PoolSubpage<T> head = new PoolSubpage<T>(pageSize); head.prev = head; head.next = head; return head; }
在newSubpagePoolHead()方法中创建了一个PoolSubpage 对象head。这种写法我们知道Subpage 其实也是个双向链表, 这里的将head 的上一个节点和下一个节点都设置为自身, 有关PoolSubpage 的关联关系, 我们稍后分析。这样通过循环创建PoolSubpage, 总共会创建出32 个subpage, 其中每个subpage 实际代表一块内存大小:

tinySubPagePools 的结构就有点类似缓存数组tinySubPageDirectCaches 的结构。了解了tinySubpagePools属性, 我们看PoolArean 的allocate 方法, 也就是缓冲区的入口方法:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { //规格化 reqCapacity=256 final int normCapacity = normalizeCapacity(reqCapacity); if (isTinyOrSmall(normCapacity)) { // capacity < pageSize int tableIdx; PoolSubpage<T>[] table; //判断是不是tiny boolean tiny = isTiny(normCapacity); if (tiny) { // < 512//缓存分配 if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; }//通过tinyIdx 拿到tableIdx tableIdx = tinyIdx(normCapacity); //subpage 的数组 table = tinySubpagePools; } else { if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; } tableIdx = smallIdx(normCapacity); table = smallSubpagePools; } //拿到对应的节点 final PoolSubpage<T> head = table[tableIdx]; synchronized (head) { final PoolSubpage<T> s = head.next; //默认情况下, head 的next 也是自身 if (s != head) { assert s.doNotDestroy && s.elemSize == normCapacity; long handle = s.allocate(); assert handle >= 0; s.chunk.initBufWithSubpage(buf, handle, reqCapacity); if (tiny) { allocationsTiny.increment(); } else { allocationsSmall.increment(); } return; } } allocateNormal(buf, reqCapacity, normCapacity); return; } if (normCapacity <= chunkSize) { //首先在缓存上进行内存分配 if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) { // was able to allocate out of the cache so move on return; }//分配不成功, 做实际的内存分配 allocateNormal(buf, reqCapacity, normCapacity); } else {//大于这个值, 就不在缓存上分配 // Huge allocations are never served via the cache so just call allocateHuge allocateHuge(buf, reqCapacity); } }
之前我们最这个方法剖析过在page 级别相关内存分配逻辑, 先在我们来看subpage 级别分配的相关逻辑。假设我们分配16 字节的缓冲区, isTinyOrSmall(normCapacity)就会返回true, 进入if 块,同样if (tiny)这里会返回true, 继续跟到if (tiny)中的逻辑。首先会在缓存中分配缓冲区, 如果分配不到, 就开辟一块内存进行内存分配,先看这一步:
tableIdx = tinyIdx(normCapacity);
这里通过normCapacity 拿到tableIdx, 我们跟进去:
static int tinyIdx(int normCapacity) { return normCapacity >>> 4; }
这里将normCapacity 除以16, 其实也就是1。我们回到PoolArena 的allocate()方法继续看:
table = tinySubpagePools;
这里将tinySubpagePools 赋值到局部变量table 中, 继续往下看:final PoolSubpage<T> head = table[tableIdx] 这步时通过下标拿到一个PoolSubpage, 因为我们以16 字节为例, 所以我们拿到下标为1 的PoolSubpage, 对应的内存大小也就是16Byte。再看final PoolSubpage<T> s = head.next 这一步, 跟我们刚才了解的的tinySubpagePools 属性, 默认情况下head.next 也是自身, 所以if (s != head)会返回false,我们继续往下看,会走到allocateNormal(buf, reqCapacity, normCapacity)这个方法:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) { //首先在原来的chunk 上进行内存分配(1) if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) || q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) || q075.allocate(buf, reqCapacity, normCapacity)) { ++allocationsNormal; return; } //创建chunk 进行内存分配(2) // Add a new chunk. PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize); long handle = c.allocate(normCapacity); ++allocationsNormal; assert handle > 0; //初始化byteBuf(3) c.initBuf(buf, handle, reqCapacity); qInit.add(c); }
这里的逻辑我们之前的已经剖析过, 首先在原来的chunk 中分配, 如果分配不成功, 则会创建chunk 进行分配。我们看这一步long handle = c.allocate(normCapacity) ,跟到allocate(normCapacity)方法中:
long allocate(int normCapacity) { if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize return allocateRun(normCapacity); } else { return allocateSubpage(normCapacity); } }
我们分析page 级别分配的时候, 剖析的是allocateRun(normCapacity)方法。因为这里我们是以16 字节举例,所以这次我们剖析allocateSubpage(normCapacity)方法, 也就是在subpage 级别进行内存分配。
private long allocateSubpage(int normCapacity) { PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity); synchronized (head) { int d = maxOrder; //表示在第11 层分配节点 int id = allocateNode(d); if (id < 0) { return id; } //获取初始化的subpage final PoolSubpage<T>[] subpages = this.subpages; final int pageSize = this.pageSize; freeBytes -= pageSize; //表示第几个subpageIdx int subpageIdx = subpageIdx(id); PoolSubpage<T> subpage = subpages[subpageIdx]; if (subpage == null) { //如果subpage 为空 subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity); //则将当前的下标赋值为subpage subpages[subpageIdx] = subpage; } else { subpage.init(head, normCapacity); }
//取出一个子page return subpage.allocate(); } }
首先, 通过PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity) 这种方式找到head 节点, 实际上这里head, 就是我们刚才分析的tinySubpagePools 属性的第一个节点, 也就是对应16B 的那个节点。int d =maxOrder 是将11 赋值给d, 也就是在内存树的第11 层取节点, 这部分在Page分配时剖析过了。int id = allocateNode(d) 这里获取的是分析过的, 字节数组memoryMap 的下标, 这里指向一个page, 如果第一次分配, 指向的是0-8k 的那个page, 上一小节对此进行详细的剖析这里不再赘述。final PoolSubpage<T>[] subpages = this.subpages这一步, 是拿到PoolChunk 中成员变量subpages 的值, 也是个PoolSubpage 的数组, 在PoolChunk 进行初始化的时候, 也会初始化该数组, 长度为2048。也就是说每个chunk 都维护着一个subpage 的列表, 如果每一个page 级别的内存都需要被切分成子page, 则会将这个这个page 放入该列表中, 专门用于分配子page, 所以这个列表中的subpage, 其实就是一个用于切分的page。

int subpageIdx = subpageIdx(id) 这一步是通过id 拿到这个PoolSubpage 数组的下标, 如果id 对应的page 是0-8k的节点, 这里拿到的下标就是0。在if (subpage == null) 中, 因为默认subpages 只是创建一个数组, 并没有往数组中赋值, 所以第一次走到这里会返回true, 跟到if 块中:
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
这里通过new PoolSubpage 创建一个新的subpage 之后, 通过subpages[subpageIdx] = subpage 这种方式将新创建的subpage 根据下标赋值到subpages 中的元素中。在new PoolSubpage 的构造方法中, 传入head, 就是我们刚才提到过的tinySubpagePools 属性中的节点, 如果我们分配的16 字节的缓冲区, 则这里对应的就是第一个节点,我们跟到PoolSubpage 的构造方法中:
PoolSubpage(PoolSubpage<T> head, PoolChunk<T> chunk, int memoryMapIdx, int runOffset, int pageSize, int elemSize) { this.chunk = chunk; this.memoryMapIdx = memoryMapIdx; this.runOffset = runOffset; this.pageSize = pageSize; bitmap = new long[pageSize >>> 10]; // pageSize / 16 / 64 init(head, elemSize); }
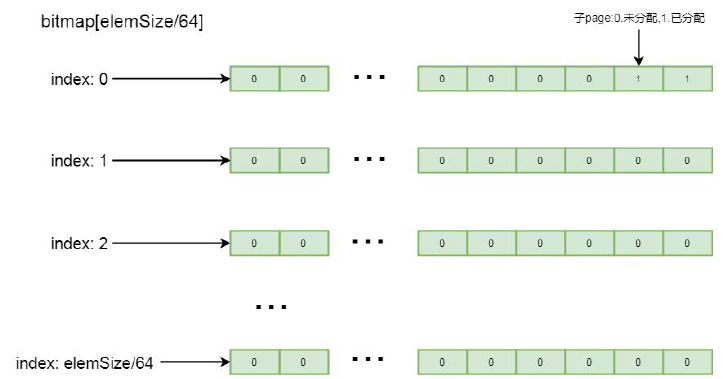
这里重点关注属性bitmap, 这是一个long 类型的数组, 初始大小为8, 这里只是初始化的大小, 真正的大小要根据将page 切分多少块而确定,这里将属性进行了赋值, 我们跟到init()方法中:
void init(PoolSubpage<T> head, int elemSize) { doNotDestroy = true; this.elemSize = elemSize; if (elemSize != 0) { maxNumElems = numAvail = pageSize / elemSize; nextAvail = 0; bitmapLength = maxNumElems >>> 6; if ((maxNumElems & 63) != 0) { bitmapLength ++; } for (int i = 0; i < bitmapLength; i ++) {
//bitmap 标识哪个子page 被分配
//0 标识未分配, 1 表示已分配 bitmap[i] = 0; } }/加到arena 里面 addToPool(head);
}
this.elemSize = elemSize 表示保存当前分配的缓冲区大小, 这里我们以16 字节举例, 所以这里是16。maxNumElems= numAvail = pageSize / elemSize 这里初始化了两个属性maxNumElems, numAvail, 值都为pageSize / elemSize,表示一个page 大小除以分配的缓冲区大小, 也就是表示当前page 被划分了多少分。numAvail 则表示剩余可用的块数, 由于第一次分配都是可用的, 所以numAvail=maxNumElems;bitmapLength 表示bitmap 的实际大小, 刚才我们分析过, bitmap 初始化的大小为8, 但实际上并不一定需要8 个元素,元素个数要根据page 切分的子块而定, 这里的大小是所切分的子块数除以64。再往下看, if ((maxNumElems & 63) != 0) 判断maxNumElems 也就是当前配置所切分的子块是不是64 的倍数, 如果不是, 则bitmapLength 加1,最后通过循环, 将其分配的大小中的元素赋值为0。
这里详细说明一下bitmap, 这里是个long 类型的数组, long 数组中的每一个值, 也就是long 类型的数字, 其中的每一个比特位, 都标记着page 中每一个子块的内存是否已分配, 如果比特位是1, 表示该子块已分配, 如果比特位是0,表示该子块未分配, 标记顺序是其二进制数从低位到高位进行排列。我们应该知道为什么bitmap 大小要设置为子块数量除以64, 因为long 类型的数字是64 位, 每一个元素能记录64 个子块的数量, 这样就可以通过子page 个数除以64的方式决定bitmap 中元素的数量。如果子块不能整除64, 则通过元素数量+1 方式, 除以64 之后剩余的子块通过long中比特位由低到高进行排列记录,其逻辑结构如下图所示:
进入PoolSubpage 的addToPool(head)方法:
private void addToPool(PoolSubpage<T> head) { assert prev == null && next == null; prev = head; next = head.next; next.prev = this; head.next = this; }
这里的head 我们刚才讲过, 是Arena 中数组tinySubpagePools 中的元素, 通过以上逻辑, 就会将新创建的Subpage通过双向链表的方式关联到tinySubpagePools 中的元素, 我们以16 字节为例, 关联关系如图:
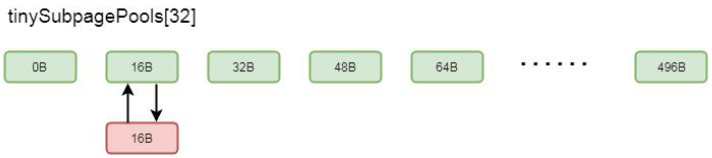
这样, 下次如果还需要分配16 字节的内存, 就可以通过tinySubpagePools 找到其元素关联的subpage 进行分配了。我们再回到PoolChunk 的allocateSubpage()方法,创建完了一个subpage, 我们就可以通过subpage.allocate()方法进行内存分配了。我们跟到allocate()方法中:
long allocate() { if (elemSize == 0) { return toHandle(0); } if (numAvail == 0 || !doNotDestroy) { return -1; }
//取一个bitmap 中可用的id(绝对id) final int bitmapIdx = getNextAvail(); //除以64(bitmap 的相对下标) int q = bitmapIdx >>> 6; //除以64 取余, 其实就是当前绝对id 的偏移量 int r = bitmapIdx & 63; assert (bitmap[q] >>> r & 1) == 0; //当前位标记为1 bitmap[q] |= 1L << r; //如果可用的子page 为0 //可用的子page-1 if (-- numAvail == 0) { //则移除相关子page removeFromPool(); }
//bitmapIdx 转换成handler return toHandle(bitmapIdx); }
这里的逻辑看起来比较复杂, 我们一点点来剖析,首先看:
final int bitmapIdx = getNextAvail();
其中bitmapIdx 表示从bitmap 中找到一个可用的bit 位的下标, 注意, 这里是bit 的下标, 并不是数组的下标, 我们之前分析过, 因为每一比特位代表一个子块的内存分配情况, 通过这个下标就可以知道那个比特位是未分配状态,我们跟进去:
private int getNextAvail() { int nextAvail = this.nextAvail; if (nextAvail >= 0) {
//一个子page 被释放之后, 会记录当前子page 的bitmapIdx 的位置, 下次分配可以直接通过bitmapIdx 拿到一个子page this.nextAvail = -1; return nextAvail; } return findNextAvail(); }
上述代码片段中的nextAvail, 表示下一个可用的bitmapIdx, 在释放的时候的会被标记, 标记被释放的子块对应bitmapIdx 的下标, 如果<0 则代表没有被释放的子块, 则通过findNextAvail 方法进行查找,继续跟进findNextAvail()方法:
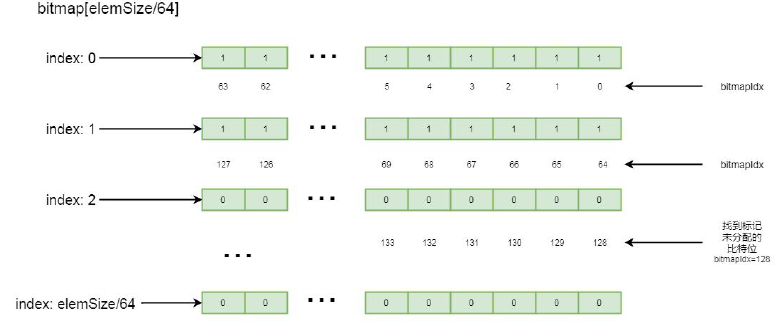
private int findNextAvail() { //当前long 数组 final long[] bitmap = this.bitmap; //获取其长度 final int bitmapLength = this.bitmapLength; for (int i = 0; i < bitmapLength; i ++) { //第i 个 long bits = bitmap[i]; //!=-1 说明64 位没有全部占满 if (~bits != 0) { //找下一个节点 return findNextAvail0(i, bits); } }
return -1; }
这里会遍历bitmap 中的每一个元素, 如果当前元素中所有的比特位并没有全部标记被使用, 则通过findNextAvail0(i,bits)方法一个一个往后找标记未使用的比特位。再继续跟findNextAvail0():
private int findNextAvail0(int i, long bits) { //多少份 final int maxNumElems = this.maxNumElems; //乘以64, 代表当前long 的第一个下标 final int baseVal = i << 6; //循环64 次(指代当前的下标) for (int j = 0; j < 64; j ++) { //第一位为0(如果是2 的倍数, 则第一位就是0) if ((bits & 1) == 0) { //这里相当于加, 将i*64 之后加上j, 获取绝对下标 int val = baseVal | j; //小于块数(不能越界) if (val < maxNumElems) { return val; } else { break; } }
//当前下标不为0 //右移一位 bits >>>= 1; }
return -1; }
这里从当前元素的第一个比特位开始找, 直到找到一个标记为0 的比特位, 并返回当前比特位的下标, 大致流程如下图所示:
我们回到allocate()方法中:
long allocate() { if (elemSize == 0) { return toHandle(0); } if (numAvail == 0 || !doNotDestroy) { return -1; } //取一个bitmap 中可用的id(绝对id) final int bitmapIdx = getNextAvail(); //除以64(bitmap 的相对下标) int q = bitmapIdx >>> 6; //除以64 取余, 其实就是当前绝对id 的偏移量 int r = bitmapIdx & 63; assert (bitmap[q] >>> r & 1) == 0; //当前位标记为1 bitmap[q] |= 1L << r; //如果可用的子page 为0 //可用的子page-1 if (-- numAvail == 0) { //则移除相关子page removeFromPool(); } //bitmapIdx 转换成handler return toHandle(bitmapIdx); }
找到可用的bitmapIdx 之后, 通过int q = bitmapIdx >>> 6 获取bitmap 中bitmapIdx 所属元素的数组下标。int r =bitmapIdx & 63 表示获取bitmapIdx 的位置是从当前元素最低位开始的第几个比特位。bitmap[q] |= 1L << r 是将bitmap 的位置设置为不可用, 也就是比特位设置为1, 表示已占用。然后将可用子配置的数量numAvail 减1。如果没有可用子page 的数量, 则会将PoolArena 中的数组tinySubpagePools 所关联的subpage 进行移除。最后通过toHandle(bitmapIdx)获取当前子块的handle, 上一小节我们知道handle 指向的是当前chunk 中的唯一的一块内存, 我们跟进toHandle(bitmapIdx)中:
private long toHandle(int bitmapIdx) { return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx; }
(long) bitmapIdx << 32 是将bitmapIdx 右移32 位, 而32 位正好是一个int 的长度, 这样, 通过(long) bitmapIdx <<32 | memoryMapIdx 计算, 就可以将memoryMapIdx, 也就是page 所属的下标的二进制数保存在(long) bitmapIdx<< 32 的低32 位中。0x4000000000000000L 是一个最高位是1 并且所有低位都是0 的二进制数, 这样通过按位或的方式可以将(long) bitmapIdx << 32 | memoryMapIdx 计算出来的结果保存在0x4000000000000000L 的所有低位中,这样, 返回对的数字就可以指向chunk 中唯一的一块内存,我们回到PoolArena 的allocateNormal 方法中:
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) { //首先在原来的chunk 上进行内存分配(1) if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) || q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) || q075.allocate(buf, reqCapacity, normCapacity)) { ++allocationsNormal; return; } //创建chunk 进行内存分配(2) PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize); long handle = c.allocate(normCapacity); ++allocationsNormal; assert handle > 0; //初始化byteBuf(3) c.initBuf(buf, handle, reqCapacity); qInit.add(c); }
分析完了long handle = c.allocate(normCapacity)这步, 这里返回的handle 就指向chunk 中的某个page 中的某个子块所对应的连续内存。最后, 通过iniBuf 初始化之后, 将创建的chunk 加到ChunkList 里面,我们跟到initBuf 方法中:
void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) { int memoryMapIdx = memoryMapIdx(handle); //bitmapIdx 是后面分配subpage 时候使用到的 int bitmapIdx = bitmapIdx(handle); if (bitmapIdx == 0) { byte val = value(memoryMapIdx); assert val == unusable : String.valueOf(val); //runOffset(memoryMapIdx):偏移量 //runLength(memoryMapIdx):当前节点的长度 buf.init(this, handle, runOffset(memoryMapIdx), reqCapacity, runLength(memoryMapIdx), arena.parent.threadCache()); } else { initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity); } }
这部分在前面我们分析过, 相信大家不会陌生, 这里有区别的是if (bitmapIdx == 0) 的判断, 这里的bitmapIdx 不会是0, 这样, 就会走到initBufWithSubpage(buf, handle, bitmapIdx, reqCapacity)方法中,跟到initBufWithSubpage()方法:
private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) { assert bitmapIdx != 0; int memoryMapIdx = memoryMapIdx(handle); PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)]; assert subpage.doNotDestroy; assert reqCapacity <= subpage.elemSize; buf.init( this, handle, runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize, reqCapacity, subpage.elemSize, arena.parent.threadCache()); }
首先拿到memoryMapIdx, 这里会将我们之前计算handle 传入, 跟进去:
private static int memoryMapIdx(long handle) { return (int) handle; }
这里将其强制转化为int 类型, 也就是去掉高32 位, 这样就得到memoryMapIdx,回到initBufWithSubpage 方法中:我们注意在buf 调用init 方法中的一个参数: runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) *subpage.elemSize,这里的偏移量就是, 原来page 的偏移量+子块的偏移量:bitmapIdx & 0x3FFFFFFF 代表当前分配的子page 是属于第几个子page。(bitmapIdx & 0x3FFFFFFF) * subpage.elemSize 表示在当前page 的偏移量。这样, 分配的ByteBuf 在内存读写的时候, 就会根据偏移量进行读写。最后,我们跟到init()方法中:
void init(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) { //初始化 assert handle >= 0; assert chunk != null; //在哪一块内存上进行分配的 this.chunk = chunk; //这一块内存上的哪一块连续内存 this.handle = handle; memory = chunk.memory; this.offset = offset; this.length = length; this.maxLength = maxLength; tmpNioBuf = null; this.cache = cache; }
这里又是我们熟悉的逻辑, 初始化了属性之后, 一个缓冲区分配完成,以上就是Subpage 级别的缓冲区分配逻辑。