作为一个内存数据库,redis也总是免不了有各种各样的问题,这篇文章主要是针对其中三个问题进行讲解:缓存穿透、缓存击穿和缓存雪崩。并给出一些解决方案。这三个问题是基本问题也是面试常问问题。
这篇文章我参考了很多篇,发现写的基本上一样,所以在此基础之上进行改进。内容是我在某字母网站看的尚硅谷的教程总结的。特在此说明。
一、缓存穿透
1、概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
为了避免缓存穿透其实有很多种解决方案。下面介绍几种。
2、解决方案
(1)布隆过滤器
布隆过滤器是一种数据结构,垃圾网站和正常网站加起来全世界据统计也有几十亿个。网警要过滤这些垃圾网站,总不能到数据库里面一个一个去比较吧,这就可以使用布隆过滤器。假设我们存储一亿个垃圾网站地址。
可以先有一亿个二进制比特,然后网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。接下来用一个随机数产生器 G 把这八个信息指纹映射到 1 到1亿中的八个自然数 g1, g2, …,g8。最后把这八个位置的二进制全部设置为一。过程如下:
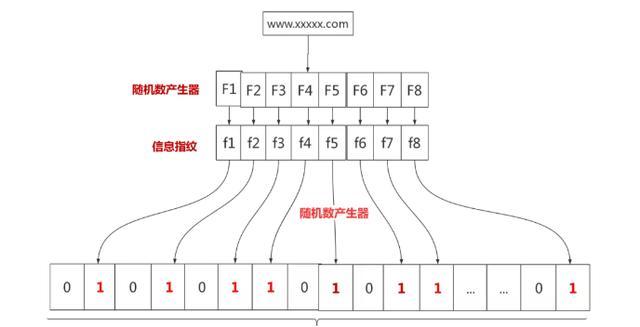
有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,首先将可疑网站通过哈希映射到1亿个比特数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。
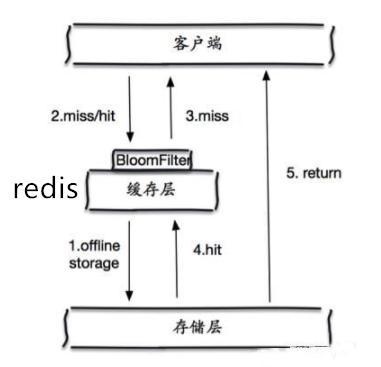
这个形式很简单。
(2)缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;

但是这种方法会存在两个问题:
如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
二、缓存击穿
1、概念
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
2、解决方案
可以将热点数据设置为永远不过期;或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
三、缓存雪崩
1、概念
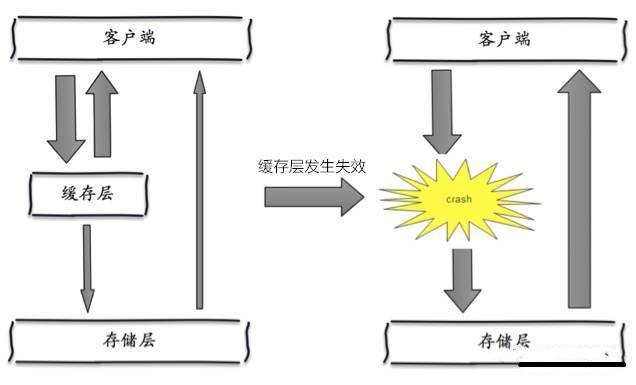
缓存雪崩是指当缓存服务器重启、宕机或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统(比如DB)带来很大压力。
缓存层出现了错误,不能正常工作了。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
比如系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
2、解决方案
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
3、总结
缓存雪崩的事前事中事后的解决方案如下。
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
用户发送一个请求,系统 A 收到请求后,先查本地 ehcache 缓存,如果没查到再查 redis。如果 ehcache 和 redis 都没有,再查数据库,将数据库中的结果,写入 ehcache 和 redis 中。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空白的值。
好处:
- 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。
- 只要数据库不死,就是说,对用户来说,2/5 的请求都是可以被处理的。
- 只要有 2/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。
http://baijiahao.baidu.com/s?id=1655304940308056733&wfr=spider&for=pc