介绍
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
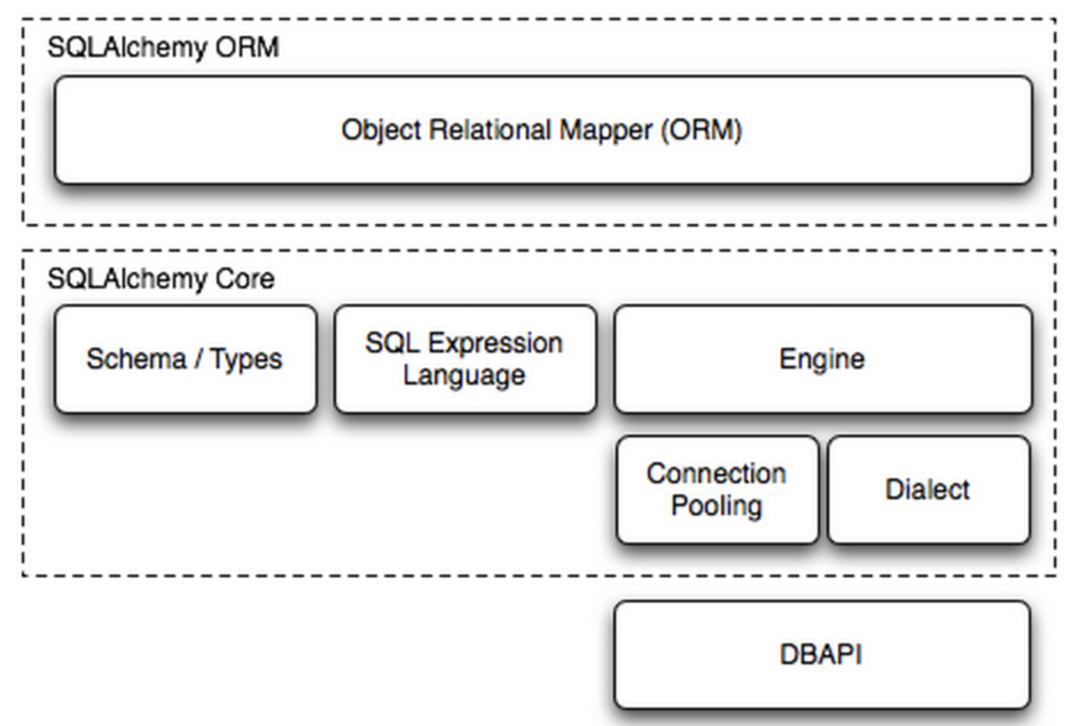
组成部分:
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
安装
pip install SQLAlchemy
使用
执行原生sql语句
create_engine 方法进行数据库连接,返回一个 db 对象。参数echo = True可以在控制台打印sql语句
通过这个engine对象可以直接execute 进行查询,例如 engine.execute("SELECT * FROM user") 也可以通过 engine 获取连接在查询,例如 conn = engine.connect() 通过 conn.execute()方法进行查询。两者有什么差别呢?
- 直接使用engine的execute执行sql的方式, 叫做connnectionless执行,
- 借助 engine.connect()获取conn, 然后通过conn执行sql, 叫做connection执行
主要差别在于是否使用transaction模式, 如果不涉及transaction, 两种方法效果是一样的. 官网推荐使用后者。
使用engine的execute执行sql:
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s8?charset=utf8")
cur = engine.execute('select * from users')
result = cur.fetchall()
print(result)
使用engine.connect()执行sql语句:
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s8?charset=utf8")
conn = engine.connect()
cur = conn.execute('select * from users')
result = cur.fetchall()
print(result)
使用连接池
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s8?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
conn = engine.raw_connection()
cursor = conn.cursor()
cursor.execute("select * from users")
result = cursor.fetchall()
print(result)
cursor.close()
conn.close()
ORM
创建一个简单的表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
# 创建连接
engine = create_engine("mysql+pymysql://root:root@192.168.56.11/oldboydb",encoding='utf-8',echo=True)
#生成ORM基类
Base=declarative_base()
class User(Base):
__tablename__ = 'user' #表名
id = Column(Integer,primary_key=True) #字段,整形,主键 column是导入的
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) #在engine连接的数据库里创建表结构
常用字段
Integer/BigInteger/SmallInteger # 整形. Boolean # 布尔类型. Python 中表现为 True/False , 数据库根据支持情况, 表现为 BOOLEAN 或SMALLINT . 实例化时可以指定是否创建约束(默认创建). Date/DateTime/Time (timezone=False) # 日期类型, Time 和 DateTime 实例化时可以指定是否带时区信息. Interval # 时间偏差类型. 在 Python 中表现为 datetime.timedelta() , 数据库不支持此类型则存为日期. Enum (*enums, **kw) # 枚举类型, 根据数据库支持情况, SQLAlchemy 会使用原生支持或者使用 VARCHAR 类型附加约束的方式实现. 原生支持中涉及新类型创建, 细节在实例化时控制. Float # 浮点小数. Numeric (precision=None, scale=None, decimal_return_scale=None, ...) # 定点小数, Python 中表现为 Decimal . LargeBinary (length=None) # 字节数据. 根据数据库实现, 在实例化时可能需要指定大小. PickleType # Python 对象的序列化类型. String (length=None, collation=None, ...) # 字符串类型, Python 中表现为 Unicode , 数据库表现为 VARCHAR , 通常都需要指定长度. Unicode # 类似与字符串类型, 在某些数据库实现下, 会明确表示支持非 ASCII 字符. 同时输入输出也强制是 Unicode 类型. Text # 长文本类型, Python 表现为 Unicode , 数据库表现为 TEXT .
Column指定的一些字段参数
default # 默认值,时间字段的默认值datetime.datetime.now不能加(),否则会执行生成固定值 primary_key=True # 设置为主键 autoincrement=True # 主键的自增 index=True # 作为索引 nullable=True # 是否可以为空
表的参数
# 在类下定义__table_args__
__table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'),联合唯一
# Index('ix_id_name', 'name', 'extra'),联合索引
# 'mysql_engine': 'InnoDB',
# 'mysql_charset': 'utf8'
)
外键设置
# sqlaichemy不像django拥有外键字段,设置外键需要导入ForeignKey指定哪张表的那个字段,作为Column的第二个参数
from sqlalchemy import Column, Integer, ForeignKey
# 字段
hobby_id = Column(Integer, ForeignKey("hobby.id"))
另外如果是多对多的表,他也无法创建第三张表,需要手动创建第三张表关联两张表
一张简单的表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from sqlalchemy.orm import relationship
Base = declarative_base()
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True)
age = Column(Integer, default=18)
email = Column(String(32), unique=True)
ctime = Column(DateTime, default=datetime.datetime.now)
extra = Column(Text, nullable=True)
__table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'),
# Index('ix_id_name', 'name', 'extra'),
)
# 生成这张表
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s8?charset=utf8")
Base.metadata.create_all(engine) # 将继承了Base类的表在engine连接的数据库中生成
# 删除表
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s8?charset=utf8")
Base.metadata.drop_all(engine) # 将继承了Base类的表在engine连接的数据库中删除
一对多关系的设置
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from sqlalchemy.orm import relationship
Base = declarative_base()
class Classes(Base):
__tablename__ = 'classes'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True)
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True)
age = Column(Integer, default=18)
classes = Column(Integer,ForeignKey('classes.id'))
# 与生成表结构无关,仅用于查询方便,指定了关联的表,和反向查询的名字
# 他会根据这个类里与指定表关联的字段去查找
hobby = relationship("Classes", backref='stu')
多对多关系的表设计
class Classes(Base):
__tablename__ = 'classes'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True)
class Teacher(Base):
__tablename__ = 'teacher'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True)
age = Column(Integer, default=19)
# 与生成表结构无关,仅用于查询方便,指定了关联的表,中间表的表名和反向查询的名字
servers = relationship('Classes', secondary='server2group', backref='classes')
class Teacher2Class(Base):
__tablename__ = 'server2group'
id = Column(Integer, primary_key=True)
classes_id = Column(Integer,ForeignKey('classes.id'))
teacher_id = Column(Integer,ForeignKey('teacher.id'))
__table_args__ = (
UniqueConstraint('classes_id', 'teacher_id', name='tea_cls'),
# Index('ix_id_name', 'name', 'extra'),
)
数据操作
ORM通过Session与数据库建立连接的。当应用第一次载入时,我们定义一个Session类(声明create_engine()的同时),这个Session类为新的Session对象提供工厂服务。
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
engine =create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/s8day128db?charset=utf8")
Session = sessionmaker(bind=engine)
创建连接的方式
# 方式一 # 这个定制的Session类会创建绑定到数据库的Session对象。如果需要和数据库建立连接,只需要实例化一个Session: session = Session() # 此处只能够在视图函数内执行 # 执行数据库操作 # 修改操作进行session.commit() session.close() # 方式二:支持线程安全,为每个线程创建一个session session = scoped_session(Session) # 执行数据库操作 # 修改操作进行session.commit() session.remove()
方式二的源码:
class scoped_session(object):
session_factory = None
def __init__(self, session_factory, scopefunc=None):
self.session_factory = session_factory # 原来的Session
if scopefunc:
self.registry = ScopedRegistry(session_factory, scopefunc)
else:
self.registry = ThreadLocalRegistry(session_factory)
def __call__(self, **kw):
if kw:
if self.registry.has():
raise sa_exc.InvalidRequestError(
"Scoped session is already present; "
"no new arguments may be specified.")
else:
sess = self.session_factory(**kw)
self.registry.set(sess)
return sess
else:
return self.registry()
...
class ThreadLocalRegistry(ScopedRegistry):
def __init__(self, createfunc):
self.createfunc = createfunc # 原来的Session
self.registry = threading.local()
def __call__(self):
try:
return self.registry.value
except AttributeError:
val = self.registry.value = self.createfunc()
return val
def instrument(name):
def do(self, *args, **kwargs):
return getattr(self.registry(), name)(*args, **kwargs)
return do # 这里返回的是函数,相当于self.query = do,self.query()相当于do()
for meth in Session.public_methods: # meth就是原Session对象的属性
setattr(scoped_session, meth, instrument(meth))
添加数据
添加一条
clsobj = models.Classes(name='全栈1期') # 实例化类 session.add(clsobj) # 通过session将clsobj添加进数据库中 # 上面并不需要指定库,因为clsobj是Classes的实例,他们存在着对应关系 session.commit() # 提交
添加多条
clsobj = models.Classes(name='全栈2期') stuobj = models.Student(name="李淳罡",classes=1) session.add_all([clsobj,stuobj]) # 也正是因为对应关系的存在,我们可以将不同类的实例一起提交 session.commit()
简单的查询数据
r1 = session.query(models.Classes).all()
print(r1) # [<models.Classes object at 0x0000020B3F849240>, <models.Classes object at 0x0000020B3F8492E8>]
r2 = session.query(models.Classes.name.label('xx'), models.Classes.id).all()
print(r2,type(r2[0])) # [('全栈1期', 1), ('全栈2期', 2)] <class 'sqlalchemy.util._collections.result'>
# 看似元组其实并不是,也可以通过.字段的方式获得值,.label('xx')相当于为这个字段重新齐了名字,相当于sql中的as
r3 = session.query(models.Classes).filter(models.Classes.name == "全栈1期").all()
print(r3) # filter(表达式) [<models.Classes object at 0x0000020B3F849240>]
r4 = session.query(models.Classes).filter_by(name='alex').all()
print(r4) # filter_by(字段=值) []
r5 = session.query(models.Classes).filter_by(name='alex').first()
print(r5) # None
删除
session.query(models.Classes).filter(models.Classes.id>2).delete() # 此处应注意是什么调用的.delete(),all()方法返回的是个列表 session.commit()
修改
session.query(Users).filter(Users.id > 0).update({"name" : "099"})
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "099"}, synchronize_session=False)
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate")
# updata方法传递字典的键可以是字符串类型的字段名,也可以是表下的字段,
# 如果是对原数据进行修改还要指定synchronize_session
更多
# 条件
ret = session.query(Users).filter_by(name='alex').all()
# 多条件,隔开,and关系
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
# between在a,b之间
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
# in_(),接收一个列表
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
# ~取反
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
# 子查询
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
# 查询条件的关系
# and关系
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
# or关系
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
# 组合关系
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()
# 通配符,模糊匹配like()
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()
# 限制 limit
ret = session.query(Users)[1:2]
# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
# 多条件排序是按第一种方式排出现相同时,将相同值按第二种方式排
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组,及聚合函数
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
# 内连接
ret = session.query(Person).join(Favor).all()
# souter=True左连接,他们的连接不用设置关联字段,因为他们之间存在外键关系
ret = session.query(Person).join(Favor, isouter=True).all()
# 无外键关联则需要自己设置关联字段,query什么就能查到什么,不能.别的属性,一般用作关联查询
obj = session.query(models.Student).join(models.Userinfo,models.Student.id==models.Userinfo.user_id).first()
# 组合,将具有相同字段数量的查询结果联合成一个结果
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all() # 去重
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all() # 不去重
# 原生查询,查询结果必须在query中
result = session.query(models.Classes).from_statement(text("SELECT * FROM student where age=:age")).params(age=18).first()
obj = session.query("name","age").from_statement(text('SELECT name,age from teacher')).all()
跨表查询实例
# 找到所有学生,打印学生信息(包含班级名称)
# 子查询
objs = session.query(models.Student).all()
for obj in objs:
cls_obj = session.query(models.Classes).filter(models.Classes.id==obj.classes).first()
print(obj.id,obj.name,obj.classes,cls_obj.name)
# 连表,已有外键关联
objs = session.query(models.Student.id,models.Student.name,models.Classes.name).join(models.Classes,isouter=True).all()
print(objs)
# 还记不记得relationship()
objs = session.query(models.Student).all()
for item in objs:
print(item.id,item.name,item.classes,item.cls.name)
另外relationship()还可以用来添加数据
# 一对多示例 # 向Student增加一条记录,顺便向Classes增加一条记录 session.add(models.Student(name='小韩',cls=models.Classes(name='全栈8期'))) # 向学生表增加一条记录 clsobj = session.query(models.Classes).filter(models.Classes.name == "全栈8期").first() session.add(models.Student(name='崔丝塔娜',cls=clsobj)) # 反向操作 # 创建班级同时创建学生 # 因为是一对多的关系,所以stu应该是一个集合 session.add(models.Classes(name='全栈3期',stu=[models.Student(name='奥利安娜'),models.Student(name='莫甘娜')])) # 多对多 # 创建讲师关联班级,创建班级 obj = models.Teacher(name='奥菲娜') obj.servers = [models.Classes(name='全栈4期'),models.Classes(name='全栈5期')] session.add(obj) # 创建讲师不创建班级 clsobj = session.query(models.Classes).filter(models.Classes.name == "全栈8期").first() session.add(models.Teacher(name='露露',servers=[clsobj])) # 反向添加 session.add(models.Classes(name='全栈9期',classes=[models.Teacher(name='奥瑞利亚'),models.Teacher(name='索拉卡')]))