Pointer network 主要用在解决组合优化类问题(TSP, Convex Hull等等),实际上是Sequence to Sequence learning中encoder RNN和decoder RNN的扩展,主要解决的问题是输出的字典长度不固定问题(输出字典的长度等于输入序列的长度)。
在传统的NLP问题中,采用Sequence to Sequence learning的方式去解决翻译问题,其输出向量的长度往往是字典的长度,而字典长度是事先已经订好了的(比如英语单词字典就定n=8000个单词)。而在组合优化类问题中,比如TSP问题,输入是城市的坐标序列,输出也是城市的坐标序列,而每次求解的TSP问题城市规模n是不固定的。每次decoder的输出实际上是每个城市这次可能被选择的概率向量,其维度为n,和encoder输入的序列向量长度一致。如何解决输出字典维度可变的问题?Pointer network的关键点在如下公式:
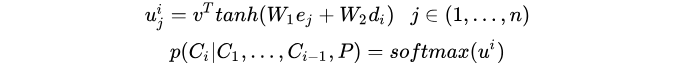
其中  是encoder的在时间序列j次的隐藏层输出,
是encoder的在时间序列j次的隐藏层输出,  是decoder在时间序列i次的隐藏状态输出,这里的
是decoder在时间序列i次的隐藏状态输出,这里的 ![u^i = [u^i_1,u^i_2, ... u^i_j]](https://www.zhihu.com/equation?tex=u%5Ei+%3D+%5Bu%5Ei_1%2Cu%5Ei_2%2C+...+u%5Ei_j%5D) 其维度为n维和输入保持一致,对
其维度为n维和输入保持一致,对  直接求softmax就可以得到输出字典的概率向量,其输出的向量维度和输入保持一致。其中
直接求softmax就可以得到输出字典的概率向量,其输出的向量维度和输入保持一致。其中  均为固定维度的参数,可被训练出来。
均为固定维度的参数,可被训练出来。
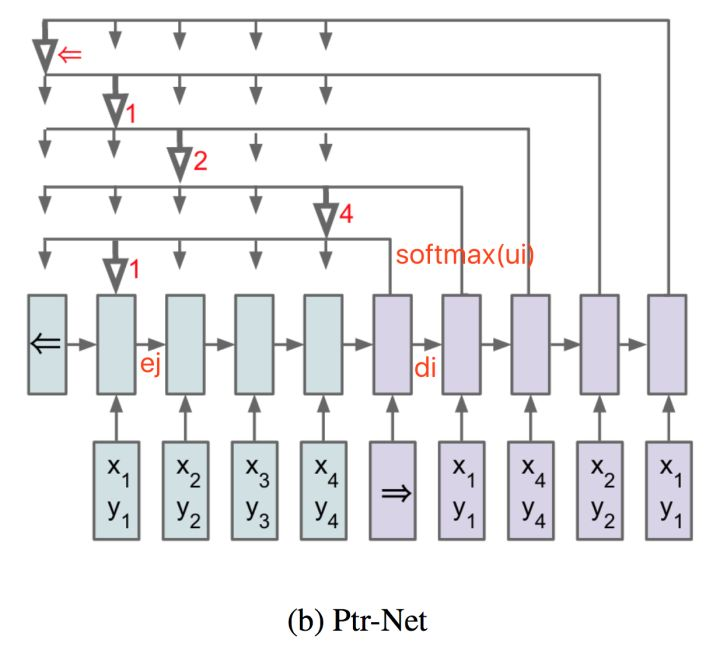
感觉知乎上写的这个解释解释的很不错。所以就搬过来了。链接https://www.zhihu.com/question/59480186
还有另外一个链接也很有意义: https://cloud.tencent.com/developer/news/125169