时间:2016-10-5 14:55
更适合飞翔
我不怕千万人阻挡
只怕自己投降
---------------------------------------
一、表的创建与管理
1、表的基本操作
目标:
理解数据表的概念;
理解常用数据类型;
可以进行数据表对象的创建;
了解表的复制操作;
理解数据字典的概念;
了解表重命名与表截断操作;
理解数据表的删除操作。
表是现实世界的抽象:
数据表市一中“行与列”数据的组合,也是数据库之中最为基本的组成单元,所有的数据操作(增加、修改、删除、查询)以及约束、索引等概念都要依附于数据表而存在,而数据表也可以理解为对现实或者是业务的抽象结果,例如:抽象出现实世界中汽车的抽象模型。

表也可以实现数据的统计:
现在可以做一张数据表,记录下所有获得世界杯冠军的球队。
No 球队 举办国家 年份
1 中国国家足球队 中国 2000年
2 美国国家足球队 美国 2004年
3 韩国国家足球队 韩国 2008年
1.1 Oracle常用数据类型
表中的最基本组成单元是字段,每一个字段都有其数据类型,例如之前所学习的empno字段就是int类型,这些不同的类型就组成了一张表,包括在学习实体技术的时候,JDBC中的ResultSet取数据就是按照类型进行获取的,所以类型是表的实现关键。
数据类型:
CHAR(n):
n=1 to 2000(字节),保存定长的字符串。
VARCHAR(n):
n=1 to 4000(字节),可以放数字、字母以及ASCII码字符集,Oracle12c开始,其最大支持32767字节长度。
NUMBER(m.n):
m=1 to 38,n = -84 to 127,表示数字,其中小数部分长度为m,整数部分长度为m-n。
DATE:
用于存放日期时间类型数据(不包含毫秒)。
TIMESTAMP:
时间戳。
用于存放日期事件类型数据(包含毫秒)。
CLOB:
4GB,用于存放海量文字,例如:保存一部《红楼梦》、《三国演义》。
BLOB:
4GB,用于保存二进制文件,例如:图片、电影。
如果现在要定义表示字符串的数据,一般选用原则,不超过200字,都使用VARCHAR2,例如:学校、姓名。虽然在Oracle中使用的是VARCHAR2,不过在其他数据库中,例如MySQL使用的就是VARCHAR。
对于数值型的数据使用NUMBER,NUMBER有两种分类:
NUMBER(n):表示整数,如果觉得不好记,那么可以使用int替代。
NUMBER(n,m):表示小数,其中m表示小数位,n-m表示整数位,可以使用float替代。
如果想要表示日期时间在Oracle中使用DATE就可以了,不过从习惯上讲,不同的数据库之中DATE方式不同,有些数据库只包含日期,但是不包含时间,而TIME包含了时间,不包含日期,只有TIMESTAMP才能包含日期,时间和毫秒。
如果表示大文本的数据,那么就使用CLOB操作,例如存放一部长篇小说,此类型最多可以保存4GB的文字量大小。
如果保存的是二进制文件,一般使用BLOB,也可以保存4GB的图片、音乐和电影等,但是一般来讲,很少有人直接使用它,因为效率低。
常用类型:VARCHAR2、NUMBER、DATE、CLOB。
1.2 表的创建
表的创建属于DDL(数据定义语言)范畴,严格来讲,每创建的数据表或者是表中的列都属于数据库之中的对象,表对象的创建语法以create table进行定义。
表的创建语法:
create table 用户名.表名称(
字段名称 字段类型 [default] 默认值,
字段名称 字段类型 [default] 默认值,
......
);
对于表名称及列名称的定义要求如下:
必须以字母开头;
长度为1~30个字符;
表名由字母数字下划线#$组成,要见名知意;
对同一个用户不能使用相同的表名称;
不能使Oracle中的保留字,想CREATE、SELECT等都是作为保留字存在的。
用户名又称为模式名称,主要是以当前登陆用户为主。
1.3 创建数据表
create table member(
mid number(5),
name varchar2(50) default '无名氏',
age number(3),
birthday date default sysdate,
note clob
);
此时创建的表中有两个字段的内容设置了默认值,如果想要确定数据表是否存在,那么就可以利用tab查询。
select * from tab;
查看member表的表结构:
desc member;
插入记录:
insert into member(mid, name, age, birthday, note) values(1, '王彦超', 21, to_date('2000-01-01','yyyy-mm-dd'),'哈哈哈哈');
1.4 表的复制
在Oracle中除了可以使用DDL创建新的数据表之外,也支持复制已有的数据表的操作。
表的复制操作也属于表的创建,不过它是根据一个子查询的结果(行和列的集合)创建的新数据表。
语法:
create table 表名称 as 子查询;
将emp表复制位emp2表:
create table emp2 as select * from emp;
以上是复制了一张表的全部内容,但是也可以只复制部分内容。
将10部门的雇员复制到emp3表:
create table emp3 as select * from emp where deptno = 10;
以上都是带有数据的复制,如果说现在要求只将emp表结构复制,而不复制数据,该如何操作?
只能编写一个永远不满足的条件:
create table emp4 as select * from emp where 1 = 2;
除了对实体表的复制外,也可以对查询结果进行复制:
将部门的统计信息保存到department表中:
create table department as select D.deptno, D.dname, D.loc, count(E.empno) count, sum(E.sal + nvl(E.comm,0)) sum, round(avg(E.sal + nvl(E.comm,0)),2) avg, max(E.sal) max, min(E.sal) min from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno, D.dname, D.loc order by D.deptno;
表的复制操作,只要是行与列的查询结果,那么就可以将其定义为数据表。
1.5 数据字典
在Oracle中数据表是可以被重命名的,但是之所以可以改名字,主要还是由Oracle的存储结构决定的。所以在学习修改名字之前,首先了解一下数据字典的概念。
在Oracle中专门提供了一组数据用于提供记录数据库对象信息、对象结构、管理信息、存储信息的数据表,那么这种类型的表就称为数据字典,在Oracle中一共定义了两类数据字典:
这类数据字典由表及视图所组成,这些视图分为三类:
user_*:存储了所有当前用户的对象信息。
all_*:存储所有当前用户可以访问的对象信息(某些对象可能不属于此用户)。
dba_*:存储数据库中所有对象的信息(数据库管理员操作)。
动态数据字典:
随着数据库运行而不断更新的数据表,一般用来保存内存和磁盘状态,而这类数据字典都以“v$”开头。
所有的数据表都属于数据库对象,每当创建一张数据表的时候,会自动在指定的数据字典表执行一条增加语句(隐式),相应的删除会隐式执行delete,而修改会执行update,但是这些数据字典的数据操作只能够通过命令完成,不能使用SQL语句完成。
静态数据字典,要想知道全部的数据表对象,可以使用user_tables这个数据字典:
select * from user_tables;
1.6 修改表名称
在Oracle中,为了方便用户对数据表进行管理,所以专门提供了修改表名称的操作。
语法:
rename 旧表名 to 新表名;
将member修改为wycuser表:
rename member to wycuser;
当发生任何DDL操作时,都会自动提交事务,无法使用rollback回滚操作,所有的DDL操作不受事务的控制。
在更新操作的过程中,如果发生了某些创建表(DDL)的操作,这个时候对于事务而言,是会自动提交的。
1.7 截断表
如果说现在表中的记录都不需要了,可以通过delete来删除表中的全部内容,但是删除时所占用的资源(表空间资源、约束、索引等)都不会立刻释放,所以该操作会执行很长时间,如果想要立刻释放资源,只能够截断表。
语法:
truncate table 表名;
截断wycuser表:
truncate table wycuser;
表一旦被截断之后,所占用的全部资源都将释放,所以无法通过rollback回滚进行恢复。
delete可以通过回滚恢复数据。
1.8 删除表(重要)
表的删除操作是一个非常重要的概念。
如果要删除表,直接使用“DROP TABLE 表名”即可。
drop table wycuser;
select * from wycuser;

select * from tab;

现在表的确是删除了,但是发现删除之后会有“残余”,这是Oracle的闪回技术。
1.9 小结
常用数据类型:NUMBER、VARCHAR2、DATE、CLOB;
数据表的创建属于数据库对象的创建;
创建表的语法:CREATE TABLE ...;
表的复制(创建)属于一种DDL操作,无法使用事务回滚,因为事务会自动提交;
通过表的复制操作,也可以将一个子查询转化为数据表来保存。
2、闪回技术(FlashBack)
目标:
理解闪回技术的主要功能;
掌握闪回命令的使用。
闪回技术是Oracle10g之后所提供的一种新的数据保障措施,在Oracle10g之前,如果用户不小心将表误删,那么就表示表被彻底删除了,只能够通过备份文件进行恢复。但是Oracle10g之后,为了解决这种误删除所带来的数据丢失问题,专门提供了一个与Windows操作系统类似的回收站功能,即:数据表删除的话,会默认先将其保存在“回收站”中,此时如果用户发现删除有错误,则可以直接通过回收站进行表的恢复。
2.1 查看回收站数据
在Oracle10的时候只需要通过如下命令就可以查看回收站:
show recyclebin;
但是从Oracle11g开始,这个命令如果在sqlplus中使用,结果就是闪退。
所以最为安全的做法还是按照SQL语句的方式进行查看操作:
select * from recyclebin;
但是发现查询到的字段太多,所以可以指定常用字段:
select object_name, original_name, operation, type from recyclebin;
2.2 恢复表
如果发现有些表被误删,那么可以进行恢复,而这个恢复过程就是闪回。
flashback table emp2 to before drop;
2.3 彻底删除表
在Windows中回收站提供彻底删除的功能,也就是不进入回收站,而是直接删除全部的数据,在Oracle中也支持此操作。
drop table emp2 purge;
当再次执行flashback table emp2 to before drop;语句时会出现以下错误:

2.4 删除回收站中的数据表
假设当前回收站中有wycuser表:
purge table wycuser;
2.5 清空回收站
purge recyclebin;
以上只是对于表的操作,实际上对于闪回的操作,还可以进行更新数据的恢复。(扫描点)
但是闪回操作是需要空间的,如果Oracle数据库发现空间不足,则会自动抢占闪回空间,最好的做法还是做好数据库的完整备份。
2.6 小结
闪回技术是在Oracle10g新增的功能,是一种防止表被误删的操作手段;
掌握表的彻底删除操作;
掌握清空回收站操作。
3、修改表结构
数据表属于Oracle数据库对象,对于数据库对象,其操作的语法就只有三种:
创建:create 对象类型 名称
删除:drop 对象类型 名称
修改:alter 对象名称 名称
如果可能,尽量不要使用数据表的修改操作,在开发之中需要修改表结构怎么办?
删除表,重新建。
目标:
了解表中列的修改、增加、删除操作;
位表添加注释;
设置可见、不可见字段(Oracle12c)。
3.1 准备操作
为了方便演示数据表的修改操作,下面首先编写如下的数据库创建脚本,并通过此表进行操作:
-- 删除数据表
drop table member purge;
-- 创建数据表
create table member(
mid NUMBER,
name VARCHAR2(50) DEFAULT '无名氏'
);
-- 增加测试数据
insert into member (mid, name) values (1, '张三');
insert into member (mid, name) values (2, '李四');
insert into member (mid, name) values (3, '王月清');
-- 提交事务
commit;
以后在工作中也要编写数据库脚本,组成部分也一样:删除、创建、测试数据、事务提交。
3.2 为表中增加字段
为已有数据表增加字段的时候也像定义数据表一样,需要给出字段名称、类型、默认值,格式如下:
alter table 表名称 add (字段名称 字段类型 default 默认值, ...... );
范例:向member表中增加三个字段
alter table member add (age number(3));
alter table member add (sex varchar2(10) default '男');
alter table member add (photo varchar2(100) default 'nophoto.jpg');
如果增加的时候没有设置默认值,那么所有数据行都是null,如果有设置默认值,那么所有数据行都会变为默认值的内容。
3.3 修改表中的字段
如果发现一张表中的某一列设计不合理的时候,也可以对已有的列进行修改:
alter table 表名称 modify (字段名称 字段类型 default 默认值);
范例:将name字段的长度修改为30,将sex字段的默认值修改为女
alter table member modify(name varchar2(30));
3.4 删除表中的字段
如果现在想要删除表中的一个列,可以通过如下语法完成:
alter table 表名称 drop column 列名称;
范例:删除member标中的photo和age字段
alter table member drop column photo;
3.5 设置无用字段
一定要记住,在进行删除操作的时候,至少保留一个列,如果说某个数据表数据量很大,执行这种删除操作,性能损耗是非常庞大的,所以很多时候为了保证表在大数据量的情况下删除操作可以使用,又不影响表的正常使用,可以将表中列设置为无用的列。
将表中字段设置为无用状态:
alter table 表名称 set unused (列名称);
alter table 表名称 set unused column 列名称;
范例:将sex列和name列设置成无用状态。
alter table member set unused (sex);
alter table member set unused (name);
或者
alter table member set unused column sex;
alter table member set unused column name;
3.6 删除无用列
假设现在sex列和name列都已被设置为无用列,执行删除操作:
alter table member drop unused columns;
修改操作作为SQL的标准语法,了解即可,不需要深入。
4、注释
程序中使用注释可以帮助使用者更加清晰的了解代码的作用,而在Oracle数据库之中也可以为表或列添加注释。
语法:
comment on table 表名称 | column 表名称.列名称 is '注释内容';
4.1 定义数据库创建脚本
-- 删除数据表
4.2 为MEMBER表添加注释
在Oracle中提供了一个“user_tab_comments”数据字典:
select * from user_tab_comments where table_name = 'MEMBER';
此时可以看到里面没有任何信息,查询时需要注意的是表名要大写。
添加注释:
comment on table member is '我是注释';
4.3 为mid列添加注释
除了查看表的注释信息之外,还可以查看列的注释信息,使用“user_col_comments”查看:
select * from user_col_comments where table_name = 'MEMBER';
添加注释:
comment on column member.mid is '我也是注释';
一般在开发中都会提供一个相应的设计文档,文档中一般都会提供解释信息。
5、设置可见、不可见字段
如果某些数据列的内容不需要使用,那么直接为其设置null值数据即可,但是这样一来有可能会出现一个小问题,例如:在一张数据表设计的时候,考虑到日后需要增加若干个列,那么这些列如果提前增加的话,那么就有可能造成开发人员的困扰(不知道这些列是做什么的),为此就希望将这些暂时不使用的列定义为不可见的状态,这样开发人员在浏览数据时,只需要浏览有用的部分即可。当需要这些列时,再恢复其可见状态,在Oracle12c之前,这些特性是不支持的,而从Oracle12c开始为了方便用户进行表管理,提供了不可见列的使用,同时用户也可以将一个可见列修改为不可见的状态。
5.1 创建一张临时数据表
-- 删除数据表
5.2 隐藏字段
如果说name字段是一个暂时不会使用的字段,想将它隐藏,那么现在这种情况,如果直接执行增加操作,必须设置mid和name,观察语法:
insert into mytab values(1);
会出错,因为值与列不匹配。
将name列修改为不可见状态:
alter table mytab modify (name invisible);
查看表结构:
desc mytab;
如果执行:insert into mytab(1);,那么可以成功执行了。
此时name列就不会在表结构上进行显示了,但是在数据字典上“user_tab_columns”中可以查看:
select * from user_tab_columns where table_name = 'MYTAB';
5.6 字段恢复可见状态
将name列变为可见状态:
alter table mytab modify(name visible);
除了在创建表之后修改可见与不可见状态之外,在创建表的时候也可以直接设置:
create table mytab(
mid number,
name varchar2(30) invisible
);
5.7 小结
表创建之后可以使用alter进行修改;
在表建立时可以添加注释信息;
Oracle12c增加了可用、不可用列的设置支持。
6、表管理
表空间的管理属于Oracle中DBA的知识。
目标:
了解表空间的主要作用;
了解表空间的创建及使用。
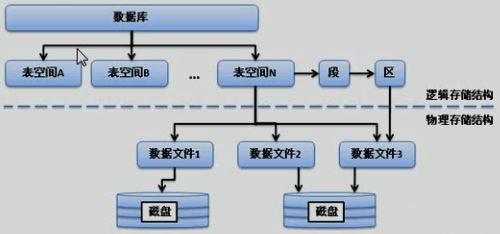
数据库的运行需要依赖于操作系统,而数据库本身也保存在系统的磁盘上,所以当用户向数据表中保存数据时,最终数据也还是保存在了磁盘上,只不过这些数据是按照固定的格式进行保存。
Oracle数据保存在磁盘上的格式如下图所示:
在数据库数据和磁盘数据之间存在了两种结构:
逻辑结构:Oracle中所引入的结构,开发人员所操作的都只针对于Oracle的逻辑结构。
物理结构:操作系统所拥有的存储结构,而逻辑结构到物理结构的转换由Oracle数据库管理系统来完成。
在商业应用中,所有的操作都是以操作系统为前提的,所以数据库一定是安装在操作系统上的。数据库中的数据,也一定是保存在磁盘上的。
在Oracle中,数据库也被称为实例(Instance,图书馆),而数据库中维护的是表空间(书架),那么每张表都要保存在表空间之中(图书)。
表空间是Oracle数据库之中最大的一个逻辑结构,每一个Oracle数据库都会由若干个表空间所组成,而每一个表空间由多个数据文件组成,用户所创建的数据表也统一都被表空间所管理。表空间与磁盘上的数据文件对应,所以直接与物理存储结构有关。而用户在数据库之中所创建的表、索引、视图、子程序等都被表空间保存到了不同的区域内。
在Oracle数据库之中一般有两类表空间:
系统表空间:
是在数据库创建时与数据库一起建立起来的,例如:用户用于撤销的事务处理,或者使用的数据字典就保存在了系统表空间之中,例如Syste或Sysaux表空间。
非系统表空间:
由具备指定管理员权限的数据库用户创建,主要用于保存用户数据、索引等数据库对象,例如:USERS、TEMP、UNDOTBS1等表空间。
6.1 语法
如果要想进行非系统表空间的创建,可以使用如下语法完成:
create [temporary] tablespace 表空间名称
[datafile | tempfile 表空间文件保存路径 ... ] [size 数字[k | m]]
[autoextend on | off] [next 数字 [k | m]]
[logging | nologging];
本程序各个创建子句的相关说明如下所示:
datafile:保存表空间的磁盘路径,可以设置多个保存路径。
tempfile:保存临时表空间的磁盘路径。
size:开辟的空间大小,其单位有K(字节)和M(兆)。
autoextend:是否为自动扩展表空间,如果为ON则表示可以自动扩展表空间大小,反之为OFF。
next:可以定义表空间的增长量。
logging | nologging:是否需要对DML进行日志记录,记录下的日志可以用于数据恢复。(临时表空间不能够使用该命令)
6.2 表空间——范例
创建一个wyc_data的数据表空间:
create tablespace wyc_data datafile 'D:wycwyc_data01.dbf' size 50M, 'E:wycwyc_data02.dbf' size 50M autoextend on next 2M logging;
当使用SCOTT用户执行该命令时,会提示权限不足:
对于表空间应该由管理员进行创建,所以应该使用SYS用户登陆。
使用SYS执行该命令时,会出现创建文件错误的提示:
因为目录不存在,首先要创建好文件夹。
6.3 表空间——范例
创建一个wyc_temp的临时表空间:
create temporary tablespace wyc_temp tempfile 'D:wycwyc_temp01.dbf' size 50M, 'E:wycwyc_temp02.dbf' size 50M autoextend on next 2M;
需要注意的是临时表空间不能够添加日志。
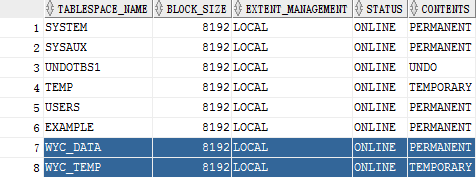
这个时候一共创建了两个表空间(数据表空间和临时表空间),同时这两个表空间保存在了不同的磁盘上。创建完之后的表空间,一定会在数据字典之中进行相关内容的记录。(CREATE开头的都是创建对象)
如果要想查看表空间(管理员权限),那么就可以使用dba_tablespace数据字典查看:
select * from dba_tablespaces;
select tablespace_name, block_size, extent_management, status, contents from dba_tablespaces;
6.4 Oracle中的默认表空间
在Oracle数据库中默认提供了以下几个表空间,各个表空间的作用如下所示:
SYSTEM表空间:
在一个数据库中至少有一个表空间,即SYSTEM表空间。创建数据库时必须指明表空间的数据文件的特征,即数据库文件名称、大小。SYSTEM主要是存储数据库的数据字典,在Oracle系统表空间中存储全部PL/SQL程序的源代码和编译后的代码,例如存储过程、函数、包、数据库触发器。如果要大量使用PL/SQL,就应该设置足够大的SYSTEM表空间。
SYSAUX表空间:
是SYSTEM表空间的辅助表空间,许多数据库的工具和可选组件将其对象存储在SYSAUX表空间内,它是许多数据库工具和可选组件的默认表空间。
USERS表空间:
用于存储用户的数据。
UNDO表空间(UNDOTBS1表空间):
用于事务的回滚、撤销。
TEMP临时表空间:
用于存放Oracle运行中需要临时存放的数据,如排序的中间结果等。
6.5 查看数据的表空间数据字典
发现使用dba_tablespaces数据字典只能够查看数据库表空间的信息,并不能够查看每个表空间所花费的存储信息,而且这两类表空间(数据表空间和临时表空间)使用的数据字典是不同的,可以使用dba_data_files和dba_temp_files两个数据字典进行查看:
select * from dba_data_files;
select * from dba_temp_files;
6.6 使用表空间
表空间的使用主要是在创建数据表的时候使用。
创建数据表并使用特定表空间:
create table 用户名.表名称(
字段名 字段类型,
......
) tablespace 表空间名称;
创建一张表,让其使用wyc_data表空间:
create table table1(
id int
) tablespace wyc_data;
6.7 小结
数据表受到表空间的管理;
表空间分为两类:数据表空间、临时表空间。
二、完整性约束
1、数据库完整性约束简介
目标:
理解数据库完整性约束的作用
理解数据库中的各约束的作用
完整性约束是保证用户对数据库所做的修改不会破坏数据的一致性,是保护数据正确性和相容性的一种手段。
例如:
如果用户输入年龄,则年龄肯定不能是999;
如果用户输入性别,则只能设置“男”或“女”。
1.1 维护完整性
在一个DBMS之中,为了能够维护数据库的完整性,必须能够提供以下的几种支持:
提供定义完整性约束条件机制:
在数据表上定义规则,这些规则是数据库中的数据必须满足的语义约束条件。
提供完整性检查的方法:
在更新数据库时检查更新数据是否满足完整性约束条件。
违约处理:
DBMS发现数据违反了完整性约束条件后采取的违约处理行为,如拒绝(NO ACTION)执行该操作,或者级联(CASCADE)执行其他操作。
1.2 主要约束分类
在开发之中可以使用以下的五种约束进行定义:
非空约束:如果使用了非空约束的话,则以后此字段的内容不允许设置为null值。
唯一约束:此列的内容不允许出现重复。
主键约束:表示一个唯一的标识,例如:人员ID不能重复,且该字段不允许为null。
检查约束:用户自行编写设置内容的检查条件。
主——外检约束(参照完整性约束):是在两张表上进行的关联约束,加入关联约束之后就产生父子关系。
数据库本身留给用户设置的有五种约束,但是严格来讲,还有一种隐式约束,例如:数据类型。假设年龄字段的类型是NUMBER,那么肯定不能设置为字符串。
1.3 小结
理解五种约束的作用。
2、非空约束
目标:
掌握非空约束的主要定义操作。
在正常情况下,null是每个属性的合法数据值,如果说现在某个字段不嫩为null,且必须存在数据,那么就可以依靠非空约束来进行控制,这样在数据更新时,此字段的内容出现null时就会产生错误。
2.1 非空约束——范例
定义member表,其中姓名不允许为空:
create table member ( mid int, name varchar2(20) not null);
如果要设置非空约束,只需要在定义列的时候后面增加一个not null即可。
向member表中增加正确数据:
insert into member(mid, name) values (1, '王彦超');
正确数据可以正常保存。
向member表中增加错误数据:
insert into member(mid, name) values (2, null);
insert into member(mid) values (3);
此时出现了一个错误:
此时可以发现错误信息由“用户名”、“表名称”、“字段名称”三个部分组成,也就是说这个错误的信息已经准确的告诉了用户哪里有问题,非空约束带来的信息是非常完整的。
2.2 小结
非空约束不允许字段为null值。
非空约束出现错误时会提示完整的错误信息。
3、唯一约束
目标:
掌握唯一约束的特点及定义;
掌握constraint子句的使用。
唯一约束(UNIQUE,简称UK)表示的是在表中的数据不允许出现重复的情况,例如:每一位成员肯定都有自己的Email,而这个Email肯定是不能重复的。
SQL脚本:
drop table member purge;
create table member(
mid number,
name varchar2(20) not null,
email varchar2(50) unique
);
commit;
当表创建完成后,可以进行数据的增加操作。
向member表中增加正确的数据:
insert into member(mid, name, email) values (1, '王彦超', '123@qq.com');



向member表中增加错误的数据:EMAIL字段数据的重复
insert into member(mid, name, email) values (1, '张三', '123@qq.com');
可以发现程序出现了错误:“ORA-00001:违反唯一约束条件(SCOTT.SYS_C0011283)”:

发现此时的错误信息与之前的非空约束的错误信息相比较,完全看不懂,因为约束在数据库之中也是一个对象,所以为了方便维护,那么每一个约束都一定有自己的名字,如果用户没有指定名字,那么就由系统动态地分配一个名称。
所以这个时候可以使用CONSTRAINT关键字来为约束定义名字,对于约束的名字,建议写:“约束简写_字段”或者“约束简写_表_字段”,那么唯一约束的简写应该为UK,而且唯一约束使用在了Email中,所以约束名称最好为:UK_EMAIL,所以定义约束时格式应该改为:
create table member(
......
email varchar2(50),
constraint uk_email unique(email)
);
此时的错误信息就非常的明显了:
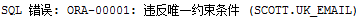
需要注意的是,唯一约束本身是不受null类型控制的,比如说email暂时没有,可以为null,可能是实际中出现的情况。
3.1 小结
唯一约束可以设置null。
唯一约束的列不允许重复。
4、主键约束
目标:
掌握主键约束的作用;
了解复合主键的定义。
如果一个字段既要求唯一,又不能设置为null,则可以使用主键约束(主键约束 = 非空约束 + 唯一约束),主键约束使用PRIMARY KEY(简称PK)进行指定,例如:在member表中的mid字段应该表示一个成员的唯一编号,而这个编号既不能为空,也不能重复。
SQL脚本:
drop table member purge;
4.1 为mid设置null值
insert into member(mid, name, email) values (null, '张三', '123@qq.com');
如果此时设置了null,那么错误信息为:

此时可以发现,触发的是非空约束的错误提示。
4.2 为mid设置重复值
insert into member(mid, name, email) values (1, '张三', '123@qq.com');
insert into member(mid, name, email) values (1, '李四', '1234@qq.com');
错误信息如下:

此时可以发现,触发的是唯一约束的错误提示。
主键约束错误 = 非空约束错误 + 唯一约束错误。
4.3 指定主键约束名
如果没有为主键约束设置名字的话,那么也会由系统自动分配一个动态名称。
可以手动指定主键约束名称:
constraint pk_mid primary key(mid);
此时如果再次出现错误信息:

在以后的开发之中,只要是实体表数据,几乎都要有一个主键,而一些关系表有可能是不需要主键的。
4.4 复合主键
在实际的开发之中,一般在一张表中会设置一个主键,但是也允许为一张表设置多个主键,这个时候将其称为复合主键。在复合主键中,只有两个主键字段的内容完全一样,才会发生违反约束的错误。
脚本:
drop table member purge;
create table member(
mid number,
name varchar2(200) not null,
email varchar2(50),
constraint pk_mid_name primary key (mid, name),
constraint uk_email unique (email)
);
commit;
复合主键只是呈现了一种语法,但是尽量不要使用。
4.5 小结
主键约束 = 非空约束 + 唯一约束;
复合主键约束一般不建议使用。
6、检查约束
目标:
掌握检查约束的操作。
检查约束指的是对数据增加的条件过滤,表中的每行数据都必须满足指定的过滤条件,在进行数据更新操作时,如果满足检查约束所设置的条件,数据可以成功更新,如果不满足,则不能更新,在SQL语句中使用check(简称CK)设置检查约束的条件。
6.1 检查约束——范例
在member表中增加age字段(年龄范围是0~200)和sex字段(只能是男或女)。
drop table member purge;
增加正确的数据:
insert into member (mid, name, email, age, sex) values (1, '王彦超', '123@qq.com', 21, '男');
增加错误的数据:
年龄错误:insert into member (mid, name, email, age, sex) values (2, '张三', '1234@qq.com', 2000, '男');
此时age并没有设置约束名称,所以此处依然由系统自动分配约束名称。
性别错误:insert into member (mid, name, email, age, sex) values (2, '张三', '1234@qq.com', 20, '无');
会出现完整的错误信息。
思考:关于性能的问题?
对于任何一种操作,如果增加的约束越多,那么一定会影响更新的性能,如果一张数据表会被频繁修改的话,那么检查约束不建议使用。
所以这样的验证操作一般都会由程序在服务器端完成,例如:Struts中的各种验证。
通过程序来完成验证,可以缓解数据库的压力。
6.2 小结
检查约束会设置多个过滤条件,所以检查约束过多时会影响数据更新性能,能不用,就不用。
7、外键约束
目标:
掌握外检约束的作用及设置;
掌握数据的级联操作。
7.1 外检约束的产生分析
例如,现在公司要求每一位成员为公司发展提出一些更好的建议,并且希望将这些建议保存在数据表之中,那么根据这样的需求,可以设计出如图所示的设计模型。

设计出了两张数据表,两张表的作用如下:
人员表:用于保存成员的基本信息(编号、姓名)
建议表:保存每一个成员提出的建议内容,所以在此表之中保存了一个成员编号字段,即:通过此成员编号就可以和成员表进行数据关联。
现在一个成员可以提出多个建议,这就是一个明显的一对多的关系,也就类似于之前所学习过的dept - emp关系。
7.2 创建脚本
drop table member purge;
7.3 增加正确的数据:
insert into member (mid, name) values (1, '张三');
此时mid = 1的成员提出了两个意见,然后mid = 2的成员提出了三个意见,这些数据都应该算是有效数据。
7.4 查询出每位成员的完整信息以及所提出的意见数量
select N.mid, name, count(A.mid) over(partition by A.mid) from member N,advice A where N.mid = A.mid;
确定所需要的数据表:
member表:成员编号、姓名
advice表:每个成员提出的建议数量(统计信息)。
以上是人为控制的理想情况,如果说增加了以下的错误信息呢?
insert into advice (adid, content, mid) values (6, '第六条信息', 99);
现在最关键的问题在于,在member表中并不存在mid = 99的信息。
如果按照之前所学习的知识来讲,这种错误的数据无法回避。那么现在可以分析一下关于数据的参考方式
现在对于表可以分为父表(member)和子表(advice),因为子表之中的数据必须参考member表中的数据,建议的提出者的成员编号应该在member表中mid已存在的数据。
所以在这样的情况下,为了保证表中数据有效性,就只能够利用外键约束(FOREIGN KEY)来完成。
7.5 增加外键
create table advice(
adid number,
content clob not null,
constraint pk_adid primary key (adid),
constraint fk_mid froeign key(mid) references member(mid)
);
此时如果再插入mid为99的信息,会出现以下错误:
SQL错误:ORA-02291:违反完整约束条件(SCOTT.FK_MID) - 未找到父项关键字
7.6 问题
一旦为表中增加了外键约束,那么就会有新的问题。
问题一:删记录
如果想要删除父表数据,那么首先要删除对应的所有子表数据。
当父表存在数据,但是删除子表数据时,会出现以下错误信息:
SQL错误:ORA - 02292:违反完整约束条件(SCOTT.FK_MID) - 已找到子记录
如果现在一定要删除父表记录,那么首先要删除子表记录,但是这样做太麻烦了,所以就提出了数据的级联操作问题。
问题二:删表
删除父表的时候需要先删除子表。
如果直接删除父表,则会出现错误信息,提示先删除对应子表。
说明:
在进行外键设置的时候,对应的字段,在表中必须是主键或者是唯一约束。
问题三:
创建表的时候将A表作为B表的父表,然后又通过修改,将B表作为了A表的父表,相当于这两个表互为外键表,此时是无法通过delete进行删除操作的。
这种混乱的情况可以选择强执行删除:
drop table member cascade constraint;
这种强制删除虽然干净快捷,但是并不建议使用,主要的原因是在编写数据库脚本的时候一定要考虑好先后的关系。
7.7 级联删除
on delete cascade;
当主表数据被删除之后,对应的子表数据也会被清理。
create table advice(
adid number,
content clob not null,
mid number,
constraint pk_adid primary key(adid),
constraint fk_mid forein key (mid) references member(mid) on delete cascade
);
只需要在外键约束后加上on delete cascade即可。
此时如果执行delete from member where mid = 1;,则子表中对应的数据也会删除。
7.8 级联更新
on delete set null;
当主表数据被删除后,对应的子表数据的相应字段的内容会设置为null。
create table advice(
adid number,
content clob not null,
mid number,
constraint pk_adid primary key(adid),
constraint fk_mid forein key (mid) references member(mid) on delete set null
);
以上的级联操作选择还是看需求,例如学生和成绩肯定是级联删除。
7.9 小结
级联操作:on delete cascade、on delete set null
使用外键约束后删除表时应该先删除子表再删除父表。
8、查看约束
目标:
了解约束信息数据字典的作用。
约束是由数据库自己创建的对象,所有的对象都会保存在数据字典中,因为约束是用户创建的,所以可以用“user_constraints”数据字典或者是“user_cons_columns”数据字典查看
脚本:
create table member(
插入数据:
insert into member (mid, name) values(1, '张三');
insert into member (mid, name) values(1, '李四');

查看数据库约束:
select * from user_constraints;
其中的CONSTRAINT_TYPE就表示了约束类型:

P代表主键。
但是现在只是知道了约束名称,而不知道字段是哪一个,可以通过user_cons_columns查询:
select * from user_cons_columns;
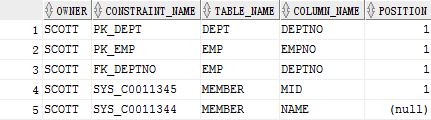
通过这两个数据字典就可以清楚的知道约束对象在所对应的内容。
但是一般而言,如果按照标准的开发模式,按照“约束简写_字段”实际上就足够解决这些约束名称的问题了,从开发角度来讲,约束的名称一定要有。
8.1 小结
约束依然属于数据库对象,可以直接利用数据字典查看。
9、修改约束
在之前学过,表尽量不要去修改,那么对于约束来说也一样,约束跟表一起建立,那么建立之后尽量不要修改了。
9.1 增加约束
如果一张表创建的时候没有设置任何的约束,那么就可以通过指定的语实现约束的增加。
定义一张没有约束的表:
create table member (
mid number,
name varchar2(20),
age number
);
或者直接查看“user_constraints”数据字典查看member表是否有约束:
select * from user_constraints where table_name = 'MEMBER';
9.2 语法
alter table 表名称 add constraint 约束名称 约束类型(约束字段);
范例:为member表中的mid增加主键约束。
alter table member add constraint pk_mid primary key(mid);
范例:为member表的age字段增加检查约束。
alter table member add constraint ck_check(age between 0 and 200);
但有一点需要说明的是,在进行后期约束添加的时候,非空约束不能够使用此类语法。
非空约束只能够使用修改表猎狗的方式完成:
alter table member modify (name varchar2(20) not null);
当表中数据指定列存在null值时,无法添加非空约束:

所以如果想要添加非空约束,必须保证数据表本身不存在违反约束的数据。
对于非空约束,在设计表的时候就要添加。
8.3 禁用约束
大部分情况下一张表一定会定义多种约束,但是约束过多一定会影响到性能,所以当需要大批量数据更新时,就希望暂时停用约束。
禁用约束:
alter table 表名称 disable constraint 约束名称 [cascade];
范例:
禁用advice表中的adid主键约束“pk_adid”
alter table advice disable constraint pk_adid
此时advice表中就不存在主键了,于是再增加错误数据会成功插入。
此时禁用的是子表(advice)主键,那么如果禁用主表(member)主键呢?
范例:
禁用member中的主键
alter table member disable constraint pk_mid;
此时会出现一个错误信息:
SQL 错误:ORA-02297:无法禁用约束条件 (SCOTT.PK_MID) - 存在相关性。
因为对应的子表存在记录。
在禁用语法中给出了cascade操作,所以可以使用它解决问题:
alter table member disable constraint pk_mid cascade;
cascade只有在外键中才会使用。
8.4 启用约束
alter table 表名称 enable constraint 约束名称
范例:
启用两张表的约束。
alter table member enable constraint pk_mid;
alter table advice enable constraint pk_adid;
如果表中存在于主键约束相冲突的数据,会发现执行错误,因为如果想要保证约束可以正常启用,那么必须先解决表中冲突数据的问题。
8.5 删除约束
约束属于数据库对象,所以对象也可以进行删除操作,删除约束的关键是约束名称。
语法:
alter table 表名称 drop constraint 约束名称 [cascade];
范例:
删除advice表中的“pk_adid”约束——无外键关联。
alter table advice drop constraint pk_adid;
范例:
删除member表中的“pk_mid”约束——有外键关联。
alter table member drop constraint pk_mid cascade;
主键要想删除,必须设置级联。
约束一定要和表一起建立,最低的限度也应该在数据库正式使用前建立好完善的约束条件。
8.6 小结
约束在建立表的时候一定要同时修改;
对于约束不建议对其进行修改。
9、数据库综合实战
所需要的知识点:
DML(更新、查询)
事务
DDL(表、约束)
9.1 建立数据表
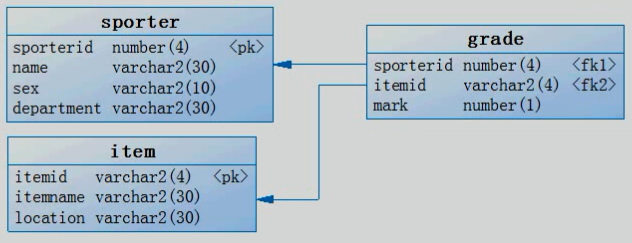
到了秋天,为了让同学们增加体育锻炼,所以学校开始筹备学生运动会的活动,为了方便保存比赛成绩信息,所以定义了如下的几张数据表。
运动员表sporter:
运动员编号sporterid、运动员姓名name、运动员性别sex、所属系部department
项目表item:
项目编号itemid、项目名称itemname、项目比赛地点location
成绩表:
sporterid、项目编号itemid、积分mark