实验要求:
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
-
以fork和execve系统调用为例分析中断上下文的切换
-
分析execve系统调用中断上下文的特殊之处
-
分析fork子进程启动执行时进程上下文的特殊之处
-
以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
一.fork系统调用过程:
1.除了0号进程(系统创建的)之外,linux系统中都是由其他进程创建的。创建新进程的进程,即调用fork函数的进程为父进程,新建的进程为子进程。
fork创建进程分为三种情况:
1)对于父进程,fork函数返回新建子进程的pid;
2)对于子进程,fork函数返回 0;
3)如果出错, fork 函数返回 -1.
PID进程的结构体部分:
struct task_struct{
pid_t pid; //进程id
uid_t uid,euid;
gid_t gid,egid;
volatile long state; //进程状态,0 running(运行/就绪);1/2 均等待态,分别响应/不响应异步信号;4 僵尸态,Linux特有,为生命周期已终止,但PCB未释放;8 暂停态,可被恢复
int exit_state; //退出的状态
unsigned int rt_priority; //调度优先级
unsigned int policy; //调度策略
struct list_head tasks;
struct task_struct *real_parent;
struct task_struct *parent;
struct list_head children,sibling;
struct fs_struct *fs; //进程与文件系统管理,进程工作的目录与根目录
struct files_struct *files; //进程对所有打开文件的组织,存储指向文件的句柄们
struct mm_struct *mm; //内存管理组织,存储了进程在用户空间不同的地址空间,可能存的数据,可能代码段
struct signal_struct *signal; //进程间通信机制--信号
struct sighand_struct *sighand; //指向进程
cputime_t utime, stime; //进程在用户态、内核态下所经历的节拍数
struct timespec start_time; //进程创建时间
struct timespec real_start_time; //包括睡眠时间的创建时间
}
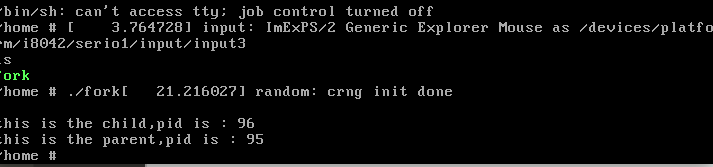
2.运行一个案例:
include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
pid_t pid ;
pid = fork();
if(pid < 0)
{
printf("fail to fork
");
exit(1);
}
if(pid == 0)
{
printf("this is the child,pid is : %u
",getpid());
exit(0);
}
if(pid > 0)
{
printf("this is the parent,pid is : %u
",getpid());
exit(0);
}
return 0;
}

3.查看do_fork的代码:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
整段代码涉及到很多工作的处理,但是整个创建新进程是在上述代码中的copy_process()这个函数实现的。copy_process()函数复制父进程、获得pid、调用wake_up_new_task将子进程加入就绪队列等待调度执行等。在Linux中,除了0号进程由手工创建外,其他进程都是通过复制已有进程创建而来,而这正是fork的主要工作,具体的任务交由copy_process完成。
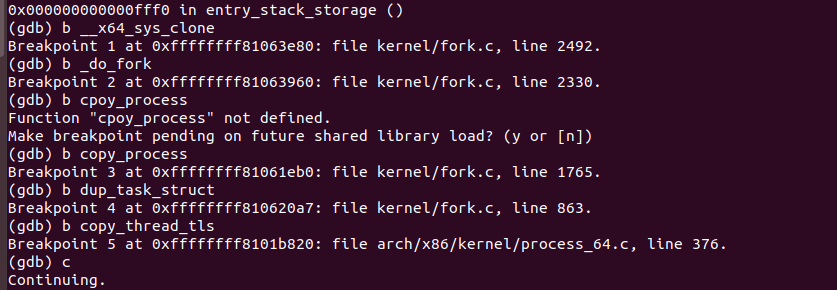
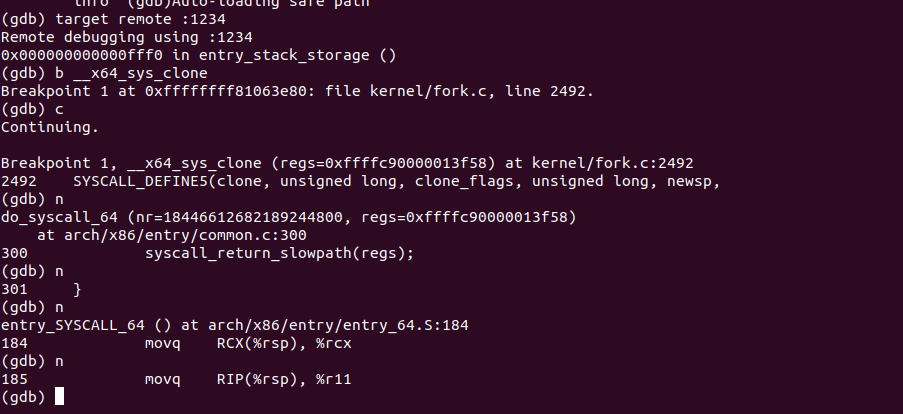
copy_process()的执行逻辑为:
1)调用 dup_task_struct 复制当前进程的task_struct;
2)将新进程相关的数据结构和进程状态初始化;
3)复制父进程信息;
4)调用 copy_thread_tls 初始化子进程内核栈;
5)设置子进程pid;
6)建立亲属关系链接,并将新进程插入全局进程队列 copy_thread_tls: 拷贝父进程系统堆栈内容;
7)执行childregs->ax = 0语句,该代码将子进程的 eax 赋值为0,do_fork返回后会从eax读取返回值,所以为0;
8)执行p->thread.eip = (unsigned long) ret_from_fork;将子进程的 eip 设置为 ret_form_fork 的首地址,因此子进程是从 ret_from_fork 开始执行的。
4.gdb分析:
二.execve系统调用:
什么是execve:进程创建的过程中,子进程先按照父进程复制出来,然后与父进程分离,单独执行一个可执行程序。这要用到系统调用execve。在调⽤execve系统调⽤时,当前的执⾏环境是从⽗进程复制过来的,execve系统调⽤加载完新的可执⾏程序之后已经覆盖了原来⽗进程的上下⽂环境。 execve在内核中帮我们重新布局了新的⽤户态执⾏环境即初始化了进程的用户态堆栈,execve系统调用对应的内核处理函数为sys_execve或者__x64_sys_execve,他们都是通过do_execve来完成具体的加载可执行文件的工作
整体的调⽤的递进关系为:
- sys_execve()或__x64_sys_execve -> // 内核处理函数
- do_execve() –> // 系统调用函数
- do_execveat_common() -> // 系统调用函数
- __do_execve_file ->
- exec_binprm()-> // 根据读入文件头部,寻找该文件的处理函数
- search_binary_handler() ->
- load_elf_binary() -> // 加载elf文件到内存中
- start_thread() // 开始新进程
对比fork、execve和普通的系统调用:
系统调用可以视为一种特殊的中断,老的32位linux就是采用int 0x80中断指令进入内核,因此自然涉及中断上下文,也就是切换到用户内核栈,同时保存相关的寄存器使得中断结束后能够正常返回。当执行系统调用时,用户内核栈的结构如下:

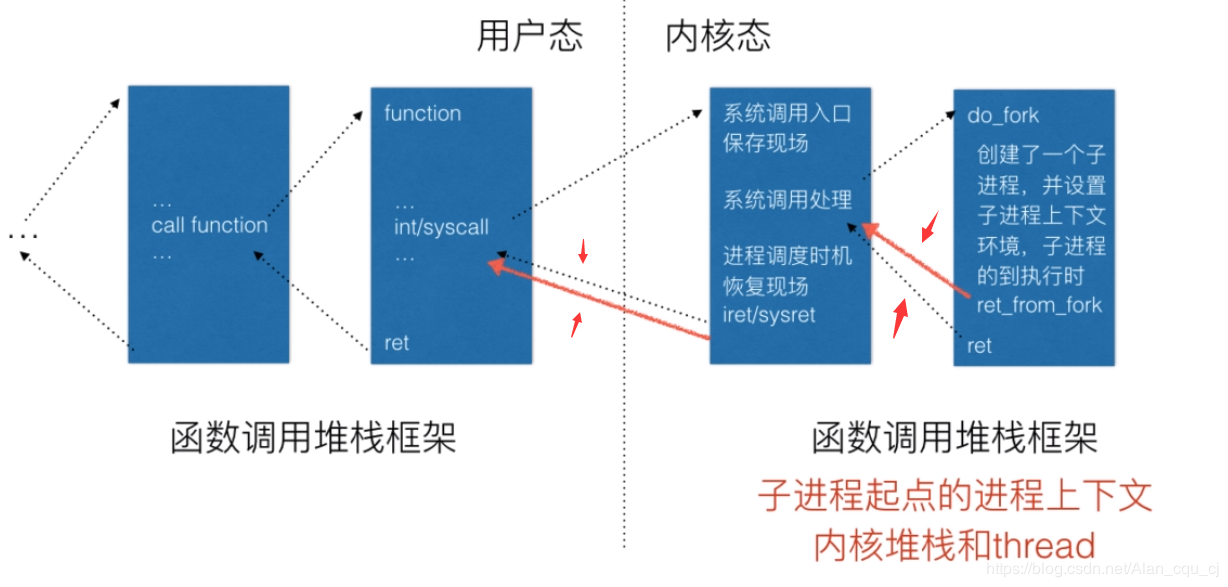
而fork系统调用特殊之处在于他创建了一个新的进程,且有两次返回。对于fork的父进程来说,fork系统调用和普通的系统调用并无两样。但是对fork子进程来说,需要设置子进程的进程上下文环境,这样子进程才能从fork系统调用后返回。
而对于execve而言,由于execve使得新加载可执⾏程序已经覆盖了原来⽗进程的上下⽂环境,而原来的中断上下文就是保存的是原来的、被覆盖的进程的上下文,因此需要修改原来的中断上下文,使得系统调用返回后能够指向现在加载的这个可执行程序的入口,比如main函数的地址(静态链接下)。
三.Linux系统的一般执行过程(含中断与进程切换)
一般函数调用框架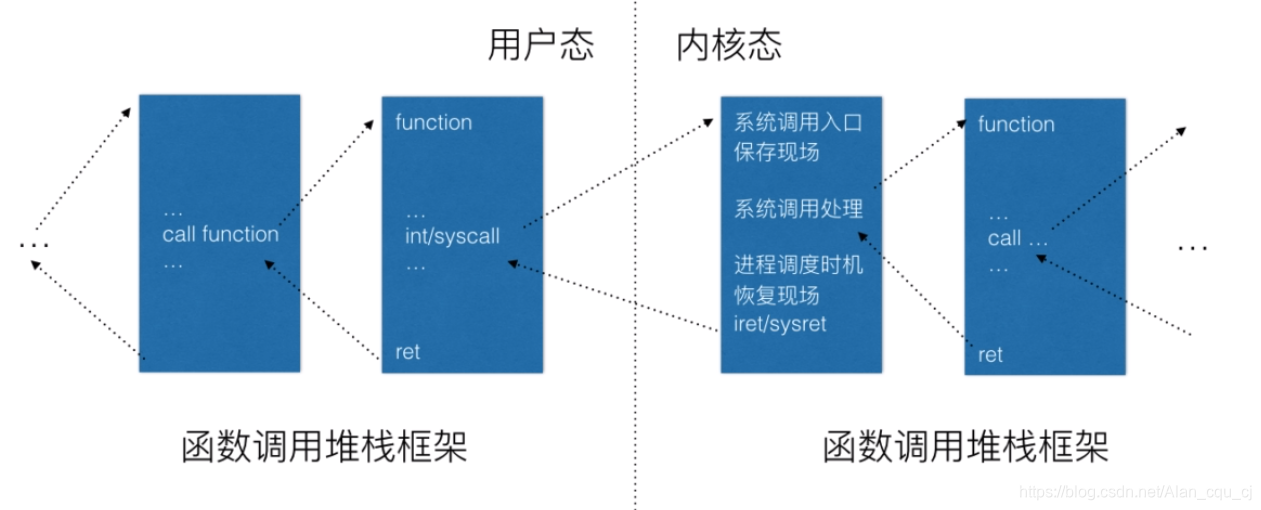
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下⽂切换,具体包括如下⼏点:
- swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
- rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现⽤户堆栈和内核堆栈的切换。
- save cs:rip/ss:rsp/rflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现的。
此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5)switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X 切换到进程Y了。
(7)为了对应起⻅,中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7)iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完 成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运⾏⽤户态进程Y。