无监督-无标签
聚类,难点在于评估和调参。
k-means最简单实用
基本概念

K值:数据聚成多少类。
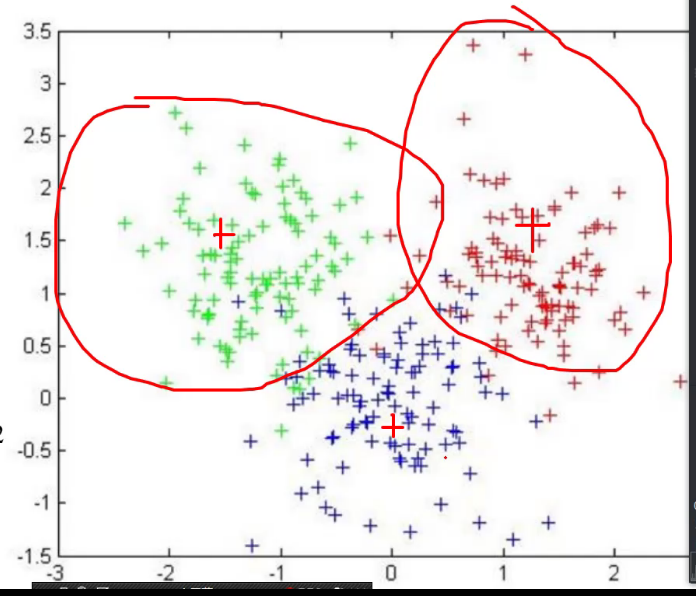
质心:各个维度算平均数。Centroid
相似度量:距离来算(欧式距离——直线距离,余弦距离)
样本之间的距离要先做标准化。(例如先都画到0-1之间)
优化,样本离质心间距离求和。(Ci是质心,x是样本)。越小越好,距离越小越相似,希望数据点到各自质心的距离越小越好(聚类)。
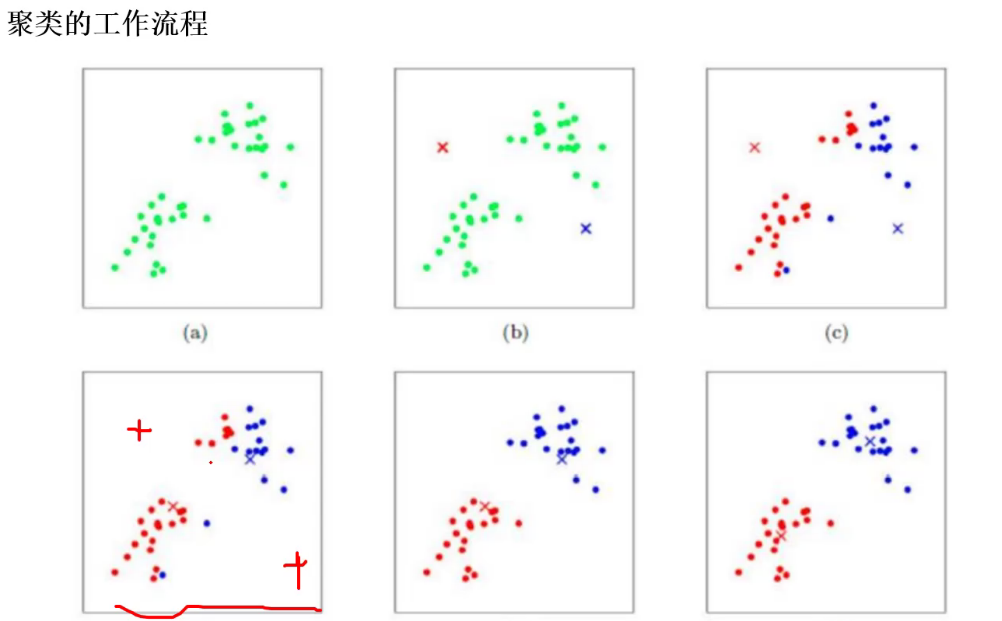
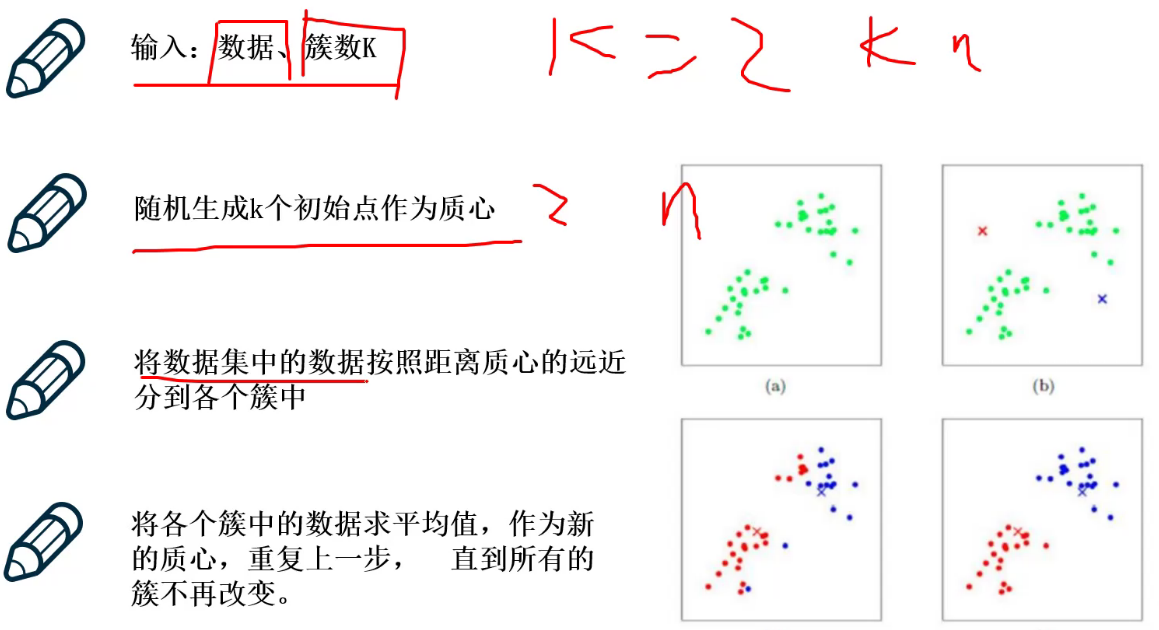
工作流程
1、随机初始化
要聚成两类则随机初始化两个质心,
遍历所有的点,算两个质心距离;哪个离得近,分类
更新质心:红色算平均

还有基于密度聚类
dbscan
网页演示:
Visualizing K-Means Clustering https://www.naftaliharris.com/blog/visualizing-k-means-clustering/

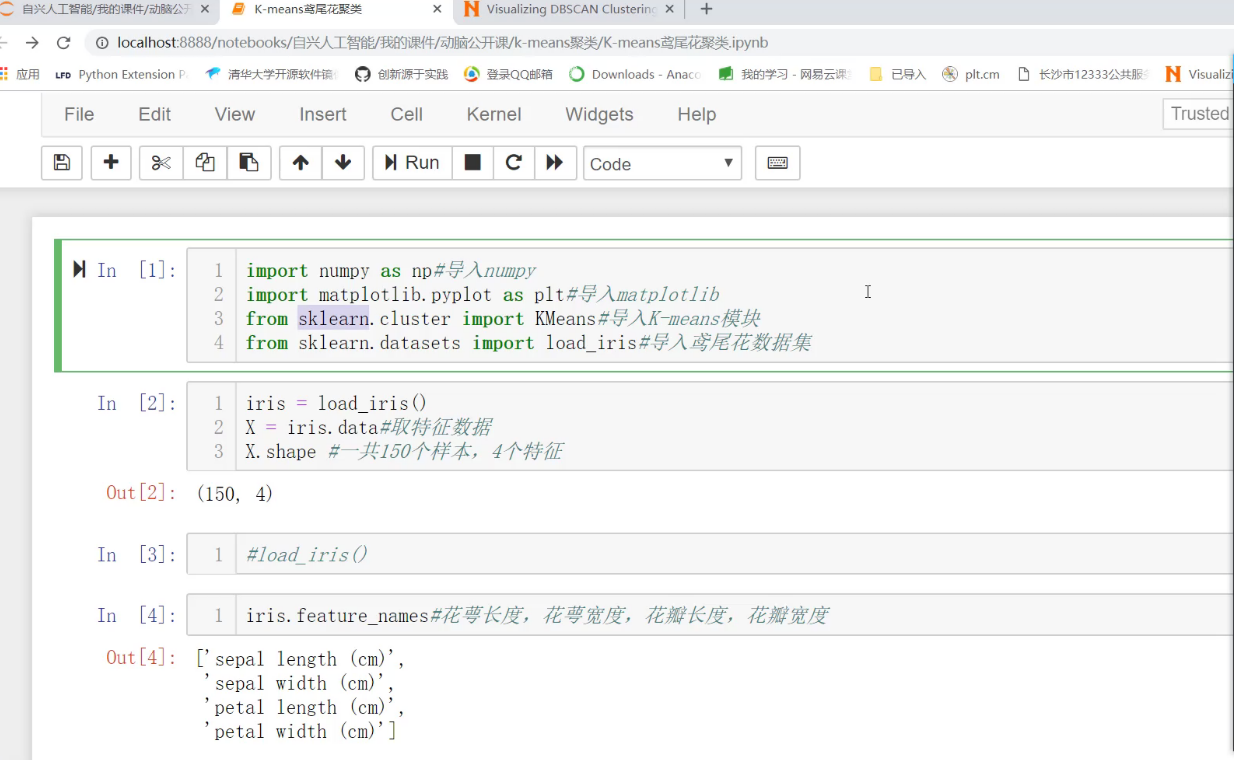
numpy矩阵运算的
matplotlib数据可视化
sklearn已经
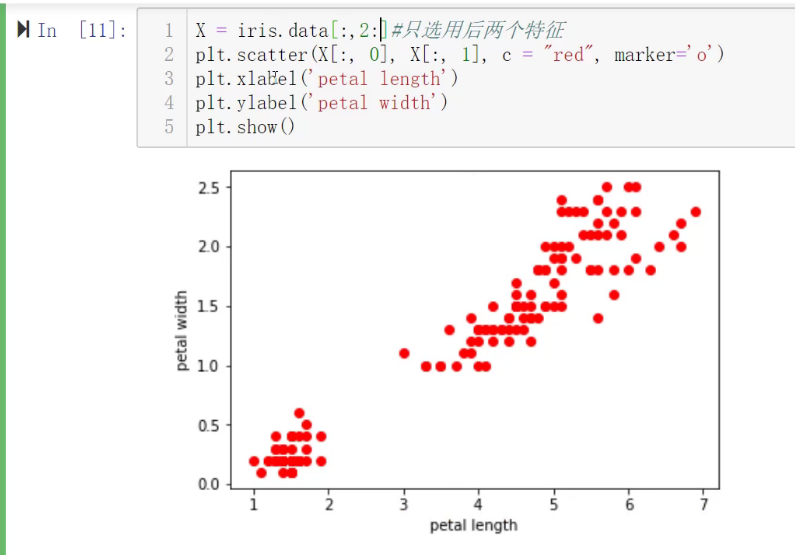
对花的数据聚类,一行一个样本。一列是一个特征。
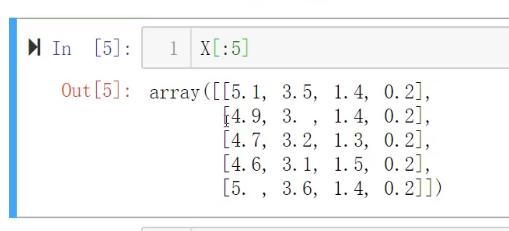
画出来

数据差别不大,可以不做标准化。
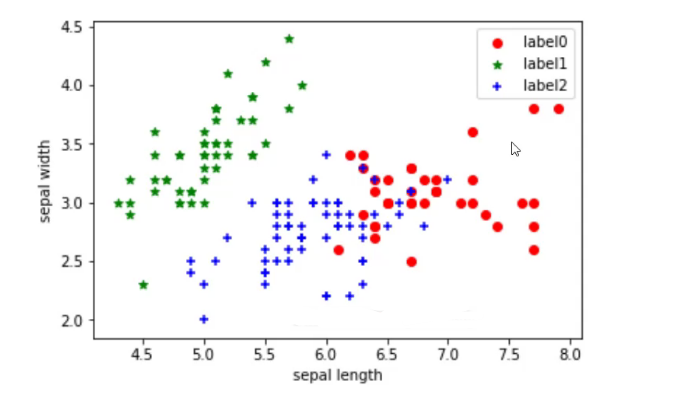
利用sklearn里的k-means建模
- 实例化KM_model。
- .fit,使用所有特征,四个特征。.fit训练
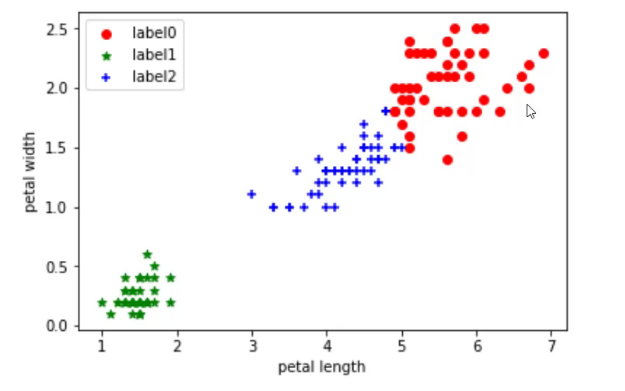
- 查看聚类结果labels。

聚类评估:轮廓系数(Silhouette Coefficient)
ai同簇,越小越好。
bi到其他簇,取最小。越大越好,不同的差异大。

算平均轮廓系数


使用全部4个特征,发现聚类效果并不理想
现在,只使用后面两个特征进行聚类
花瓣长度和花瓣宽度