语言&环境
语言:继续用Python开路!

![]()

![]()

![]()

![]()
一个迷你框架
下面以比较典型的通用爬虫为例,分析其工程要点,设计并实现一个迷你框架。架构图如下:
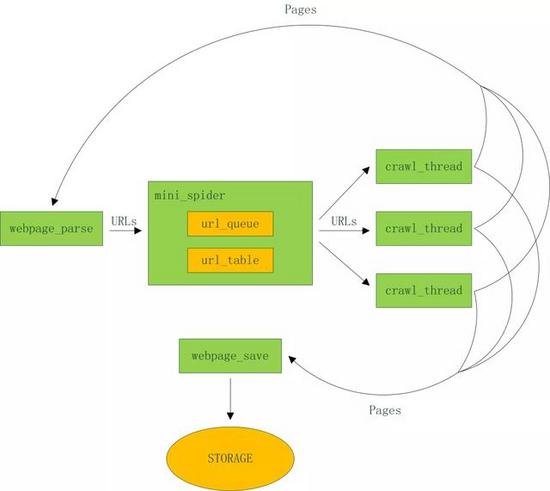
![]()
代码结构:
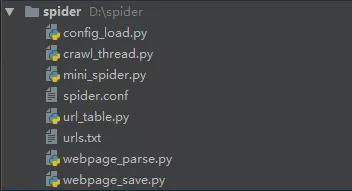
![]()
- config_load.py 配置文件加载
- crawl_thread.py 爬取线程
- mini_spider.py 主线程
- spider.conf 配置文件
- url_table.py url队列、url表
- urls.txt 种子url集合
- webpage_parse.py 网页分析
- webpage_save.py 网页存储
- 看看配置文件里有什么内容:
- spider.conf

![]()

![]()
![]()

![]()

![]()
![]()
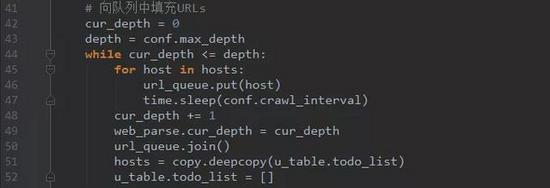
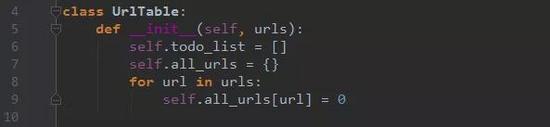
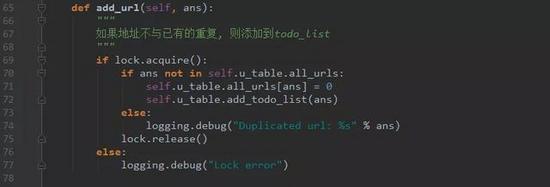
Step 3. 记录哪些网页已经下载过的小本本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时候,这个网页可能被多次访问到。为了防止一个网页被下载和解析多次,需要一个URL表记录哪些网页已经下载过。再遇到这个网页的时候,我们就可以跳过它。
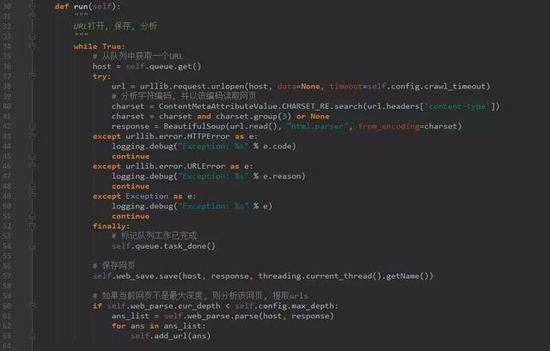
crawl_thread.py
![]()

![]()

![]()
![]()
Step 5. 页面分析模块
从网页中解析出URLs或者其他有用的数据。这个是上期重点介绍的,可以参考之前的代码。
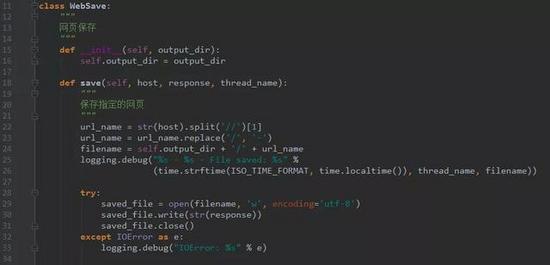
Step 6. 页面存储模块
保存页面的模块,目前将文件保存为文件,以后可以扩展出多种存储方式,如mysql,mongodb,hbase等等。
webpage_save.py
![]()
写到这里,整个框架已经清晰的呈现在大家眼前了,千万不要小看它,不管多么复杂的框架都是在这些基本要素上扩展出来的。
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/uEva2e7
需要源代码的或者想了解更多的(点击这里下载)