博文首先说明索引的分类及创建,然后会涉及到索引的可用性选择以及索引的优化。
索引是什么?先说创建索引的目的,创建索引是为提高对数据的查询速度。在字典的目录中,我们可以很快找到某个字的位置,索引的作用就是类似于目录,是为了针对select操作而存在的。
【索引是创建在表上,是对数据库表中一列或多列的值进行排序的一种结构。索引可以提高查询速度。】
就像在字典上创建索引会增加字典的厚度一样,数据库的索引也是有缺点的,在文章的后面会说明。
索引有两种存储类型,B型树索引和Hash索引。innoDB和MyISAM存储引擎支持B型树索引,memory存储引擎两者都支持。默认是B型树索引。
【本片博文如果没有特别说明,创建的都是B型树索引(用的最多)】
创建索引以及索引的分类
- 普通索引
在创建索引时,不附加任何限制条件。这类索引可以创建在任何数据类型中,值是否唯一和非空有本身的完整性约束条件决定。
索引的创建可以在创建表时创建,也可以在建表之后创建。
#1.创建表时创建索引
CREATE TABLE tb1( id int, name varchar(20), INDEX id_index (id DESC) ) #index|key 作为索引的标识, id_index为索引名(可以不指定会有默认的),后面必须加上一个括号,括号里创建索引的字段,最后的DESC表示倒序,ASC表示正序,默认正序!
#2.创建表之后添加索引,有两种方法如下:
第一种:使用create语句
CREATE 【UNIQUE|FULLTEXT|SPATIAL】INNEX 索引名 ON TABLE_NAME (属性名 [(长度)]);
第二种:使用alter语句。
ALTER TABLE TABLE_NAME ADD 【UNIQUE|FULLTEXT|SPATIAL】 INNEX 索引名 (属性名[(长度)]);
##需要注意的是在char类型的字段上创建索引时,可以指定在当前字段的前几个字符来创建索引。
#如下:在上面的表的name字段的前5个字符创建索引。(这里的索引只是为了练习)
CREATE INDEX index_name ON tb1 (name(5) DESC);
mysql> SHOW CREATE TABLE tb1G
*************************** 1. row ***************************
Table: tb1
Create Table: CREATE TABLE `tb1` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
KEY `index_name` (`name`(5)) #创建的以name字段的前5个字符为索引
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec
- 唯一性索引
使用UNIQUE参数可以设置索引为唯一性索引。限制该索引值必须是唯一的。主键是一种特殊的唯一性索引。
在上面的表中,id字段一般为唯一性索引,我们在id字段上创建唯一性索引。
ALTER TABLE tb1 ADD UNIQUE INDEX index_id ( id ASC ); #在已经创建的表上添加唯一性索引
- 全文索引
使用fulltext参数可以设置索引为全文索引。全文索引只能创建在CHAR, VARCHAR,TEXT类型的字段上。查询数据量较大的字符串类型字段时,使用全文索引可以提高查询速度。
#在表中添加一个text字段,然后在字段上创建全文索引 ALTER TABLE tb1 ADD info text; CREATE FULLTEXT INDEX index_info ON tb1 ( info )
- 单列索引
在表中一个字段上创建的索引。以上的创建的三个索引均为单列索引。
- 多列索引
多列索引时在表的多个字段上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询。但是,只有查询条件中使用了这些字段的第一个字段时,索引才会被引用。
CREATE INDEX name_index ON employees ( first_name, last_name ); #在employees表中创建一个双列索引
需要注意的是,在多列索引时,在查询时,只有第一个字段被引用,那么这个索引才会被使用。
#有如下表,在表中插入数据 CREATE TABLE tb2 ( a INT, b INT ); INSERT INTO tb2 VALUES ( 1, 2 ), ( 4, 3 ), ( 2, 1 ), ( 5, 9 ), ( 3, 4 ),
( 2, 4 ),
( 3, 1 ); CREATE INDEX test_index ON tb2 ( a, b );
#然后在表中创建一个复合索引如图。
特别需要注意的是:创建索引之后对应的字段时逻辑有序的,而不是物理有序。
索引创建之后,表中的这些数据逻辑顺序如下:
+------+------+
| a | b | #字段a是按照逻辑大小的顺序排列的,但是字段b却不是,
+------+------+ #因此在使用索引时,必须使用第一个字段才可以在查询中使用索引
| 1 | 2 |
| 2 | 1 |
| 2 | 4 |
| 3 | 1 |
| 3 | 4 |
| 4 | 3 |
| 5 | 9 |
+------+------+
- 空间索引
空间索引的存储引擎必须为MyIsam。使用SPATIAL参数可以设置索引为空间索引。空间索引只能建立在空间类型上。MySQL中的空间数据类型包括GEOMETRY,POINT,LINESTRING和POLYGON等。(暂时没用到,不详细说明)
删除索引
删除索引可以使用如下语句:
drop index 索引名 on 表名; mysql> drop index test_index on tb2; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
索引为何会提高数据查询的效率?
(提高数据的查询速度,最重要的是想办法减少数据查询时对磁盘的IO操作,而服务器的CPU运算基本都是盈余的)
【待续】
索引的可选择性:
创建一个索引,我们需要去评估这个创建的是否合理?如果一个表的数据量很少,或者这个字段的值重复性比较多,那么创建这个索引就没有意义。在一张数据量比较大的表中,并且这个字段的重复性值不高,这时候我们可以创建索引。
我们如何知道这个字段究竟有多少条不重复的数据?
MySQL给我们提供了一个参数:Cardinality,这个值表示的是记录不重复数据量的行数。
mysql> show index from employeesG *************************** 1. row *************************** Table: employees Non_unique: 0 Key_name: PRIMARY Seq_in_index: 1 Column_name: emp_no Collation: A Cardinality: 299290 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 2. row *************************** Table: employees Non_unique: 1 Key_name: name_index Seq_in_index: 1 Column_name: first_name Collation: A Cardinality: 1288 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 3. row *************************** Table: employees Non_unique: 1 Key_name: name_index Seq_in_index: 2 Column_name: last_name Collation: A Cardinality: 279473 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: 3 rows in set (0.00 sec) #各个字段解释如下:
Table: 表名。
Non_unique:如果索引不能包含重复项则为0,可以则为1.
Key_name:索引的名字。
Seq_in_index:当前字段在复合索引中是第几个字段。(单列索引则为1)
Column_name:字段名字。
Collation:列如何在索引中排序,值A表示升序。未排序则为NULL。
Cardinality:利用抽样法估计的当前字段中不重复的行数。
Sub_part:索引前缀,若是整个字段索引则值为NULL,若是仅字符类型的前几个字符索引,则显示字符的数量。
Packed: 指示关键字如何被压缩。如果没有被压缩,则为NUL
Index_type:索引类型。(BTREE, FULLTEXT,HASH, RTREE)
commecnt: Information about the index not described in its own column, such as disabled if the index is disabled.
Index_comment:创建索引时的一些说明信息。
#证明索引可行性的时候,我们需要额外关注Cardinality这个数值,这个数值的更新可以人为的使用ANALYZE table(myisam存储引擎需要使用 myisamchk -a)
在innodb存储引擎中,Cardinality统计信息的更新发生在两个操作中:INSERT,UPDATE。但是不是会在每次操作时,都会更新这个数值,innodb存储引擎更新Cardinality值得策略为:
- 表中的1/16数据已经发生变化
- stat_modified_counter >2 000 000 000
第一种策略为自上次统计Cardinality信息后,表中1/16的数据已经发生变化,这时需要更新Cardinality信息。第二种:如果对表中某一行的数据频繁的更新,那么表中的数据并没有增加,
发生变化的还是这一行数据,那么第一种策略就无法生效。因此在innodb存储引擎内部有一个计数器stat_modified_counter,用来表示发生变化的次数,当更新的值大于指定的值时,
就会更新Cardinality的数值。
innodb打开某些INFORMATION_SCHEMA表,或者使用show table status和show index,抑或在MySQL客户端开启自动补全功能的时候都会触发索引统计信息的更新,如果服务器上有大量的数据,这可能就是个很严重的问题,尤其是当I/O比较慢的时候,客户端或者监控程序触发索引信息采样更新时会导致大量的锁,并给服务器带来很多额外的压力。因此MySQL内部使用了一个参数来关闭自动触发的索引采样。
mysql> show variables like "innodb_stats_on_metadata"; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | innodb_stats_on_metadata | OFF | +--------------------------+-------+ 1 row in set (0.00 sec) mysql>
那么在MySQL内部,是怎么样通过采样计算card'inality值的?默认innodb存储引擎对8个叶子节点进行采样处理。
mysql> show variables like "innodb_stats_sample_pages"; #默认的采样的8个叶子节点。 +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_stats_sample_pages | 8 | +---------------------------+-------+ 1 row in set (0.01 sec)
#采样过程如下:
- 取得B+树索引中叶子节点的数量,记为A。
- 随机取得B+树索引中的8个叶子节点。统计每个页不同的记录个数,即为p1,p2,p3,....p8
- 根据采样信息给出cardinality的预估值: cardinality=(p1+p2+...p8)*A/8
#随机采样获得的8个页是随机的,因此每次采样得到的cardinality值可能是不同的。
innodb_stats_sample_pages参数用来控制随机采样叶的多少,而innodb_stats_method用来判断如何对待索引中出现的null值激励。该值默认值为nulls_equal,表示将null值视为相等的记录。
其有效值还有null_unequal,null_ignored,分别表示将null值记录视为不同的记录和忽略null值的记录。【注意三个值的区别,视为相等的记录,视为不同的记录,忽略null值】
与cardinality值相关的还有如下的几个参数:
innodb_stats_persistent: 是否将命令analyze table计算得到的cardinality值存放到磁盘上。若是,则这样做的好处是可以减少重新计算每个索引的cardinality值。
例如当MySQL数据库重启时。此外,用户也可以通过命令create table和alter table的选项stats_persistent来对每张表进行控制。
innodb_stats_on_metadata: 当命令show table status, show index以及访问information_schema架构下的表tables和statistics使,是否需要重新计算cardinality值,默认是OFF。
innodb_stats_persistent_sample_pages:若参数innodb_stats_persistent设置为ON,该参数表示analyze table更新cardinality值时的每次采样页的数量。默认是20.
innodb_stats_transient_sample_pages: 这个参数用来取代之前版本的innodb_stats_sample_pages参数,表示每次采样页的数量。默认是8.
查看表的一些基本信息:
mysql> show table status like "employees"G *************************** 1. row *************************** Name: employees Engine: InnoDB Version: 10 Row_format: Dynamic #表格式 Rows: 299290 #表行数,对于myisam表这个值时精确的,对innodb这个值时估算的,可以使用select count(*) from tbname.来精确计算 Avg_row_length: 50 #表的评价每行的长度 Data_length: 15220736 #对myisam表,是数据文件的长度,以字节为单位。对innodb表,是为聚簇索引分配的大致内存量,以字节为单位。 Max_data_length: 0 #对于MyISAM,Max_data_length是数据文件的最大长度。这是在给定数据指针大小的情况下可以存储在表中的数据的总字节数,未使用innodb。 Index_length: 0 Data_free: 2097152 # Auto_increment: NULL #下一个AUTO_INCREMENT值 Create_time: 2018-10-07 16:54:40 Update_time: NULL Check_time: NULL Collation: latin1_swedish_ci #排序规则 Checksum: NULL #实时校验和 Create_options: Comment: 1 row in set (0.01 sec)
字段的详细解释可以查看:https://dev.mysql.com/doc/refman/5.7/en/show-table-status.html
在这里我们暂时只用到: Rows
#information_schema:这个库中tables表和show table status输出的内容是一样。
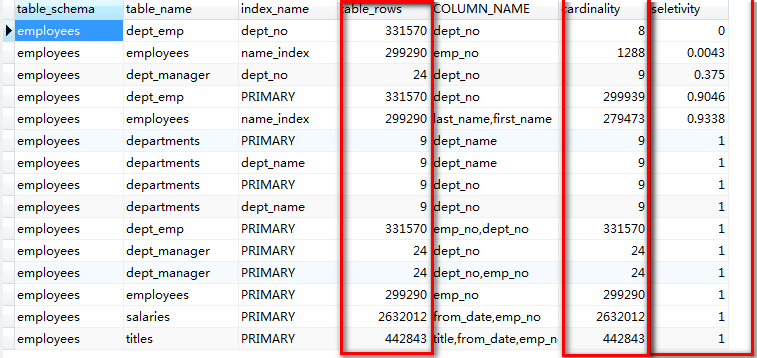
可选择性计算: Cardinality/ table_rows,数值越接近1,则说明索引的可选择性越高。
查看数据库中指定库中表的索引的可选择性,可以使用如下代码:


USE information_schema; SELECT t.table_schema, t.table_name, a.index_name, t.table_rows, a.COLUMN_NAME, a.cardinality, a.cardinality / t.table_rows AS seletivity FROM TABLES t INNER JOIN ( SELECT s.table_schema, s.table_name, s.index_name, b.COLUMN_NAME, s.cardinality FROM statistics s INNER JOIN ( SELECT table_schema, table_name, index_name, GROUP_CONCAT(COLUMN_NAME) AS COLUMN_NAME, max(seq_in_index) AS seq_in_index FROM STATISTICS WHERE table_schema = "employees" GROUP BY table_schema, table_name, index_name ) b ON s.table_schema = b.table_schema AND s.table_name = b.table_name AND s.seq_in_index = b.seq_in_index ) a ON t.table_schema = a.table_schema AND t.table_name = a.table_name ORDER BY seletivity
结果如下:
explain语句
创建索引之后,我们可以使用explain语句查看select查询是否使用了索引。
mysql> EXPLAIN SELECT * from employees LIMIT 1; +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299246 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
#explain语句各个字段解释如下:
id: 表示当前select语句的编号,该值可能为空,如果行联合了其他行的结果;在这种情况下table列显示的是,引用的行的并集。
select_type: 这个值有很多,暂时可以先记以下几个:
- SIMPLE: 简单查询,不包含连接查询和子查询。
- PRIMARY: 最外层查询,主键查询
- UNION:连接查询的第二个或后面的查询语句。 其余参数可以查看https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
table: 查询的表名
partitions:显示查询使用的分区,若为NULL则未使用分区。
type:表示表的连接类型,有如下取值:
- const :表示表中有多条记录,但只从表中查询一条记录;
- eq_ref :表示多表连接时,后面的表使用了UNIQUE或者PRIMARY KEY;
- ref :表示多表查询时,后面的表使用了普通索引;
- unique_ subquery:表示子查询中使用了UNIQUE或者PRIMARY KEY;
- index_ subquery:表示子查询中使用了普通索引;
- range :表示查询语句中给出了查询范围;
- index :表示对表中的索引进行了完整的扫描;
- all :表示此次查询进行了全表扫描;(一般来说全表扫描需要优化,表的记录很少除外)
possible_keys:表示查询中可能使用的索引;如果备选的数量大于3那说明已经太多了,因为太多会导致选择索引而损耗性能, 所以建表时字段最好精简,同时也要建立联合索引,避免无效的单列索引;
key: 查询实际使用的索引(不太准确,可以查阅官方文档)。
key_len:索引的长度
ref: REF列显示哪些列或常量与键列中所命名的索引进行比较,以从表中选择行。
rows: 查询扫描的行数。
filtered:表示按条件过滤表行的百分比,最大为100表示100%。
Extra: 表示查询额外的附加信息说明。
上面的expalin语句也可以换位desc命令。
除了直接使用explain命令之外,MySQL5.7还支持json格式的输出,
mysql> EXPLAIN format=json SELECT * from employees LIMIT 1G *************************** 1. row *************************** EXPLAIN: { "query_block": { "select_id": 1, "cost_info": { "query_cost": "60778.20" }, "table": { "table_name": "employees", "access_type": "ALL", "rows_examined_per_scan": 299246, "rows_produced_per_join": 299246, "filtered": "100.00", "cost_info": { "read_cost": "929.00", "eval_cost": "59849.20", "prefix_cost": "60778.20", "data_read_per_join": "13M" }, "used_columns": [ "emp_no", "birth_date", "first_name", "last_name", "gender", "hire_date" ] } } } 1 row in set, 1 warning (0.00 sec) mysql>