下面是莫尔斯编码的示例,大家把 1 看作是短点(嘀),把 11 看作是长点(嗒)即可。
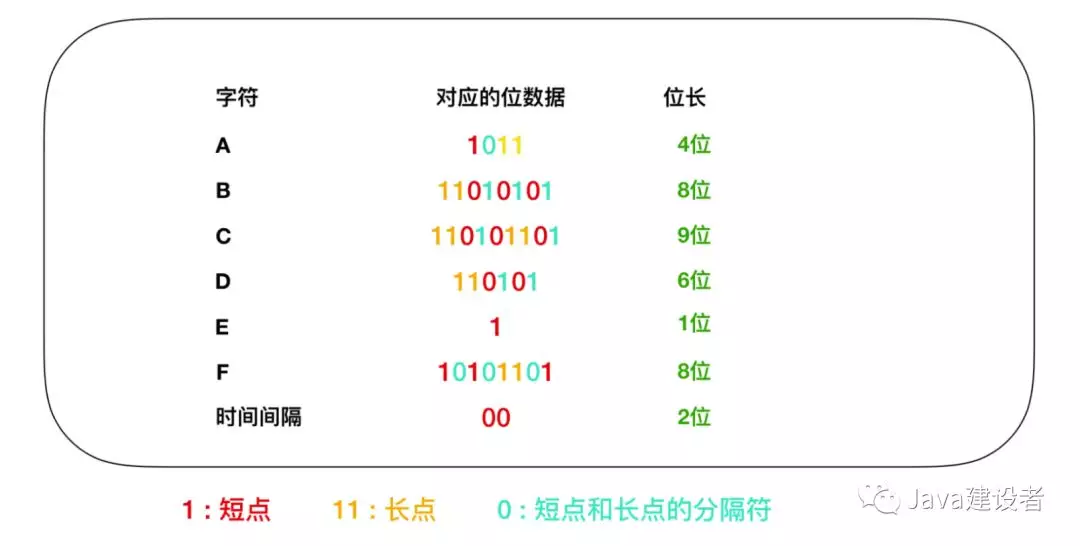
莫尔斯编码一般把文本中出现最高频率的字符用短编码 来表示。如表所示,假如表示短点的位是 1,表示长点的位是 11 的话,那么 E(嘀)这一数据的字符就可以用 1 来表示,C(滴答滴答)就可以用 9 位的 110101101来表示。在实际的莫尔斯编码中,如果短点的长度是 1 ,长点的长度就是 3,短点和长点的间隔就是1。这里的长度指的就是声音的长度。比如我们想用上面的 AAAAAABBCDDEEEEEF 例子来用莫尔斯编码重写,在莫尔斯曼编码中,各个字符之间需要加入表示时间间隔的符号。这里我们用 00 加以区分。
所以,AAAAAABBCDDEEEEEF 这个文本就变为了 A * 6 次 + B * 2次 + C * 1次 + D * 2次 + E * 5次 + F * 1次 + 字符间隔 * 16 = 4 位 * 6次 + 8 位 * 2次 + 9 位 * 1 次 + 6位 * 2次 + 1位 * 5次 + 8 位 * 1次 + 2位 * 16次 = 106位 = 14字节。
所以使用莫尔斯电码的压缩比为 14 / 17 = 82%。效率并不太突出。
用二叉树实现哈夫曼算法
刚才已经提到,莫尔斯编码是根据日常文本中各字符的出现频率来决定表示各字符的编码数据长度的。不过,在该编码体系中,对 AAAAAABBCDDEEEEEF 这种文本来说并不是效率最高的。
下面我们来看一下哈夫曼算法。哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样的编码(哈夫曼编码)对数据进行分割,就要由各个文件而定。用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据。
接下来,我们在对 AAAAAABBCDDEEEEEF 中的 A - F 这些字符,按照出现频率高的字符用尽量少的位数编码来表示这一原则进行整理。按照出现频率从高到低的顺序整理后,结果如下,同时也列出了编码方案。
| 字符 | 出现频率 | 编码(方案) | 位数 |
|---|---|---|---|
| A | 6 | 0 | 1 |
| E | 5 | 1 | 1 |
| B | 2 | 10 | 2 |
| D | 2 | 11 | 2 |
| C | 1 | 100 | 3 |
| F | 1 | 101 | 3 |
在上表的编码方案中,随着出现频率的降低,字符编码信息的数据位数也在逐渐增加,从最开始的 1位、2位依次增加到3位。不过这个编码体系是存在问题的,你不知道100这个3位的编码,它的意思是用 1、0、0这三个编码来表示 E、A、A 呢?还是用10、0来表示 B、A 呢?还是用100来表示 C 呢。
而在哈夫曼算法中,通过借助哈夫曼树的构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体系。不过哈夫曼树的算法要比较复杂,下面是一个哈夫曼树的构造过程。
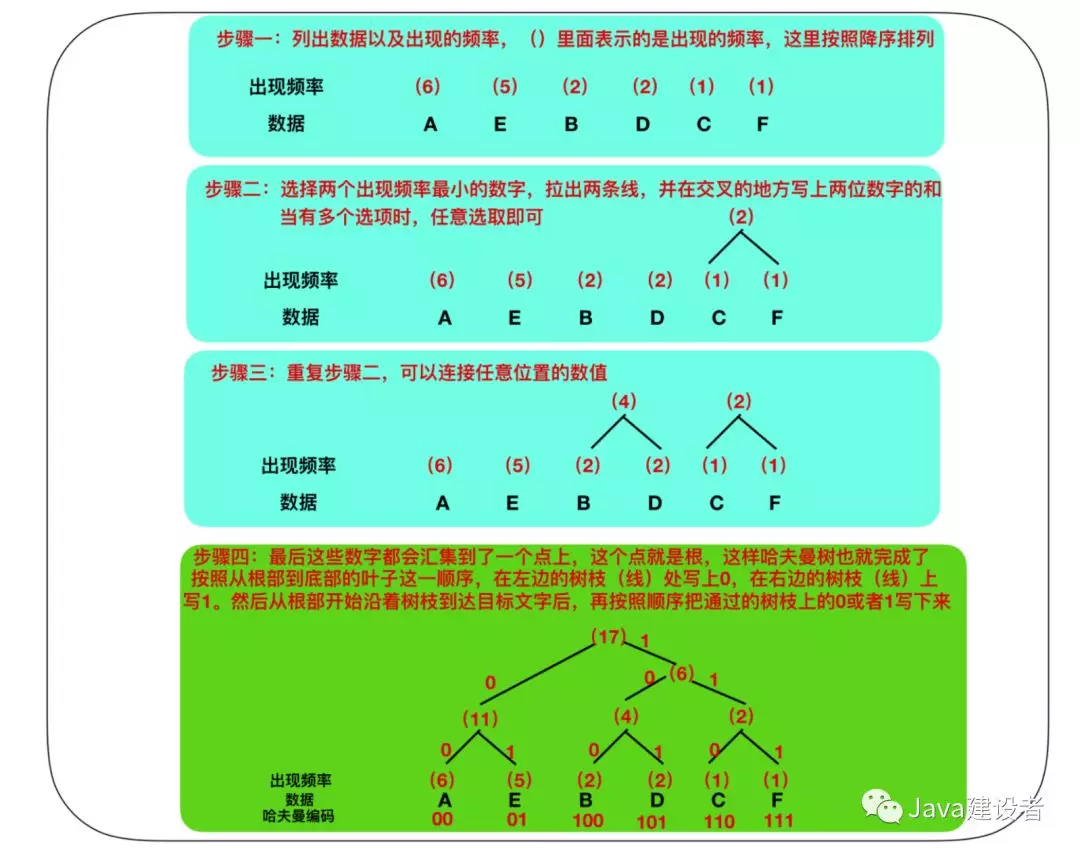
哈夫曼树能够提升压缩比率
使用哈夫曼树之后,出现频率越高的数据所占用的位数越少,这也是哈夫曼树的核心思想。通过上图的步骤二可以看出,枝条连接数据时,我们是从出现频率较低的数据开始的。这就意味着出现频率低的数据到达根部的枝条也越多。而枝条越多则意味着编码的位数随之增加
接下来我们来看一下哈夫曼树的压缩比率,用上图得到的数据表示 AAAAAABBCDDEEEEEF 为 000000000000 100100 110 101101 0101010101 111,40位 = 5 字节。压缩前的数据是 17 字节,压缩后的数据竟然达到了惊人的5 字节,也就是压缩比率 = 5 / 17 = 29% 如此高的压缩率,简直是太惊艳了。
| 文件类型 | 压缩前 | 压缩后 | 压缩比率 |
|---|---|---|---|
| 文本文件 | 14862字节 | 4119字节 | 28% |
| 图像文件 | 96062字节 | 9456字节 | 10% |
| EXE文件 | 24576字节 | 4652字节 | 19% |
可逆压缩和非可逆压缩
最后,我们来看一下图像文件的数据形式。图像文件的使用目的通常是把图像数据输出到显示器、打印机等设备上。常用的图像格式有 : BMP、JPEG、TIFF、GIF 格式等。
- BMP :是使用 Windows 自带的画笔来做成的一种图像形式
- JPEG:是数码相机等常用的一种图像数据形式
- TIFF: 是一种通过在文件中包含"标签"就能够快速显示出数据性质的图像形式
- GIF:是由美国开发的一种数据形式,要求色数不超过 256个
图像文件可以使用前面介绍的 RLE 算法和哈夫曼算法,因为图像文件在多数情况下并不要求数据需要还原到和压缩之前一摸一样的状态,允许丢失一部分数据。我们把能还原到压缩前状态的压缩称为 可逆压缩,无法还原到压缩前状态的压缩称为非可逆压缩 。
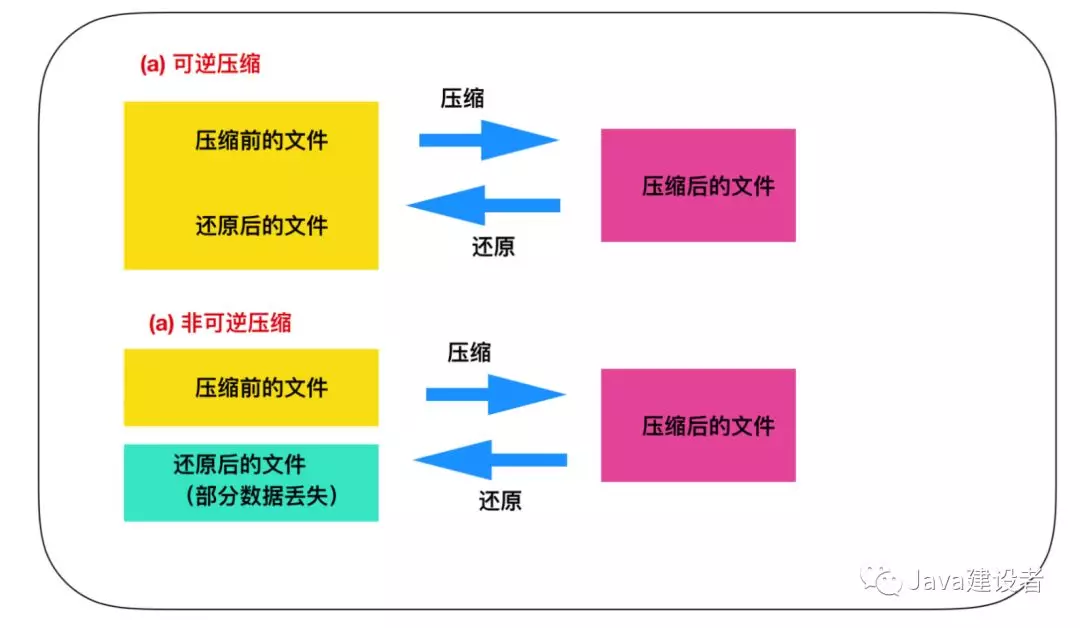
一般来说,JPEG格式的文件是非可逆压缩,因此还原后有部分图像信息比较模糊。GIF 是可逆压缩