好久没有写博客了,就分享一些乱七八糟的东西吧!
1.oracle递归查询
大家应该使用有的时候会使用递归查询数据库菜单的吧,比如下面这样的(偷的图)( ̄▽ ̄)ノ
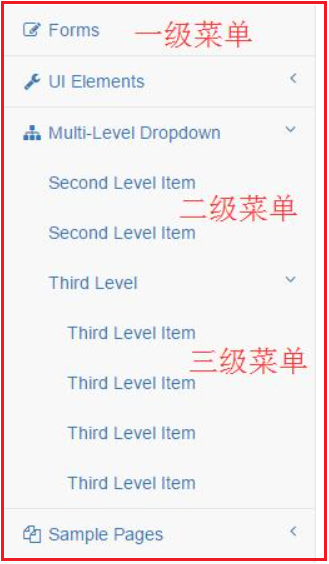
这种一般是业务管理系统比较多,比如菜单树,权限树或者机构树等等,从数据库中查询出的数据,然后使用java代码构建成前端需要的树的结构,然后返回给前端,ui组件渲染展示
所以通常我们会有下面这种的表(oracle版本建表语句可以自己做修改),有着父节点和字节点的关系,就是id和parent_id
CREATE TABLE jrbac_menu (
id number(8) primary key not null , --主键id
real_name varchar(50) NULL,
parent_id varchar(50) NULL, -- 父级菜单id
url_path varchar(500) NOT NULL,
icon varchar2(20) null,
torder varchar(50) NOT NULL
);
INSERT INTO jrbac_menu VALUES (1, 'Forms', null, 'forms.html', 'fa fa-edit', '0');
INSERT INTO jrbac_menu VALUES (2, 'UI Elements', null, 'Elements.html', 'fa fa-wrench', '1');
INSERT INTO jrbac_menu VALUES (3, 'Buttons', '2', 'buttons.html', 'Buttons', '0');
INSERT INTO jrbac_menu VALUES (4, 'Icons', '2', 'icons.html', 'Icons', '1');
INSERT INTO jrbac_menu VALUES (5, 'Multi-Level Dropdown', null, 'Dropdown.html', 'fa fa-sitemap', '2');
INSERT INTO jrbac_menu VALUES (6, 'Second Level Item', '5', 'second.html', 'Second', '0');
INSERT INTO jrbac_menu VALUES (7, 'Third Level', '5', 'Third.html', 'Third', '1');
INSERT INTO jrbac_menu VALUES (8, 'Third Level Item', '7', 'third.html', 'Third Level Item', '0');
至于java代码的话,会大概像下面这种写法(比较懒,代码是随便找的),简而言之就是:先找出所有的一级菜单,然后遍历每个一级菜单,找到每一个一级菜单的二级菜单,再用递归的方式找到三级菜单,四级菜单.....
public void testQueryMenuList() { // 所有的菜单数据 List<Menu> rootMenu = menuDao.queryMenuList(null); // 结果树 List<Menu> menuList = new ArrayList<Menu>(); // 先找到所有的一级菜单 for (int i = 0; i < rootMenu.size(); i++) { // 一级菜单没有parentId if (StringUtils.isBlank(rootMenu.get(i).getParentId())) { menuList.add(rootMenu.get(i)); } } // 为一级菜单设置子菜单,getChild是递归调用的 for (Menu menu : menuList) { menu.setChildMenus(getChild(menu.getId(), rootMenu)); } Map<String,Object> jsonMap = new HashMap<>(); jsonMap.put("menu", menuList); System.out.println(JSON.toJSONString(jsonMap)); } /** * 递归查找子菜单 * * @param id * 当前菜单id * @param rootMenu * 要查找的列表 * @return */ private List<Menu> getChild(String id, List<Menu> rootMenu) { // 子菜单 List<Menu> childList = new ArrayList<>(); for (Menu menu : rootMenu) { // 遍历所有节点,将父菜单id与传过来的id比较 if (StringUtils.isNotBlank(menu.getParentId())) { if (menu.getParentId().equals(id)) { childList.add(menu); } } } // 把子菜单的子菜单再循环一遍 for (Menu menu : childList) {// 没有url子菜单还有子菜单 if (StringUtils.isBlank(menu.getUrl())) { // 递归 menu.setChildMenus(getChild(menu.getId(), rootMenu)); } } // 递归退出条件 if (childList.size() == 0) { return null; } return childList; }
我以前也是这样的写的,这种写法就很烦,后来我就查了一下资料,可以直接使用sql递归查询
start with ... connect by prior 语法来实现递归查询,使用了这种语法之后,一条sql就实现上面一堆代码的功能了:
例如表中原始数据:
select * from jrbac_menu;
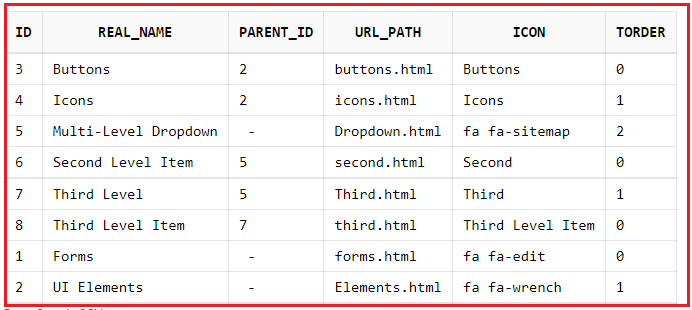
我们想要查询real_name为'Multi-Level Dropdown' 的一级菜单下的所有子菜单,我们把这个一级菜单当作一个根节点
从根节点向下递归查询:select * from jrbac_menu start with real_name='Multi-Level Dropdown' connect by prior id = parent_id;

sql使用说明,假如下面的sql是查询所有的子菜单节点,如果最后是parent_id=id,那么就是查询当前根节点的所有父级节点;

所以我觉得使用start with connect ... by prior 语法必须的两个条件:1.oracle数据库 2.菜单有个公共的根节点,或者只是查询其中其中一部分子树节点;
2.orcale分页查询
在mysql中我们可以使用limit关键字就很容易的实现了分页,但是在oracle中,语法就比较长一点
1.首先前端传递分页参数,page和pageSize
2.我们需要将他转为起始条数和终止条数:startSize=(page-1)*pageSize+1 endSize=page*pageSize
3.设置到oracle的分页语句中:
SELECT * FROM ( SELECT ROWNUM rowno, t.* FROM emp t WHERE hire_date BETWEEN TO_DATE ('20060501', 'yyyymmdd') AND ROWNUM <= #{endSize} ) table_alias WHERE table_alias.rowno >= #{startSize};
有兴趣的可以自己开发一个基于mybatis+oracle的分页插件:参考这里
不过这里是mysql的,可以将我上面写第2点和第3点丢过去,稍微魔改一下就行了
为什么需要自己开发一个分页插件呢?不是有开源的pageHelper么,哎,一言难尽,那种很老的项目的话我都不敢去引入第三方依赖,不要本来还能跑的,结果引入了第三方依赖出现奇怪的问题(╯—﹏—)╯(┷━━━┷
还有就是搞不懂为什么有的人就能每次都习惯用这么麻烦的分页语句,我第一次看的时候都看的有点懵逼,还是在不影响现在的功能的前提下,自己动手丰衣足食吧