原博客:
https://www.cnblogs.com/lujiango/p/7580558.html
http://www.importnew.com/28263.html
CouncurrentHashMap 线程安全
一、CouncurrentHashMap<jdk1.7>
1、底层:
(1)底层数据结构:
<jdk1.7>:数组(Segment) + 数组(HashEntry) + 链表(HashEntry节点)
底层一个Segments数组,存储一个Segments对象,一个Segments中储存一个Entry数组,存储的每个Entry对象又是一个链表头结点。
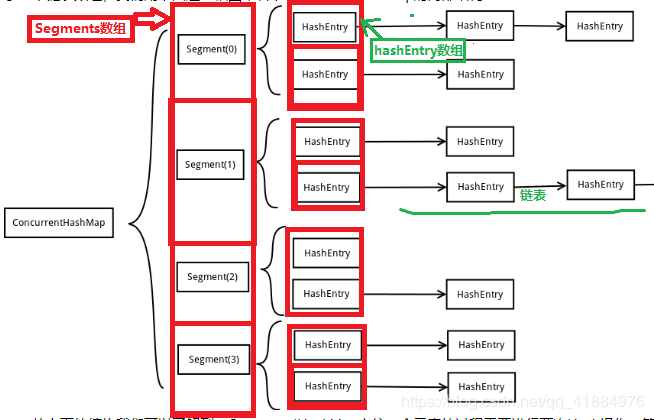
(2)基本属性:
jdk1,7
两个主要的内部类:
class Segment内部类,继承ReentrantLock,有一个HashEntry数组,用来存储链表头结点
int count ; // 此对象中存放的HashEntry个数
int threshold ; //扩容阈值
volatile HashEntry<K,V>[] table; //储存entry的数组,每一个entry都是链表的头部
float loadFactor; //加载因子- 1
- 2
- 3
- 4
方法:
v get(Object key, int hash); 获取相应元素
注意:此方法并不加锁,因为只是读操作,
V put(K key, int hash, V value, boolean onlyIfAbsent)
注意:此方法加锁
- 1
- 2
- 3
- 4
class HashEntry 定义的节点,里面存储的数据和下一个节点,在此不分析
(3)主要方法:
get():
1、第一次哈希 找到 对应的Segment段,
调用Segment中的get方法
2、再次哈希找到对应的链表,
3、最后在链表中查找。
// 外部类方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash); // 第一次hash 确定段的位置
}
//以下方法是在Segment对象中的方法;
//确定段之后在段中再次hash,找出所属链表的头结点。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
put():
1、首先确定段的位置,
调用Segment中的put方法:
2、加锁
3、检查当前Segment数组中包含的HashEntry节点的个数,如果超过阈值就重新hash
4、然后再次hash确定放的链表。
5、在对应的链表中查找是否相同节点,如果有直接覆盖,如果没有将其放置链表尾部
//外部类方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false); //先确定段的位置
}
// Segment类中的方法
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // 如果当个数超过阈值,就重新hash当前段的元素 ,
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
(4) 重哈希方式 :重点:
重哈希的方式 :只是对 Segments对象中的Hashentry数组进行重哈希
2、通过什么保证线程安全
<JDK1.7>,
分段锁 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
<jdk1.8>
使用的是优化的synchronized 关键字同步代码块 和 cas操作了维护并发。
3、和 hashTable的保证线程安全的机制有何联系
Hashtable通过synchronized修饰方法 来保证线程安全
通过segment(继承了ReentrantLock)调用父类的锁对象加锁来实现,
4、hashMap、 hashTable、 和 ConcurrentHashMap的区别
主要区别:
(1):实现线程安全的方式
hashMap是线程不安全的,
hashTable是线程安全的,实现线程安全的机制是使用Synchronized关键字修饰方法。
ConcurrentHashMap
<JDK1.7>,
ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
<jdk1.8>
使用的是优化的synchronized 关键字 和 cas操作了维护并发。
(2):底层数据结构:
hashMap同hashTable;都是使用数组 + 链表结构
ConcurrentHashMap
<jdk1.7> :使用 Segment数组 + HashEntry数组 + 链表
<jdk1.8> :使用 Node数组+链表+ 红黑树
(3) : 效率
hashMap只能单线程操作,效率低下
hashTable使用的是synchronized方法锁,若一个线程抢夺了锁,其他线程只能等到持锁线程操作完成之后才能抢锁操作
《1.7》ConcurrentHashMap 使用的分段锁,如果一个线程占用一段,别的线程可以操作别的部分,
《1.8》简化结构,put和get不用二次哈希,一把锁只锁住一个链表或者一棵树,并发效率更加提升。
二、CouncurrentHashMap<jdk1.8>底层:
(1)数据结构:
Node数组+链表 / 红黑树: 类似hashMap<jdk1.8>
Node数组使用来存放树或者链表的头结点,当一个链表中的数量到达一个数目时,会使查询速率降低,所以到达一定阈值时,会将一个链表转换为一个红黑二叉树,通告查询的速率。
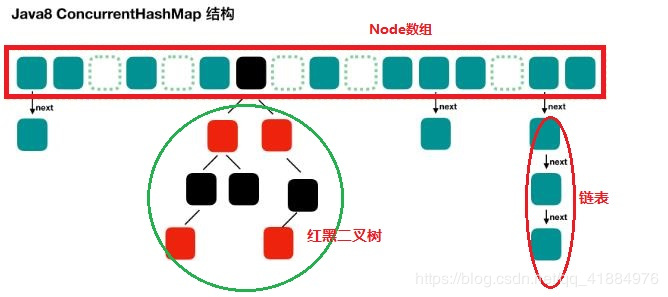
(2)主要属性:
外部类的基本属性
volatile Node<K,V>[] table; // Node数组用于存放链表或者树的头结点
static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的阈值 > 8 时
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转链表的阈值 <= 6 时
static final int TREEBIN = -2; // 树根节点的hash值
static final float LOAD_FACTOR = 0.75f;// 负载因子
static final int DEFAULT_CAPACITY = 16; // 默认大小为16
内部类
class Node<K,V> implements Map.Entry<K,V> {
int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
jdk1.8中虽然不在使用分段锁,但是仍然有Segment这个类,但是没有实际作用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3)主要方法:
1、构造方法:
构造方法并没有直接new出来一个Node的数组,只是检查数值之后确定了容量大小。
ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
// 如果传入的数值>= 最大容量的一半,就使用最大容量,否则使用
//1.5*initialCapacity +1 ,然后向上取最近的 2 的 n 次方数;
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2、put方法:
步骤:
1、检查Key或者Value是否为null,
2、得到Kye的hash值
3、如果Node数组是空的,此时才初始化 initTable(),
4、如果找的对应的下标的位置为空,直接new一个Node节点并放入, break;
5、
6、如果对应头结点不为空, 进入同步代码块
判断此头结点的hash值,是否大于零,大于零则说明是链表的头结点在链表中寻找,
如果有相同hash值并且key相同,就直接覆盖,返回旧值 结束
如果没有则就直接放置在链表的尾部
此头节点的Hash值小于零,则说明此节点是红黑二叉树的根节点
调用树的添加元素方法
判断当前数组是否要转变为红黑树
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());// 得到 hash 值
int binCount = 0; // 用于记录相应链表的长度
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将新new出来的 Node节点放入数组i下标位置
// 如果 CAS 失败,那就是有并发操作,进到下一个循环
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取链表头结点监视器对象
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值: 8
if (binCount >= TREEIFY_THRESHOLD)
// 如果当前数组的长度小于 64,那么会进行数组扩容,而不是转换为红黑树
treeifyBin(tab, i); // 如果超过64,会转成红黑树
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
3、get 方法
首先获取到Key的hash值,
然后找到对应的数组下标处的元素
如果次元素是我们要找的,直接返回,
如果次元素是null 返回null
如果Key的值< 0 ,说明是红黑树,
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //获得Hash值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) { // 比较 此头结点e是否是我们需要的元素
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val; // 如果是,就返回
}
else if (eh < 0) // 如果小于零,说明此节点是红黑树
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// 开始循环 查找
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4、扩容:tryPresize()
容后数组容量为原来的 2 倍。
private final void tryPresize(int size) {
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
5.其他内部类结构
Node:
ConcurrentHashMap存储结构的基本单元,实现了Map.Entry接口,用于存储数据。它对value和next属性设置了volatile同步锁(与JDK7的Segment相同),它不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。
TreeNode:
继承于Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树。
TreeBin:
从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制。
ForwardingNode:
一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找。
Unsafe和CAS:
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
6、通过什么保证线程安全
通过使用Synchroized关键字来同步代码块,而且只是在put方法中加锁,在get方法中没有加锁
在加锁时是使用头结点作为同步锁对象。,并且定义了三个原子操作方法
/ 获取tab数组的第i个node<br>
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// 利用CAS算法设置i位置上的node节点。csa(你叫私有空间的值和内存中的值是否相等),即这个操作有可能不成功。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// 利用volatile方法设置第i个节点的值,这个操作一定是成功的。
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3、和 hashTable的保证线程安全的机制有何联系
Hashtable通过synchronized修饰方法 来保证线程安全
通过synchronized同步代码块和 CAS操作来实现线程安全
由此抛出的问题:
为什么要用synchronized,cas不是已经可以保证操作的线程安全吗?
原因:
CAS也是适用一些场合的,比如资源竞争小时,是非常适用的,不用进行内核态和用户态之间
的线程上下文切换,同时自旋概率也会大大减少,提升性能,但资源竞争激烈时(比如大量线
程对同一资源进行写和读操作)并不适用,自旋概率会大大增加,从而浪费CPU资源,降低性
能。
原博客:
https://www.cnblogs.com/lujiango/p/7580558.html
http://www.importnew.com/28263.html
CouncurrentHashMap 线程安全
一、CouncurrentHashMap<jdk1.7>
1、底层:
(1)底层数据结构:
<jdk1.7>:数组(Segment) + 数组(HashEntry) + 链表(HashEntry节点)
底层一个Segments数组,存储一个Segments对象,一个Segments中储存一个Entry数组,存储的每个Entry对象又是一个链表头结点。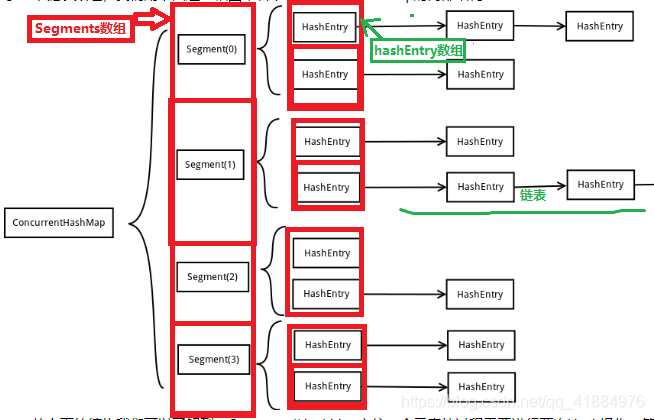
(2)基本属性:
jdk1,7
两个主要的内部类:
class Segment内部类,继承ReentrantLock,有一个HashEntry数组,用来存储链表头结点
int count ; // 此对象中存放的HashEntry个数
int threshold ; //扩容阈值
volatile HashEntry<K,V>[] table; //储存entry的数组,每一个entry都是链表的头部
float loadFactor; //加载因子
- 1
- 2
- 3
- 4
方法:
v get(Object key, int hash); 获取相应元素
注意:此方法并不加锁,因为只是读操作,
V put(K key, int hash, V value, boolean onlyIfAbsent)
注意:此方法加锁
- 1
- 2
- 3
- 4
class HashEntry 定义的节点,里面存储的数据和下一个节点,在此不分析
(3)主要方法:
get():
1、第一次哈希 找到 对应的Segment段,
调用Segment中的get方法
2、再次哈希找到对应的链表,
3、最后在链表中查找。
// 外部类方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash); // 第一次hash 确定段的位置
}
//以下方法是在Segment对象中的方法;
//确定段之后在段中再次hash,找出所属链表的头结点。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
put():
1、首先确定段的位置,
调用Segment中的put方法:
2、加锁
3、检查当前Segment数组中包含的HashEntry节点的个数,如果超过阈值就重新hash
4、然后再次hash确定放的链表。
5、在对应的链表中查找是否相同节点,如果有直接覆盖,如果没有将其放置链表尾部
//外部类方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false); //先确定段的位置
}
// Segment类中的方法
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // 如果当个数超过阈值,就重新hash当前段的元素 ,
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
(4) 重哈希方式 :重点:
重哈希的方式 :只是对 Segments对象中的Hashentry数组进行重哈希
2、通过什么保证线程安全
<JDK1.7>,
分段锁 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
<jdk1.8>
使用的是优化的synchronized 关键字同步代码块 和 cas操作了维护并发。
3、和 hashTable的保证线程安全的机制有何联系
Hashtable通过synchronized修饰方法 来保证线程安全
通过segment(继承了ReentrantLock)调用父类的锁对象加锁来实现,
4、hashMap、 hashTable、 和 ConcurrentHashMap的区别
主要区别:
(1):实现线程安全的方式
hashMap是线程不安全的,
hashTable是线程安全的,实现线程安全的机制是使用Synchronized关键字修饰方法。
ConcurrentHashMap
<JDK1.7>,
ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
<jdk1.8>
使用的是优化的synchronized 关键字 和 cas操作了维护并发。
(2):底层数据结构:
hashMap同hashTable;都是使用数组 + 链表结构
ConcurrentHashMap
<jdk1.7> :使用 Segment数组 + HashEntry数组 + 链表
<jdk1.8> :使用 Node数组+链表+ 红黑树
(3) : 效率
hashMap只能单线程操作,效率低下
hashTable使用的是synchronized方法锁,若一个线程抢夺了锁,其他线程只能等到持锁线程操作完成之后才能抢锁操作
《1.7》ConcurrentHashMap 使用的分段锁,如果一个线程占用一段,别的线程可以操作别的部分,
《1.8》简化结构,put和get不用二次哈希,一把锁只锁住一个链表或者一棵树,并发效率更加提升。
二、CouncurrentHashMap<jdk1.8>底层:
(1)数据结构:
Node数组+链表 / 红黑树: 类似hashMap<jdk1.8>
Node数组使用来存放树或者链表的头结点,当一个链表中的数量到达一个数目时,会使查询速率降低,所以到达一定阈值时,会将一个链表转换为一个红黑二叉树,通告查询的速率。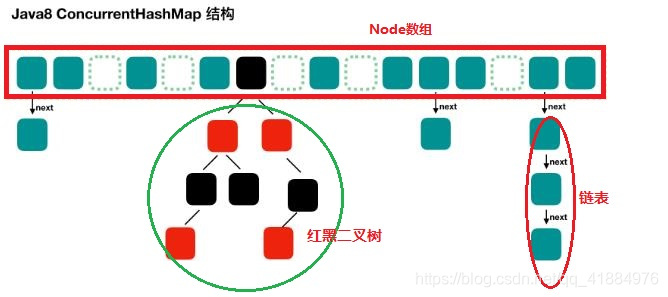
(2)主要属性:
外部类的基本属性
volatile Node<K,V>[] table; // Node数组用于存放链表或者树的头结点
static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的阈值 > 8 时
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转链表的阈值 <= 6 时
static final int TREEBIN = -2; // 树根节点的hash值
static final float LOAD_FACTOR = 0.75f;// 负载因子
static final int DEFAULT_CAPACITY = 16; // 默认大小为16
内部类
class Node<K,V> implements Map.Entry<K,V> {
int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
jdk1.8中虽然不在使用分段锁,但是仍然有Segment这个类,但是没有实际作用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3)主要方法:
1、构造方法:
构造方法并没有直接new出来一个Node的数组,只是检查数值之后确定了容量大小。
ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
// 如果传入的数值>= 最大容量的一半,就使用最大容量,否则使用
//1.5*initialCapacity +1 ,然后向上取最近的 2 的 n 次方数;
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2、put方法:
步骤:
1、检查Key或者Value是否为null,
2、得到Kye的hash值
3、如果Node数组是空的,此时才初始化 initTable(),
4、如果找的对应的下标的位置为空,直接new一个Node节点并放入, break;
5、
6、如果对应头结点不为空, 进入同步代码块
判断此头结点的hash值,是否大于零,大于零则说明是链表的头结点在链表中寻找,
如果有相同hash值并且key相同,就直接覆盖,返回旧值 结束
如果没有则就直接放置在链表的尾部
此头节点的Hash值小于零,则说明此节点是红黑二叉树的根节点
调用树的添加元素方法
判断当前数组是否要转变为红黑树
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());// 得到 hash 值
int binCount = 0; // 用于记录相应链表的长度
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将新new出来的 Node节点放入数组i下标位置
// 如果 CAS 失败,那就是有并发操作,进到下一个循环
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取链表头结点监视器对象
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值: 8
if (binCount >= TREEIFY_THRESHOLD)
// 如果当前数组的长度小于 64,那么会进行数组扩容,而不是转换为红黑树
treeifyBin(tab, i); // 如果超过64,会转成红黑树
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
3、get 方法
首先获取到Key的hash值,
然后找到对应的数组下标处的元素
如果次元素是我们要找的,直接返回,
如果次元素是null 返回null
如果Key的值< 0 ,说明是红黑树,
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //获得Hash值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) { // 比较 此头结点e是否是我们需要的元素
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val; // 如果是,就返回
}
else if (eh < 0) // 如果小于零,说明此节点是红黑树
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// 开始循环 查找
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4、扩容:tryPresize()
容后数组容量为原来的 2 倍。
private final void tryPresize(int size) {
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
5.其他内部类结构
Node:
ConcurrentHashMap存储结构的基本单元,实现了Map.Entry接口,用于存储数据。它对value和next属性设置了volatile同步锁(与JDK7的Segment相同),它不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。
TreeNode:
继承于Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树。
TreeBin:
从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制。
ForwardingNode:
一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找。
Unsafe和CAS:
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
6、通过什么保证线程安全
通过使用Synchroized关键字来同步代码块,而且只是在put方法中加锁,在get方法中没有加锁
在加锁时是使用头结点作为同步锁对象。,并且定义了三个原子操作方法
/ 获取tab数组的第i个node<br>
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// 利用CAS算法设置i位置上的node节点。csa(你叫私有空间的值和内存中的值是否相等),即这个操作有可能不成功。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// 利用volatile方法设置第i个节点的值,这个操作一定是成功的。
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3、和 hashTable的保证线程安全的机制有何联系
Hashtable通过synchronized修饰方法 来保证线程安全
通过synchronized同步代码块和 CAS操作来实现线程安全
由此抛出的问题:
为什么要用synchronized,cas不是已经可以保证操作的线程安全吗?
原因:
CAS也是适用一些场合的,比如资源竞争小时,是非常适用的,不用进行内核态和用户态之间
的线程上下文切换,同时自旋概率也会大大减少,提升性能,但资源竞争激烈时(比如大量线
程对同一资源进行写和读操作)并不适用,自旋概率会大大增加,从而浪费CPU资源,降低性
能