1.print:打印进度条
import time for i in range(0,101,2): time.sleep(0.1) char_num = i//2 #打印多少个'*' per_str = ' %s%% : %s ' % (i, '*' * char_num) if i == 100 else ' %s%% : %s'%(i,'*'*char_num) print(per_str,end='', flush=True) #小越越 : 可以把光标移动到行首但不换行
print(self, *args, sep=' ', end=' ', file=None) #sep=" "默认分隔符为空格,也可以其它,如:sep = "/",end = " ",默认换行,可以去掉“ ”,不换行;file,加入文件名,可以将输出到指定文件
2.序列:reversed(反序),slice()m[start:stop:step]
#reverse改变原有的列表,即改变列表本身
i = [1,2,3,4,5]
i.reverse()
print(i)
------------------------
#reversed保存原有列表,返回一个新的迭代器
l = (1,2,23,213,5612,342,43)
print(l)
print(list(reversed(l)))
print(l)
------------------------------------------
l = (1,2,23,213,5612,342,43)
sli = slice(1,5,2) #不常用,可以用索引分割
print(l[sli])
sort()-----从小到大排序
l = [1,-4,6,5,-10] l.sort() # 在原列表的基础上进行排序 print(l)
print(sorted(l,key=abs,reverse=True)) # 生成了一个新列表 不改变原列表 占内存 ;key=abs,指定排列条件,abs按照绝对值排序,reverse=True,从小到大,若改为False则是从大到小
print(l)
对比reverse与sort,都是在原有的基础上进行修改,若加上-ed则是重新生成一个新的序列,比较占内存
3.内置函数----eval,exec,compile
eval() 将字符串类型的代码执行并返回结果 print(eval("1+2"))-------3 ------------------------------------------ exec()将自字符串类型的代码执行 print(exec("1+3"))-------None exec("print('hello,world')")----hello,world
4.内存相关:
id(o) o是参数,返回一个变量的内存地址
hash(o) o是参数,返回一个可hash变量的哈希值,不可hash的变量被hash之后会报错
t = (1,2,3) l = [1,2,3] print(hash(t)) #可hash print(hash(l)) #会报错
-----------------------------------------------------------
hash函数会根据一个内部的算法对当前可hash变量进行处理,返回一个int数字。
*每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
5.和调用相关
callable(o),o是参数,看这个变量是不是可调用。
如果o是一个函数名,就会返回True
def func(): pass print(callable(func)) #参数是函数名,可调用,返回True print(callable(123)) #参数是数字,不可调用,返回False
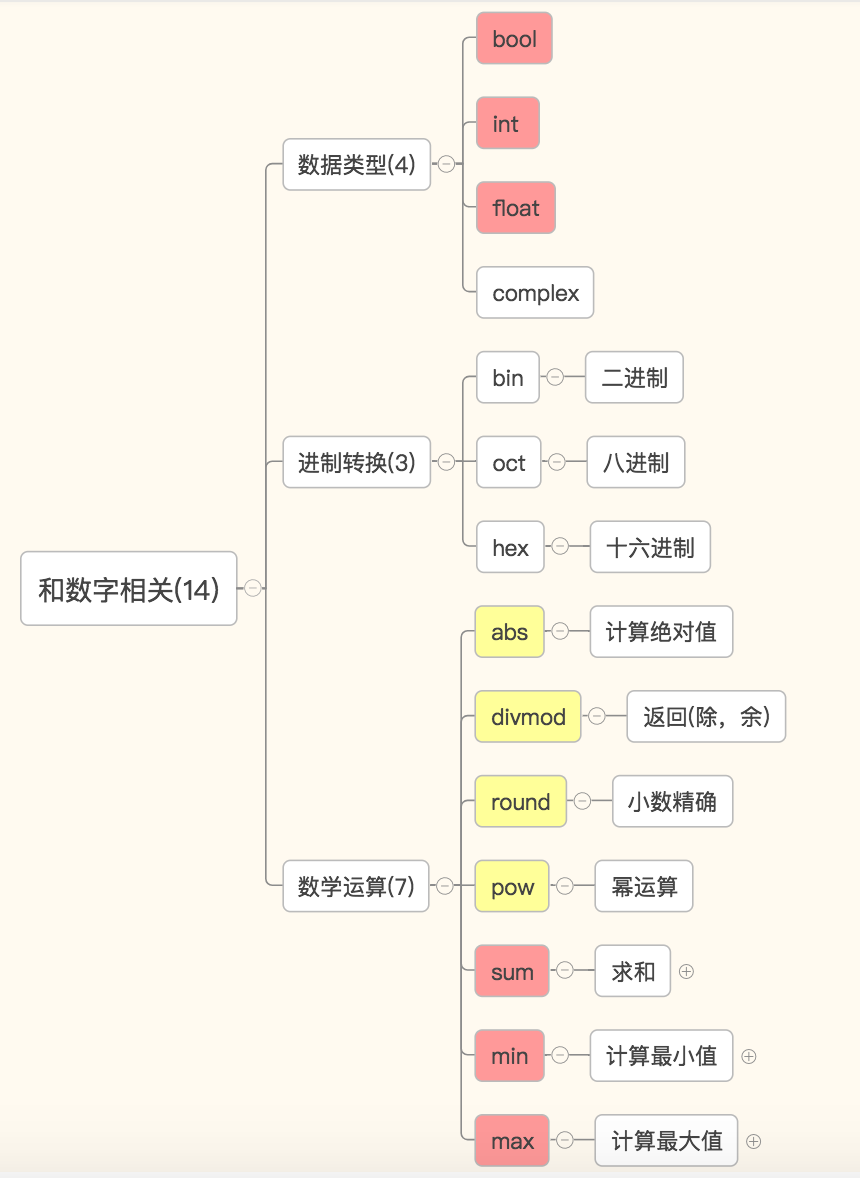
6.数字相关
7.匿名函数
#这段代码 def calc(n): return n**n print(calc(10)) -------------------------- #换成匿名函数 calc = lambda n:n**n #函数名 = lambda 参数:返回值 print(calc(10))
-------------------------------
#参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型
filter()、map()、reduce()。这些全局函数可以和lambda配合使用。
filter(函数,序列)-----只能输入函数名,不能调用
函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该函数接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
res = filter(lambda x:x>10,[5,8,11,9,15]) for i in res: print(i) 输出 11 15
-------------------------------------------
def is_odd(x):
return x % 2 == 1
ret = filter(is_odd, [1, 6, 7, 12, 17]) # 等价于; i for i in [1, 6, 7, 12, 17] if x% 2 == 1
print(ret) #生成一个迭代器,节省内存
for i in ret:
print(i)
输出:
<filter object at 0x000001F084E1E518>
1
7
17
-------------------------------------------
# 输出可以平方根的数值
from math import sqrt #sqrt:平方根 # 等价于; i for i in range(1,101) if sqrt(i)%1 == 0
def func(num):
res = sqrt(num)
return res % 1 == 0 #判断为整数
ret = filter(func,range(1,101))
for i in ret:
print(i)
map(函数,序列)-----只能输入函数名,不能调用
map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
ret = map(abs,[1,-4,6,-8]) #abs,求绝对值 print(ret) for i in ret: print(i)
filter 执行了filter之后的结果集合 <= 执行之前的个数,filter只管筛选,不会改变原来的值(filter就是一个过滤器)
map 执行前后元素个数不变,值可能发生改变
filter与map语法一致(函数,序列),返回一个迭代器
8.formate
#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐 print(format('test', '<20')) print(format('test', '>20')) print(format('test', '^20'))
9.all/any
print(all(['a','',123]))-----False print(all(['a',123]))--------True print(all([0,123]))----------False
传入迭代对象,只要一个为空则为fales
---------------------------------
print(any(['',True,0,[]]))
一个为真,全为真
10.zip
l = [1,2,3,4,5] l2 = ['a','b','c','d'] l3 = ('*','**',[1,2]) d = {'k1':1,'k2':2} for i in zip(l,l2,l3,d): print(i) --------------------------------- output: (1, 'a', '*', 'k2') (2, 'b', '**', 'k1') #以短为准,d只要两个键值,所以输出两个
习题:
#现有两个元组t1=(('a'),('b')),t2=(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}] t1 = (('a'),('b')) t2 = (('c'),('d')) test = lambda t1,t2 :[{i:j} for i,j in zip(t1,t2)] #(将键值,数值打包成元组)
print(test(t1,t2))
#zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map