原文:https://zhuanlan.zhihu.com/p/25836678
1.voting
对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类。
2.averaging
对于回归问题,一方面采用简单平均法,另一方面采用加权平均法,加权平均法的思路:权值可以用排序的方法确定或者根据均方误差确定。
3.stacking
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking。假设我们有3个基模型M1、M2、M3。下面先看一种错误的训练方式:
【1】基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1(对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3):
【2】 分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2:
【3】 再用第二层的模型M4训练train2,预测test2,得到最终的标签列:
Stacking本质上就是这么直接的思路,但是这样肯定是不行的,问题在于P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。我们以2折交叉验证得到P1为例,假设训练集为4行3列:
将其划分为两部分:
,
用traina训练模型M1,然后在trainb上进行预测得到preb3和pred4:
在trainb上训练模型M1,然后在traina上进行预测得到pred1和pred2:
然后把两个预测集进行拼接:
对于测试集T1的得到,有两种方法。注意到刚刚是2折交叉验证,M1相当于训练了2次,所以一种方法是每一次训练M1,可以直接对整个test进行预测,这样2折交叉验证后测试集相当于预测了2次,然后对这两列求平均得到T1。或者直接对测试集只用M1预测一次直接得到T1。P1、T1得到之后,P2、T2、P3、T3也就是同样的方法。理解了2折交叉验证,对于K折的情况也就理解也就非常顺利了。所以最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
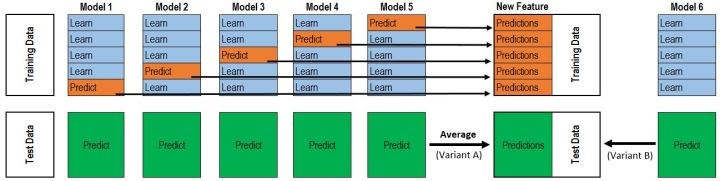
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。再分析作者的代码也就很清楚了。也就是刚刚提到的两层循环。