在浏览网页,编敲代码时,偶尔会碰到一些乱码问题。
比如在打开一个网页时。没有一个正常字符可辨识的。全是一些奇怪的符号,方块、问号等等。
通过浏览器的tools->encoding选择UTF-8或者GBK。显示就正常了。为什么会乱码。UTF-8和GBK又是什么东西呢?
汉子,字母等字符。我们能够识别。并理解它们的表达信息。但计算机不能直接识别这些字符。它仅仅能理解二进制信息。
为了让计算机能够处理。表示字符。我们须要将字符转换成二进制表达,交给计算机处理。再将计算机处理输出的二进制信息转换成字符。
所以这里须要一种字符与二进制的一对一映射关系。在计算机发展早期,用英文字符基本能够搞定一切,所以ASCII用32-127数值能够表示全部的字母和符号。小于32的数值表示非打印的控制字符。例如以下所看到的:
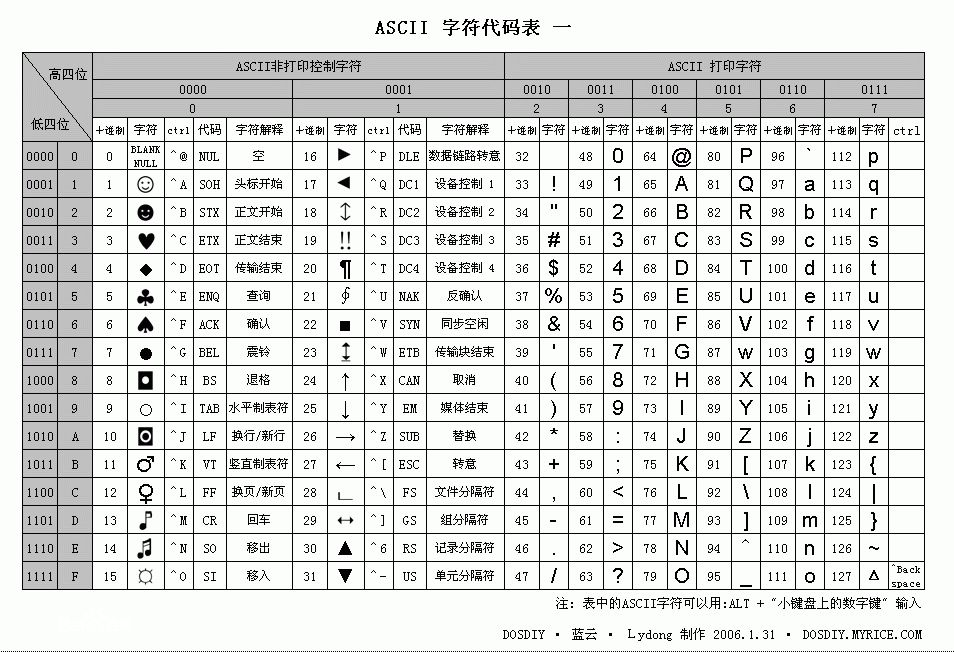
随着计算机的普及。世界各国都在使用。
他们的字符也须要用计算机来存储和表示。我们中文也一样。为了可以表达全部的字符,unicode产生了,并成为了标准。unicode涵盖世界上全部字符到代码值(code point)的映射[2],如“A”的映射为U+0041,“中”的映射为U+2D2E。
尽管unicode定义了字符到代码值的映射,但它并没有规定计算机怎样来存储这个代码值。于是就有了UTF-16的产生,UTF-16直接将代码值中数值作为字符的二进制表示,这样每一个字符基本都占用两个字节,如“中”,用“x2Dx4E”表示了。
这么一弄,美国人不干了,他们原本一个字符仅仅要一个字节表示就行。如今须要两个字节。所需存储资源无故多了一倍。所以他们大部分还是继续使用ASCII,UTF-16表示非常尴尬。为了解决问题。聪明的 UTF-8出现了,它可以使英文字符的编码与ASCII保持一致,而其它的字符则可能用很多其它字节表示。
这样就不用添加美国人的内存消耗,只是其它国家可能要多牺牲一点内存了。

UTF-8的编码格式
这样中文的每一个字符也无故多用了一个字节,嗯,想想有点浪费。
所以我们也有了自己的编码格式。如GBK。英文字母的编码格式与ASCII保持一致,中文字符採用两字节表示。其他国家的字符就管不了那么多了。只是其他国家基本也都有自己的编码格式。
例如以下所看到的,GBK、Big5、UTF-8、UTF-16四种编码协议定义“中”字的在计算机中的二进制表达为:
GBK Big5 UTF-8 UTF-16 ~xD6xD0 xA4xA4 xE4xB8xAD x2Dx4E