20201201 2020-2021-2 《Python程序设计》实验4报告
课程:《Python程序设计》
班级: 202012
姓名: 张敦敏
学号: 20201201
实验教师:王志强
实验日期:2021年5月24日-2021年6月30日
必修/选修: 公选课
1.实验内容
-
学习如何使用网络爬虫技术
- 通过使用网络爬虫技术实现某一功能
2.实验设计
本次实验计划通过爬取猫眼电影排行来实现对爬虫技术的学习实践。
实验主要分为四步:
- 观察网页的url与HTML
- 分析HTML,写出对应的正则表达式
- 调用requests库,爬取HTML,并使用正则表达式提取对应内容
- 将提取内容整理写入文件
3.实验过程
3.1 观察网页的url与HTML

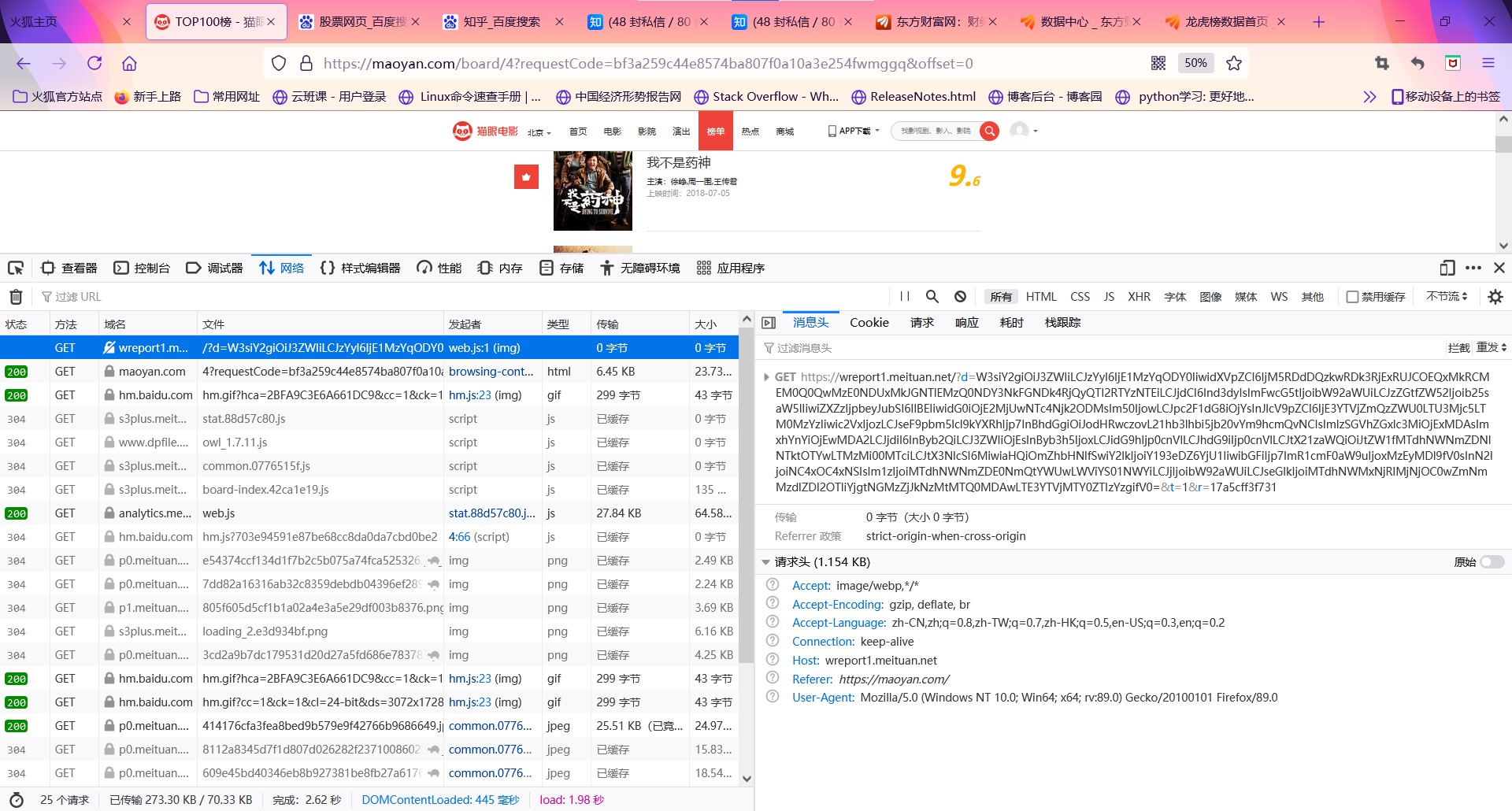
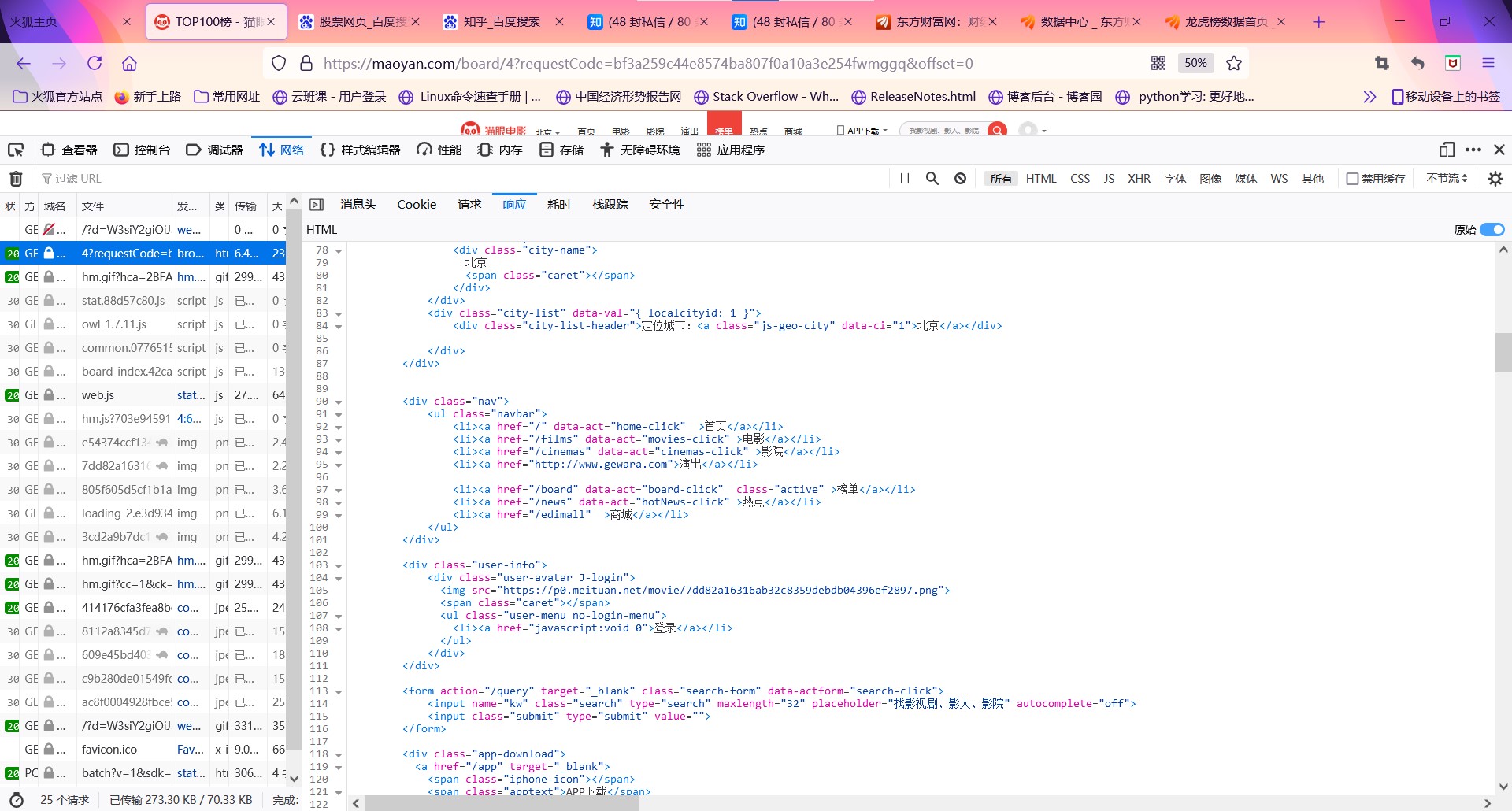
观察得出:
1.猫眼电影排行每页显示10个排名,每页由offset参数控制,每翻一页offset+10
2.HTML中的每一个排名信息放在<dd></dd>中,由其中的不同的class放置其他不同信息
3.2 分析HTML,写出对应的正则表达式
爬取一部分HTML,得到代码:
<dd>
<i class="board-index board-index-2">2</i>
<a href="/films/1297" title="肖申克的救赎" class="image-link" data-act="boarditem-click" data-val="{movieId:1297}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="https://p0.meituan.net/movie/8112a8345d7f1d807d026282f2371008602126.jpg@160w_220h_1e_1c" alt="肖申克的救赎" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/1297" title="肖申克的救赎" data-act="boarditem-click" data-val="{movieId:1297}">肖申克的救赎</a></p>
<p class="star">
主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿
</p>
<p class="releasetime">上映时间:1994-09-10(加拿大)</p> </div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.</i><i class="fraction">5</i></p>
</div>
</div>
</div>
</dd>
这是其中的某一个电影信息的HTML,分析可知它的排名信息是在class为board-index的i节点内,利用非贪婪匹配来提取i节点内的信息,正则表达式可写为: <dd>.*?board-index.*?>(.*?)</i>
随后提取网页图片,其中第二个img节点的data-src属性是图片的链接,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-scr="(.*?)"
然后提取电影名称,在后面的p节点内,class为name。因此将name作为一个标志位,然后提取其中a节点的正文内容,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-scr="(.*?)".*?name.*?a.*?>(.*?)</a>
根据类似原理提取其中的主演、发布时间、评分等内容,最后正则表达式写为:
<dd>.*?board-index.*?>(d+)</i>.*?data-scr="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?interger">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>
3.3 调用requests库,爬取HTML,并使用正则表达式提取对应内容
到了这一步,就需要开始写代码了,为了更加熟练地掌握函数式编程,本次代码编写也通过调用函数来实现。
首先分析要实现的内容应分为几个模块:
1,分页抓取网站的HTML
2,使用正则表达式解析网页
3,将结果写入文件
先写第一个模仿浏览器发出请求的函数:
def get_one_page(url):
try:
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x32; rv:89.0) Gecko/20100101 Firefox/89.0'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
该函数模拟了浏览器消息头的User-Agent信息,而后将响应信息返回。
接下来的是解析网页函数:
def parse_one_page(html):
#pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-scr="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?interger">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
pattern = re.compile('<dd.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?alt="(.*?)"'
'.*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>'
'.*?class="integer">(.*?)</i>.*?class="fraction">(.*?)</i>',re.S)
items = re.findall(pattern, html)
print(items)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'time' : item[4].strip()[5:],
'score': item[5] + item[6]
}
这段代码通过调用re库来实现正则表达式的使用(其中的正则表达式在经过了多次尝试后进行了数次微调),将匹配值整合成字典类型,然后运用yield函数实现迭代返回。
然后是写入文件的操作:
def write_to_file(content):
with open(r"C:Users86153Desktopd.txt","a",encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False)+'
')
f.close()
而后,写出主函数,实现对各个函数的调用:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
最后,整合出整个程序:
from typing import Pattern
import requests
from requests.exceptions import RequestException
import re
import json
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x32; rv:89.0) Gecko/20100101 Firefox/89.0'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
#pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-scr="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?interger">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
pattern = re.compile('<dd.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?alt="(.*?)"'
'.*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>'
'.*?class="integer">(.*?)</i>.*?class="fraction">(.*?)</i>',re.S)
items = re.findall(pattern, html)
print(items)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'time' : item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open(r"C:Users86153Desktopd.txt","a",encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False)+'
')
f.close()
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
offset=i*10
main(offset)
time.sleep(1)
f = open(r"C:Users86153Desktopd.txt","r",encoding='utf-8')
f1 = open(r"C:Users86153Desktope.txt","a",encoding='utf-8')
for i in range(100):
d = eval(f.readline())
f1.write("排名:"+d.get('index')+'
')
f1.write("图片网址:"+d.get('image')+'
')
f1.write("电影名称:"+d.get('title')+'
')
f1.write("主演:"+d.get('actor')+'
')
f1.write("上映时间:"+d.get('time')+'
')
f1.write("电影评分:"+d.get('score')+'
')
f.close()
f1.close()
在这里设置offset值的变化,并且设置延时1秒,防止过快发送消息导致无响应。
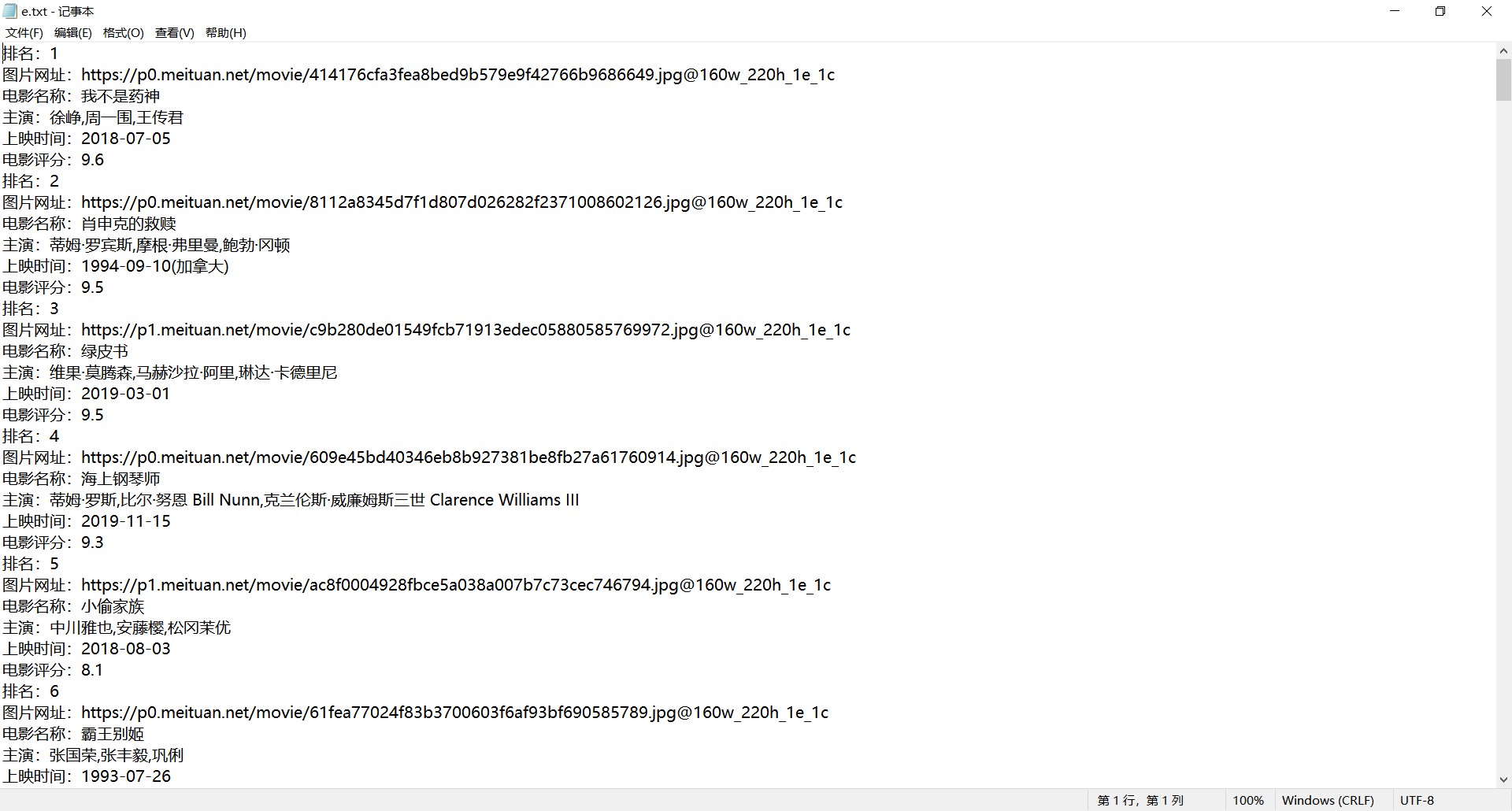
4. 实验结果
代码初步调试结果:

代码最终调试结果:

5. 实验过程中遇到的问题和解决过程
问题:猫眼电影网的反爬虫如何解决?
问题解决:每次访问时都更改自身消息头的User-Agent信息即可。
6. 实验体会
在这次实验中,我练习了正则表达式与python的requests库、re库、json库的基本使用,基本掌握了最基础的使用,明确了爬虫程序编写的一个基本思路。
本次实验代码已上传至gitee add 实验四. · c4dc525 · ZDM/python学习 - Gitee.com