前言
ThreadLocal的文章在网上也有不少,但是看了一些后,理解起来总感觉有绕,而且看了ThreadLocal的源码,无论是线程隔离、类环形数组、弱引用结构等等,实在是太有意思了!我必须也要让大家全面感受下其中所蕴含的那些奇思妙想! 所以这里我想写一篇超几儿通俗易懂解析ThreadLocal的文章,相关流程会使用大量图示解析,以证明:我是干货,不是水比!
ThreadLocal这个类加上庞大的注释,总共也才七百多行,而且你把这个类的代码拷贝出来,你会发现,它几乎没有报错!耦合度极低!(唯一的报错是因为ThreadLocal类引用了Thread类里的一个包内可见变量,所以把代码复制出来,这个变量访问就报错了,仅仅只有此处报错!)
ThreadLocal的线程数据隔离,替换算法,擦除算法,都是有必要去了解了解,仅仅少量的代码,却能实现如此精妙的功能,让我们来体会下 Josh Bloch 和 Doug Lea 俩位大神,巧夺天工之作吧!
一些说明
这篇文章画了不少图,大概画了十八张图,关于替换算法和擦除算法,这俩个方法所做的事情,如果不画图,光用文字描述的话,十分的抽象且很难描述清楚;希望这些流程图,能让大家更能体会这些精炼代码的魅力!
使用
哔哔原理之前,必须要先来看下使用
- 使用起来出奇的简单,仅仅使用
set()和get()方法即可
public class Main {
public static void main(String[] args) {
ThreadLocal<String> threadLocalOne = new ThreadLocal<>();
ThreadLocal<String> threadLocalTwo = new ThreadLocal<>();
new Thread(new Runnable() {
@Override
public void run() {
threadLocalOne.set("线程一的数据 --- threadLocalOne");
threadLocalTwo.set("线程一的数据 --- threadLocalTwo");
System.out.println(threadLocalOne.get());
System.out.println(threadLocalTwo.get());
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(threadLocalOne.get());
System.out.println(threadLocalTwo.get());
threadLocalOne.set("线程二的数据 --- threadLocalOne");
threadLocalTwo.set("线程二的数据 --- threadLocalTwo");
System.out.println(threadLocalOne.get());
System.out.println(threadLocalTwo.get());
}
}).start();
}
}
- 打印结果
- 一般来说,我们在主存(或称工作线程)创建一个变量;在子线程中修改了该变量数据,子线程结束的时候,会将修改的数据同步到主存的该变量上
- 但是,在此处,可以发现,俩个线程都使用同一个变量,但是在线程一里面设置的数据,完全没影响到线程二
- cool!简单易用,还实现了数据隔离与不同的线程
线程一的数据 --- threadLocalOne
线程一的数据 --- threadLocalTwo
null
null
线程二的数据 --- threadLocalOne
线程二的数据 --- threadLocalTwo
前置知识
在解释ThreadLocal整体逻辑前,需要先了解几个前置知识
下面这些前置知识,是在说set和get前,必须要先了解的知识点,了解下面这些知识点,才能更好去了解整个存取流程
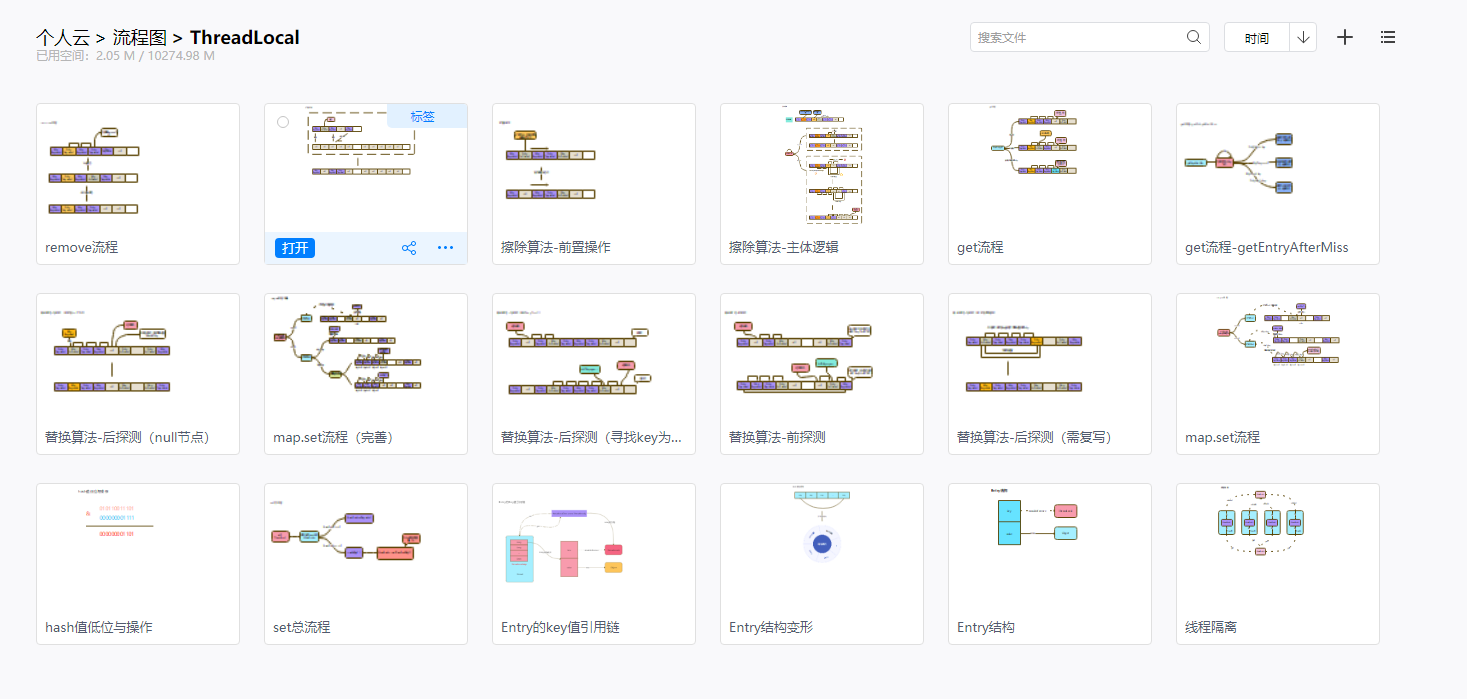
线程隔离
在上面的ThreadLocal的使用中,我们发现一个很有趣的事情,ThreadLocal在不同的线程,好像能够存储不同的数据:就好像ThreadLocal本身具有存储功能,到了不同线程,能够生成不同的'副本'存储数据一样
实际上,ThreadLocal到底是怎么做到的呢?
- 来看下set()方法,看看到底怎么存数据的:此处涉及到ThreadLocalMap类型,暂且把他当成Map,详细的后面栏目分析
- 其实这地方做了一个很有意思的操作:线程数据隔离的操作,是Thread类和ThreadLocal类相互配合做到的
- 在下面的代码中可以看出来,在塞数据的时候,会获取执行该操作的当前线程
- 拿到当前线程,取到threadLocals变量,然后仿佛以当前实例为key,数据value的形式往这个map里面塞值(有区别,set栏目再详细说)
- 所以使用ThreadLocal在不同的线程中进行写操作,实际上数据都是绑定在当前线程的实例上,ThreadLocal只负责读写操作,并不负责保存数据,这就解释了,为什么ThreadLocal的set数据,只在操作的线程中有用
- 大家有没有感觉这种思路有些巧妙!
//存数据
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocal.ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
//获取当前Thread的threadLocals变量
ThreadLocal.ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
//Thread类
public class Thread implements Runnable {
...
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
...
}
- 来看下图示
- 图上只花了了一个ThreadLocal,想多花几个,然后线交叉了,晕
- threadLocals是可以存储多个ThreadLocal,多个存取流程同理如下
- 总结下:通过上面的很简单的代码,就实现了线程的数据隔离,也能得到几点结论
- ThreadLocal对象本身是不储存数据的,它本身的职能是执行相关的set、get之类的操作
- 当前线程的实例,负责存储ThreadLocal的set操作传入的数据,其数据和当前线程的实例绑定
- 一个ThreadLocal实例,在一个线程中只能储存一类数据,后期的set操作,会覆盖之前set的数据
- 线程中threadLocals是数组结构,能储存多个不同ThreadLocal实例set的数据
Entry
- 说到Entry,需要先知道下四大引用的基础知识
强引用:不管内存多么紧张,gc永不回收强引用的对象
软引用:当内存不足,gc对软引用对象进行回收
弱引用:gc发现弱引用,就会立刻回收弱引用对象
虚引用:在任何时候都可能被垃圾回收器回收
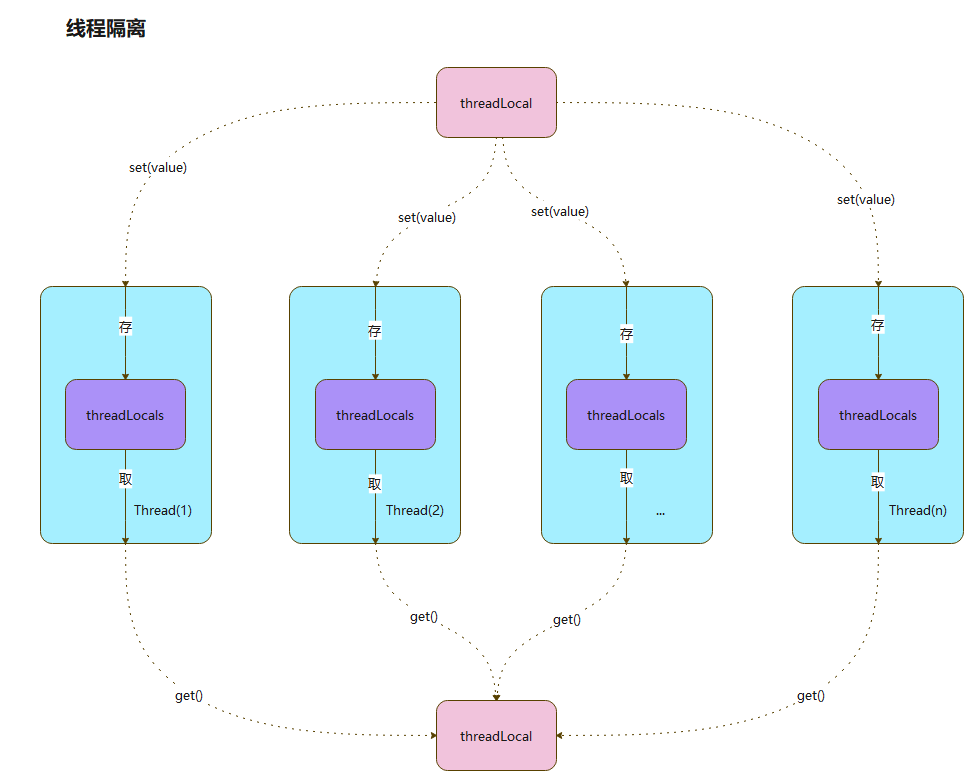
Entry就是一个实体类,这个实体类有俩个属性:key、value,key是就是咱们常说的的弱引用
当我们执行ThreadLocal的set操作,第一次则新建一个Entry或后续set则覆盖改Entry的value,塞到当前Thread的ThreadLocals变量中
- 来看下Entry代码
- 此处key取得是ThreadLocal自身的实例,可以看出来Entry持有的key属性,属于弱引用属性
- value就是我们传入的数据:类型取决于我们定义的泛型
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
- Entry有个比较巧妙的结构,继承弱引用类,然后自身内部又定义了一个强引用属性,使得该类有一强一弱的属性
- 结构图
你可能会想,what?我用ThreadLocal来set一个数据,然后gc一下,我Entry里面key变量引用链就断开了?

- 来试一下
public class Main {
public static void main(String[] args) {
ThreadLocal<String> threadLocalOne = new ThreadLocal<>();
new Thread(new Runnable() {
@Override
public void run() {
threadLocalOne.set("线程一的数据 --- threadLocalOne");
System.gc();
System.out.println(threadLocalOne.get());
}
}).start();
}
}
- 结果
线程一的数据 --- threadLocalOne
看来这里gc了个寂寞。。。
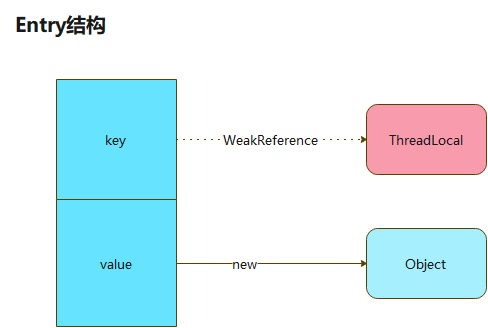
在这里,必须明确一个道理:gc回收弱引用对象,是先回收弱引用的对象,弱引用链自然断开;而不是先断开引用链,再回收对象。Entry里面key对ThreadLocal的引用是弱引用,但是threadLocalOne对ThreadLocal的引用是强引用啊,所以ThreadLocal这个对象是没法被回收的
- 来看下上面代码真正的引用关系
- 此处可以演示下,threadLocalOne对ThreadLocal的引用链断开,Entry里面key引用被gc回收的情况
public class Main {
static ThreadLocal<String> threadLocalOne = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
threadLocalOne.set("线程一的数据 --- threadLocalOne");
try {
threadLocalOne = null;
System.gc();
//下面代码来自:https://blog.csdn.net/thewindkee/article/details/103726942
Thread t = Thread.currentThread();
Class<? extends Thread> clz = t.getClass();
Field field = clz.getDeclaredField("threadLocals");
field.setAccessible(true);
Object threadLocalMap = field.get(t);
Class<?> tlmClass = threadLocalMap.getClass();
Field tableField = tlmClass.getDeclaredField("table");
tableField.setAccessible(true);
Object[] arr = (Object[]) tableField.get(threadLocalMap);
for (Object o : arr) {
if (o == null) continue;
Class<?> entryClass = o.getClass();
Field valueField = entryClass.getDeclaredField("value");
Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent");
valueField.setAccessible(true);
referenceField.setAccessible(true);
System.out.println(String.format("弱引用key:%s 值:%s", referenceField.get(o), valueField.get(o)));
}
} catch (Exception e) { }
}
}).start();
}
}
- 结果
- key为null了!上面有行代码:threadLocalOne = null,这个就是断开了对ThreadLocal对象的强引用
- 大家如果有兴趣的话,可以把threadLocalOne = null去掉,再运行的话,会发现,key不会为空
- 反射代码的功能就是取到Thread中threadLocals变量,循环取其中的Entry,打印Entry的key、value值
弱引用key:null 值:线程一的数据 --- threadLocalOne
弱引用key:java.lang.ThreadLocal@387567b2 值:java.lang.ref.SoftReference@2021fb3f
- 总结
- 大家心里可能会想,这变量一直持有强引用,key那个弱引用可有可无啊,而且子线程代码执行时间一般也不长
- 其实不然,我们可以想想Android app里面的主线程,就是一个死循环,以事件为驱动,里面可以搞巨多巨难的逻辑,这个强引用的变量被赋其它值就很可能了
- 如果key是强引用,那么这个Entry里面的ThreadLocal基本就很难被回收
- key为弱引用,当ThreadLocal对象强引用链断开后,其很容易被回收了,相关清除算法,也能很容易清理key为null的Entry
- 一个弱引用都能玩出这么多花样

ThreadLocalMap环形结构
- 咱们来看下ThreadLocalMap代码
- 先去掉一堆暂时没必要关注的代码
- table就是ThreadLocalMap的主要结构了,数据都存在这个数组里面
- 所以说,ThreadLocalMap的主体结构就是一个Entry类型的数组
public class ThreadLocal<T> {
...
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
...
}
}
- 在此处你可能又有疑问了,这东西不就是一个数组吗?怎么和环形结构扯上关系了?

- 数组正常情况下确实是下面的这种结构

- 但是,ThreadLocalMap类里面,有个方法做了一个骚操作,看下代码
public class ThreadLocal<T> {
...
static class ThreadLocalMap {
...
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
...
}
}
- 这个nextIndex方法,大家看懂了没?
- 它的主要作用,就是将传入index值加一
- 但是!当index值长度超过数组长度后,会直接返回0,又回到了数组头部,这就完成了一个环形结构
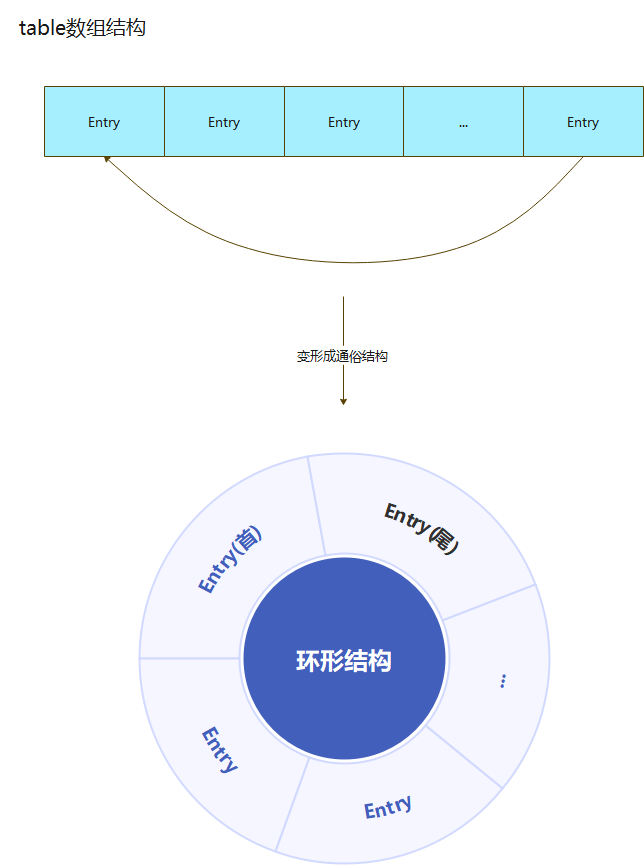
- 总结
- 这样做有个很大的好处,能够大大的节省内存的开销,能够充分的利用数组的空间
- 取数据的时候会降低一些效率,时间置换空间
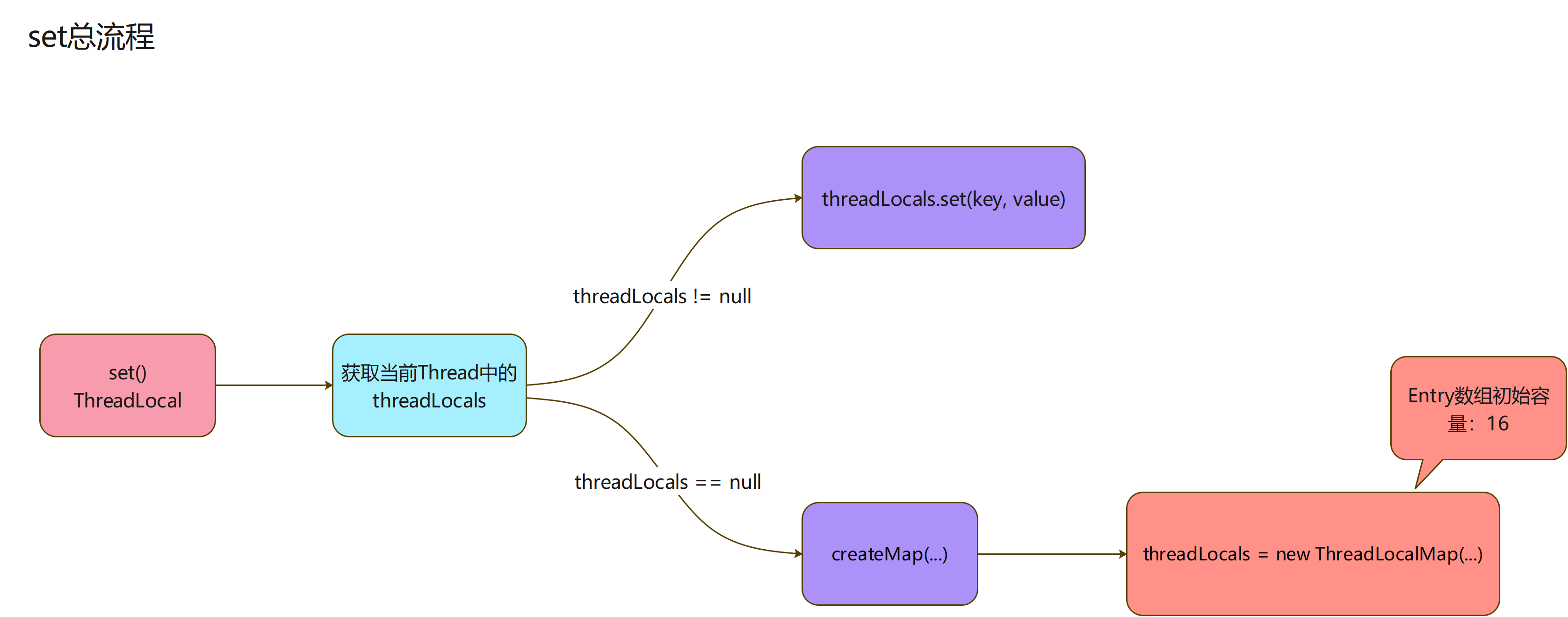
set
总流程
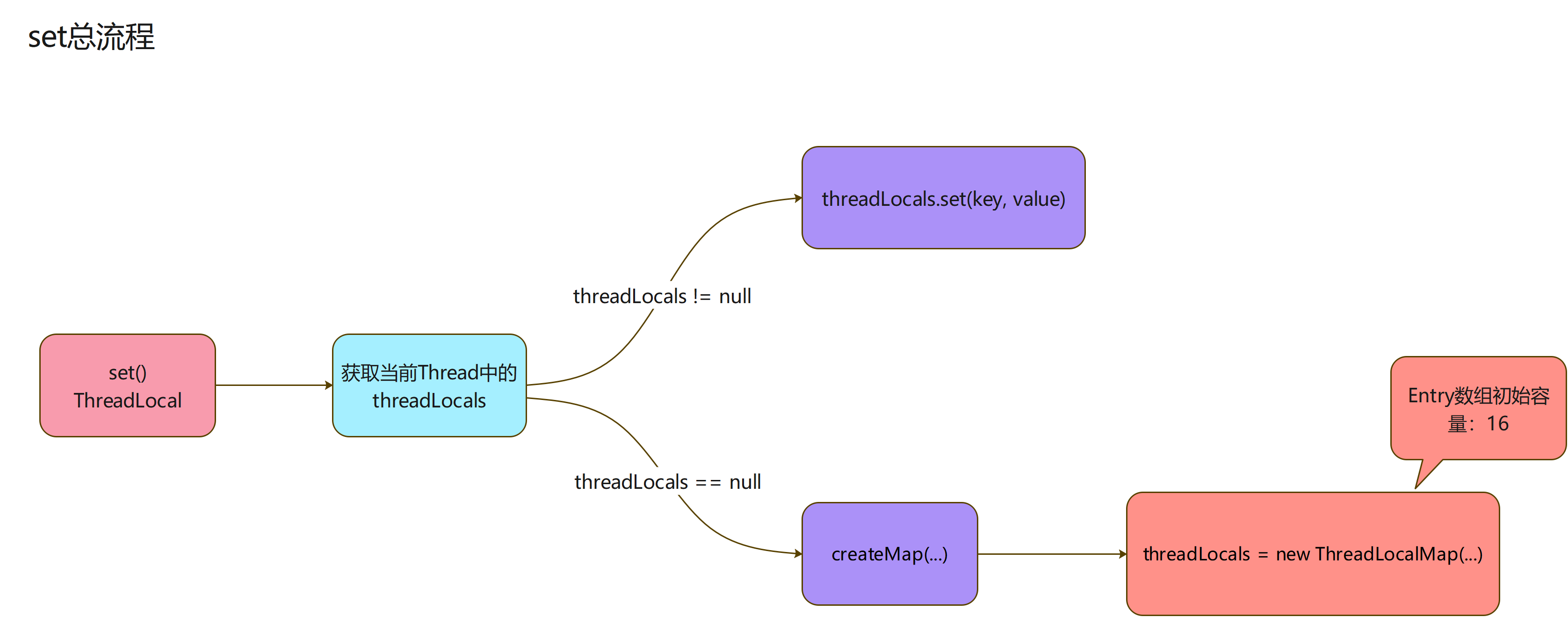
- 塞数据的操作,来看下这个set操作的代码:下面的代码,逻辑还是很简单的
- 获取当前线程实例
- 获取当前线程中的threadLocals实例
- threadLocals不为空执行塞值操作
- threadLocals为空,new一个ThreadLocalMap赋值给threadLocals,同时塞入一个Entry
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
- 需要注意的是,ThreadLocalMap生成Entry数组,设置了一个默认长度,默认为:16
private static final int INITIAL_CAPACITY = 16;
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
...
}
- 流程图
map.set
- 上面说了一些细枝末节,现在来说说最重要的map.set(this, value) 方法
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
取哈希值
- 上面代码有个计算哈希值的操作
- 从key.threadLocalHashCode这行代码上来看,就好像将自身的实例计算hash值
- 其实看了完整的代码,发现传入key,只不过是为了调用nextHashCode方法,用它来计算哈希值,并不是将当前ThreadLocal对象转化成hash值
public class ThreadLocal<T> {
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
private static AtomicInteger nextHashCode = new AtomicInteger();
private void set(ThreadLocal<?> key, Object value) {
...
int i = key.threadLocalHashCode & (len-1);
...
}
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
}
- 这地方用了一个原子类的操作,来看下getAndAdd() 方法的作用
- 这就是个相加的功能,相加后返回原来的旧值,保证相加的操作是个原子性不可分割的操作
public class Main {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger();
System.out.println(atomicInteger.getAndAdd(1)); //0
System.out.println(atomicInteger.getAndAdd(1)); //1
System.out.println(atomicInteger.getAndAdd(1)); //2
}
}
- HASH_INCREMENT = 0x61c88647,为什么偏偏将将0x61c88647这个十六进制相加呢,为什么不能是1,2,3,4,5,6呢?
该值的相加,符合斐波那契散列法,可以使得的低位的二进制数值分布的更加均匀,这样会减少在数组中产生hash冲突的次数
具体分析可查看:从 ThreadLocal 的实现看散列算法
等等大家有没有看到 threadLocalHashCode = nextHashCode(),nextHashCode()是获取下一个节点的方法啊,这是什么鬼?
难道每次使用key.threadLocalHashCode的时候,HashCode都会变?
- 看下完整的赋值语句
- 这是在初始化变量的时候,就直接定义赋值的
- 说明实例化该类的时候,nextHashCode()获取一次HashCode之后,就不会再次获取了
- 加上用的final修饰,仅能赋值一次
- 所以threadLocalHashCode变量,在实例化ThreadLocal的时候,获取HashCode一次,该数值就定下来了,在该实例中就不会再变动了
public class ThreadLocal<T> {
private final int threadLocalHashCode = nextHashCode();
}
好像又发现一个问题!threadHashCode通过 nextHashCode() 获取HashCode,然后nextHashCode是使用AtomicInteger类型的 nextHashCode变量相加,这玩意每次实例化的时候不都会归零吗?
难道我们每次新的ThreadLocal实例获取HashCode的时候,都要从0开始相加?
- 来看下完整代码
- 大家看下AtomicInteger类型的nextHashCode变量,他的修饰关键字是static
- 这说明该变量的数值,是和这个类绑定的,和这个类生成的实例无关,而且从始至终,只会实例化一次
- 当不同的ThreadLocal实例调用nextHashCode,他的数值就会相加一次
- 而且每个实例只能调用一次nextHashCode()方法,nextHashCode数值会很均匀的变化
public class ThreadLocal<T> {
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
private static AtomicInteger nextHashCode = new AtomicInteger();
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
}
总结
- 通过寥寥数行的初始化,几个关键字,就能形成在不同实例中,都能稳步变化的HashCode数值
- 这些基础知识大家或许都知道,又有多少能这样信手拈来呢?

取index值
上面代码中,用取得的hash值,与ThreadLocalMap实例中数组长度减一的与操作,计算出了index值
这个很重要的,因为大于长度的高位hash值是不需要的
此处会将传入的ThreadLocal实例计算出一个hash值,怎么计算的后面再说,这地方有个位与的操作,这地方是和长度减一的与操作,这个很重要的,因为大于长度的高位hash值是不需要的
- 假设hash值为:010110011101
- 长度(此处选择默认值:16-1):01111
- 看下图可知,这个与操作,可去掉高位无用的hash值,取到的index值可限制在数组长度中

塞值
- 看下塞值进入ThreadLocalMap数组的操作
- 关于Key:因为Entry是继承的WeakReference类,get()方法是获取其内部弱引用对象,所以可以通过get()拿到当前ThreadLocal实例
- 关于value:直接 .value 就OK了
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
...
}
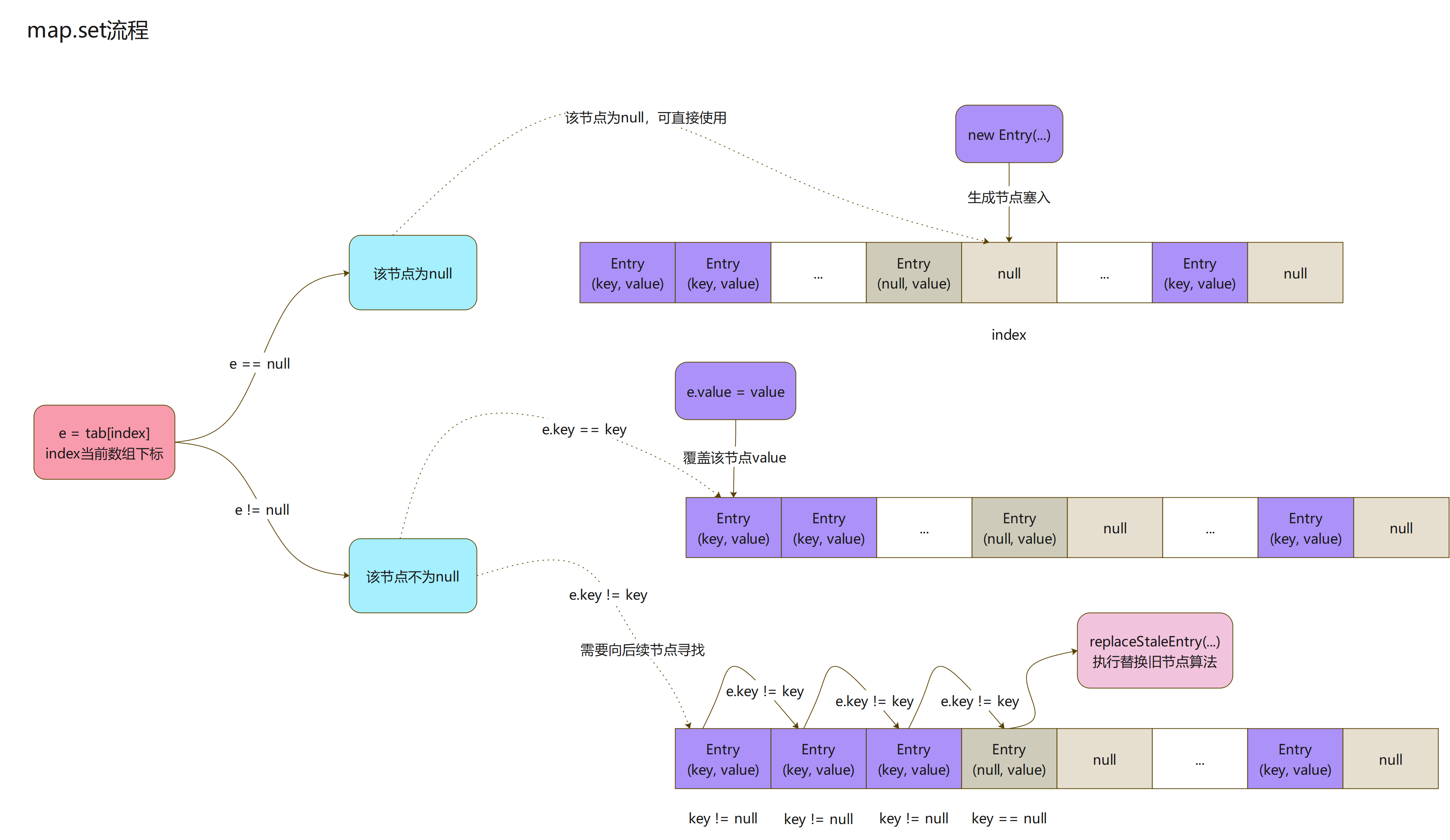
分析下塞值流程
-
实际上面的循环还值得去思考,来思考下这循环处理的事情
-
循环中获取当前index值,从Entry数组取到当前index位置的Entry对象
- 如果获取的这Entry是null,则直接结束这个循环体
- 在Entry数组的index塞入一个新生成的节点
- 如果获取的这Entry不为null
- key值相等,说明Entry对象存在,覆盖其value值即可
- key为null,说明该节点可被替换(替换算法后面讲),new一个Entry对象,在此节点存储数据
- 如果key不相等且不为null,循环获取下一节点的Entry对象,并重复上述逻辑
整体的逻辑比较清晰,如果key已存在,则覆盖;不存在,index位置是否可用,可用则使用该节点,不可用,往后寻找可用节点:线性探测法
- 替换旧节点的逻辑,实在有点绕,下面单独提出来说明
替换算法
在上述set方法中,当生成的index节点,已被占用,会向后探测可用节点
- 探测的节点为null,则会直接使用该节点
- 探测的节点key值相同,则会覆盖value值
- 探测的节点key值不相同,继续向后探测
- 探测的节点key值为null,会执行一个替换旧节点的操作,逻辑有点绕,下面来分析下
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
...
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
...
}
- 来看下replaceStaleEntry方法中的逻辑
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// Back up to check for prior stale entry in current run.
// We clean out whole runs at a time to avoid continual
// incremental rehashing due to garbage collector freeing
// up refs in bunches (i.e., whenever the collector runs).
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// Find either the key or trailing null slot of run, whichever
// occurs first
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// If we find key, then we need to swap it
// with the stale entry to maintain hash table order.
// The newly stale slot, or any other stale slot
// encountered above it, can then be sent to expungeStaleEntry
// to remove or rehash all of the other entries in run.
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
-
上面的代码,很明显俩个循环是重点逻辑,这里面有俩个很重要的字段:slotToExpunge和staleSlot
- staleSlot:记录传进来节点key为null的位置
- slotToExpunge:标定是否需要执行最后的清理方法
-
第一个循环:很明显是往前列表头结点方向探测,是否还有key为null的节点,有的话将其下标赋值给slotToExpunge;这个探测是一个连续的不为null的节点链范围,有空节点,立马结束循环

-
第二个循环:很明显主要是向后探测,探测整个数组,这里有很重要逻辑
- 这地方已经开始有点绕了,我giao,大家要好好想想
- 当探测的key和传入的需要设值的key相同时,会复写探测到Entry的value,然后将探测到位置和传入位置,俩者相互调换
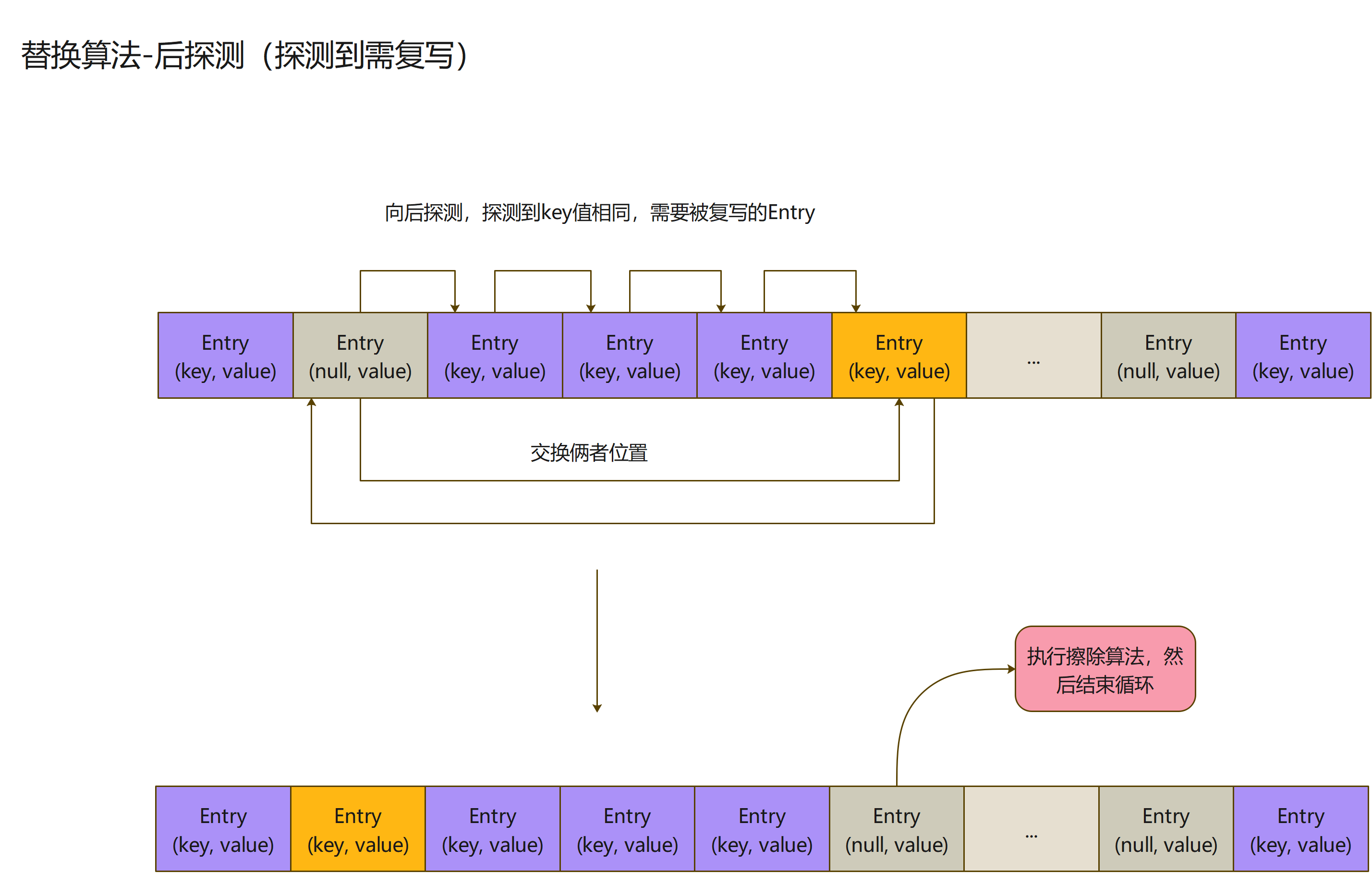
-
为什么会出现探测到Entry和传入key相同?
- 相同是因为,存在到数组的时候,产生了hash冲突,会自动向后探测合适的位置存储
- 当你第二次用ThreadLocal存值的时候,hash产生的index,比较俩者key,肯定是不可能相同,因为产生了hash冲突,真正储存Entry,在往后的位置;所以需要向后探测
- 假设探测的时候,一直没有遇到key为null的Entry:正常循环的话,肯定是能探测到key相同的Entry,然后进行复写value的操作
- 但是在探测的时候,遇到key为null的Entry的呢?此时就进入了替换旧Entry算法,所以替换算法就也有了一个向后探测的逻辑
- 探测到相同key值的Entry,就说明了找到了我们需要复写value的Entry实例
-
为什么要调换俩者位置呢?
-
这个问题,大家可以好好想想,我们时候往后探测,而这key为null的Entry实例,属于较快的探测到Entry
-
而这个Entry实例的key又为null,说明这个Entry可以被回收了,此时正处于占着茅坑不拉屎的位置
-
此时就可以把我需要复写Entry实例和这个key为null的Entry调换位置
-
可以使得我们需要被操作的Entry实例,在下次被操作时候,可以尽快被找到
-
-
调换了位置之后,就会执行擦除旧节点算法
- 上面是探查连续的Entry节点,未碰到null节点的情况;如果碰到null节点,会直接结束探测
- 请注意,如果数组中,有需要复写value的节点;在计算的hash值处,向后探测的过程,一定不会碰到null节点
- 毕竟,第一次向后探测可用节点是,碰到第一个null节点,就停下来使用了
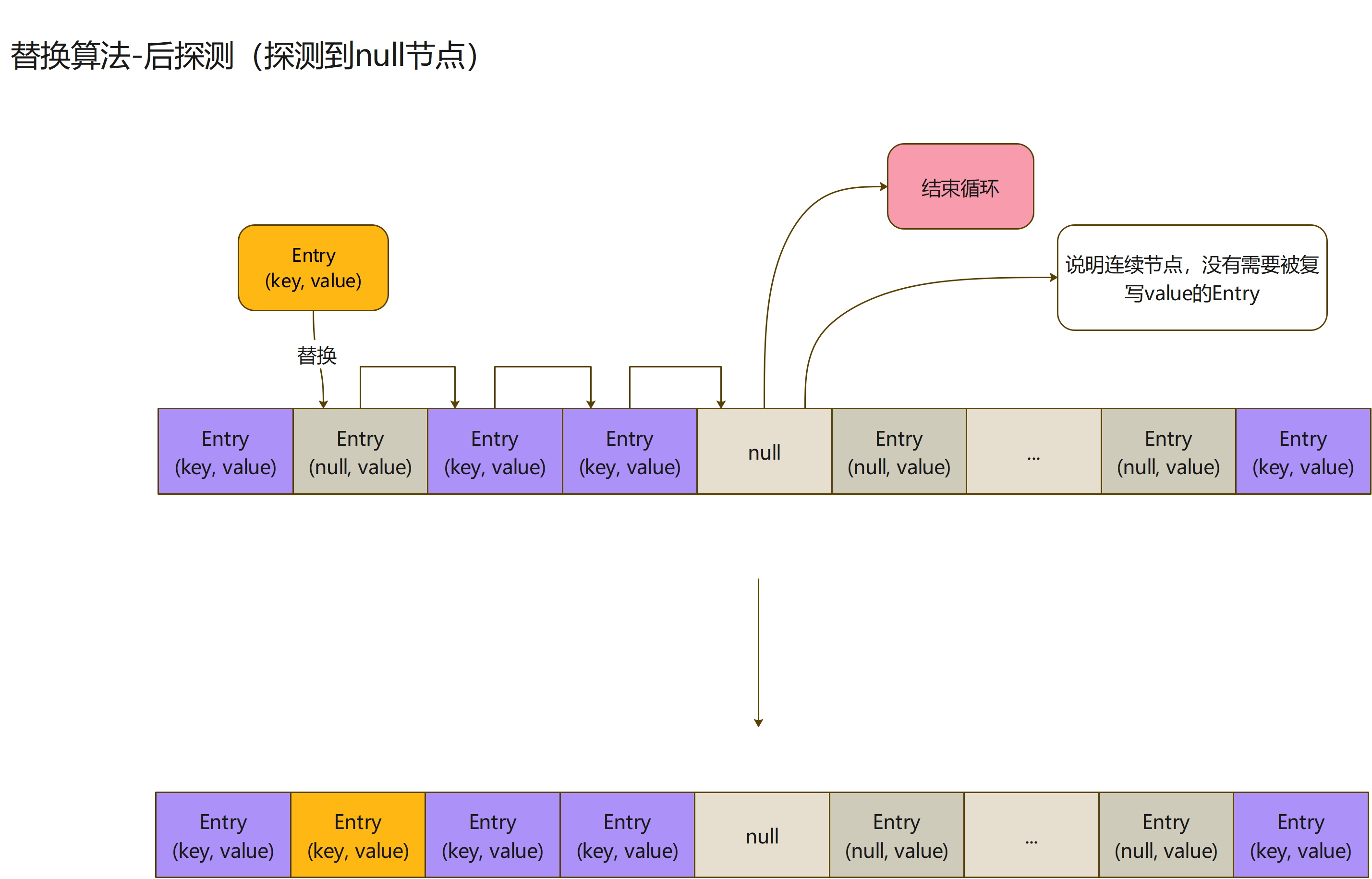
- 在第二个循环中,还有一段代码,比较有意思,这判断逻辑的作用是
- 以key为null的Entry,以它为界限
- 向前探测的时候,未碰到key为null的Entry
- 而向后探测的时候,碰到的key为null的Entry
- 然后改变slotToExpunge的值,使其和staleSlot不相等
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
...
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
...
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
...
}
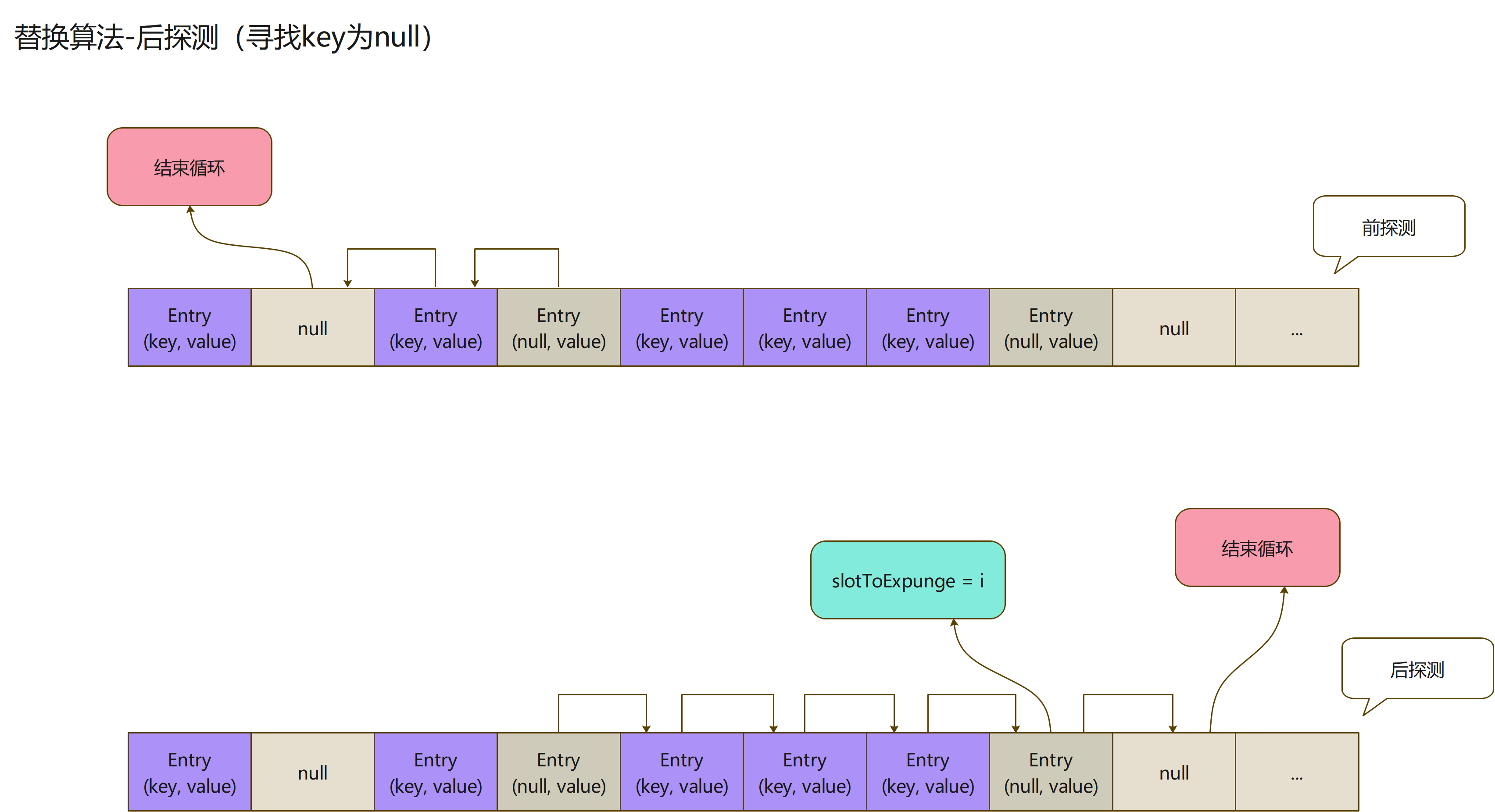
- 可以看出来这俩个循环的操作,是有关联性,对此,我表示

为什么这俩个循环都这么执着的,想改变slotToExpunge的数值呢?
- 来看下关于slotToExpunge的关键代码
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
...
int slotToExpunge = staleSlot;
...
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
明白了吧!都是为了替换方法里面的最后一段逻辑:为了判断是否需要执行擦除算法
总结
-
双向探测流程
- 替换算法会以传入的key为null的Entry节点为界限,在一个连续的Entry范围往俩边探测
- 什么是连续的Entry范围?这边数组的节点都不能为null,碰到为null节点会结束探测
- 先向前探测:如果碰到key为null的Entry,会将其下标赋值给slotToExpunge
- 向后探测使:如果向前探测没有碰到key的节点,只要向后探测的时候碰到为null的节点,会将其下标赋值给slotToExpunge
- 上面向俩边探测的逻辑,是为了:遇到key为null的节点,能确保slotToExpunge不等于staleSlot
- 替换算法会以传入的key为null的Entry节点为界限,在一个连续的Entry范围往俩边探测
-
在向后探测的时候,如果遇到key值对比相同的Entry,说明遇到我们需要复写value的Entry
- 此时复写value的Entry,用我们传入的value数值将其原来的value数值覆盖
- 然后将传入key为null的Entry(通过传入的下标得知Entry)和需要复写value的Entry交换位置
- 最后执行擦除算法
-
如果在向后探测的时候,没有遇到遇到key值对比相同的Entry
- 传入key为null的Entry,将其value赋值为null,断开引用
- 创建一个新节点,放到此位置,key为传入当前ThreadLocal实例,value为传入的value数据
- 然后根据lotToExpunge和staleSlot是否相等,来判断是否要执行擦除算法
总结
来总结下
- 再来看下总流程
- 上面分析完了替换旧节点方法逻辑,终于可以把map.set的那块替换算法操作流程补起来了
- 不管后续遇到null,还是遇到需要被复写value的Entry,这个key为null的Entry都将被替换掉
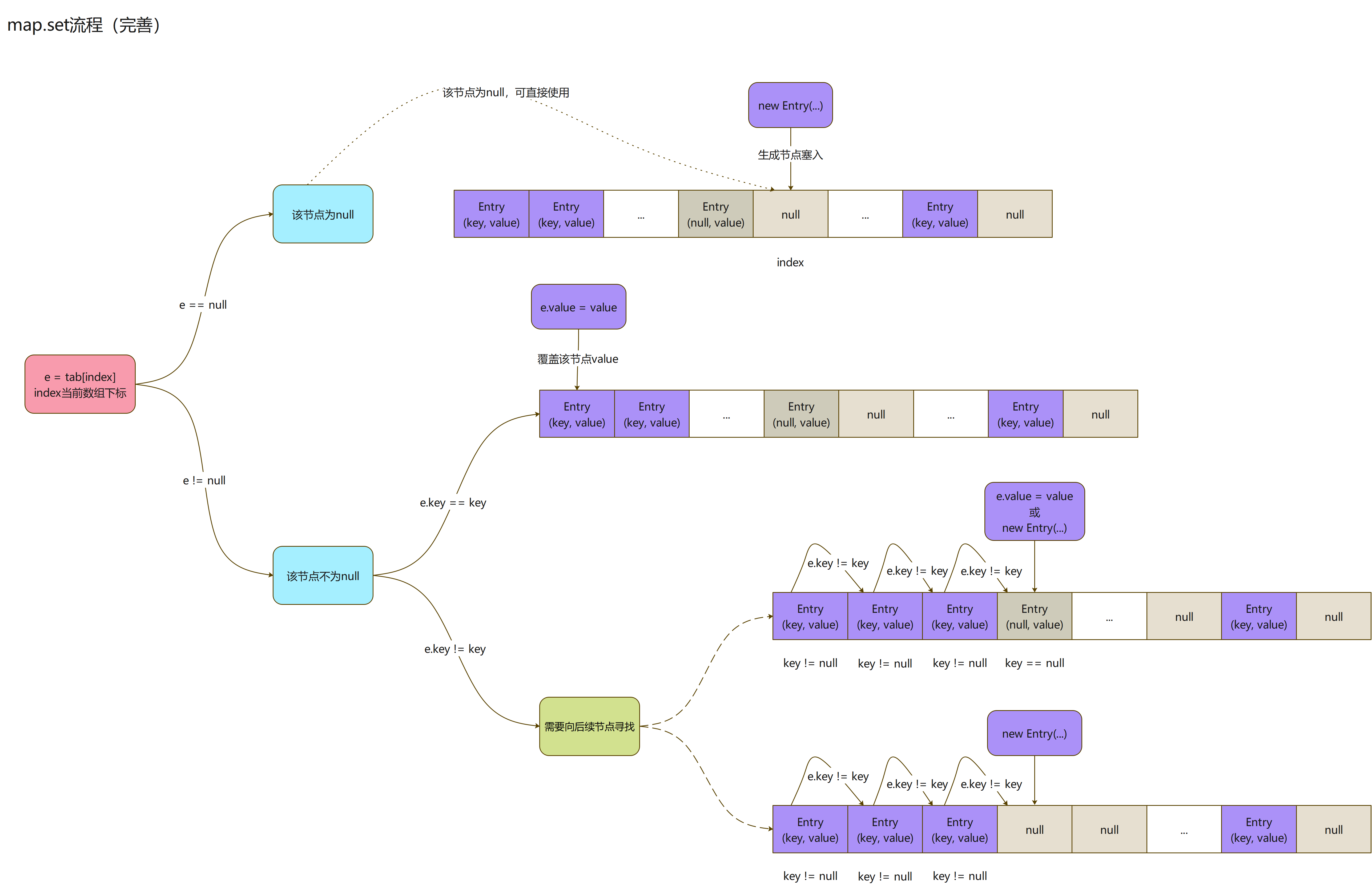
这俩个图示,大概描述了ThreadLocal进行set操作的整个流程;现在,进入下一个栏目吧,来看看ThreadLocal的get操作!
get
get流程,总体要比set流程简单很多,可以轻松一下了
总流程
- 来看下代码
- 总体流程非常简单,将自身作为key,传入map.getEntry方法,获取符合实例的Entry,然后拿到value,返回就行了
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
- 如果通过map.getEntry获取的Entry为null,会返回setInitialValue(),来看下这个方法是干嘛的
- 从这个方法可知,如果我们没有进行set操作,直接进行get操作,他会给ThreadLocal的threadLocals方法赋初值
- setInitialValue() 方法,返回的是initialValue() 方法的数据,可知默认为null
- 所以通过key没查到对应的Entry,get方法会返回null
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
protected T initialValue() {
return null;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
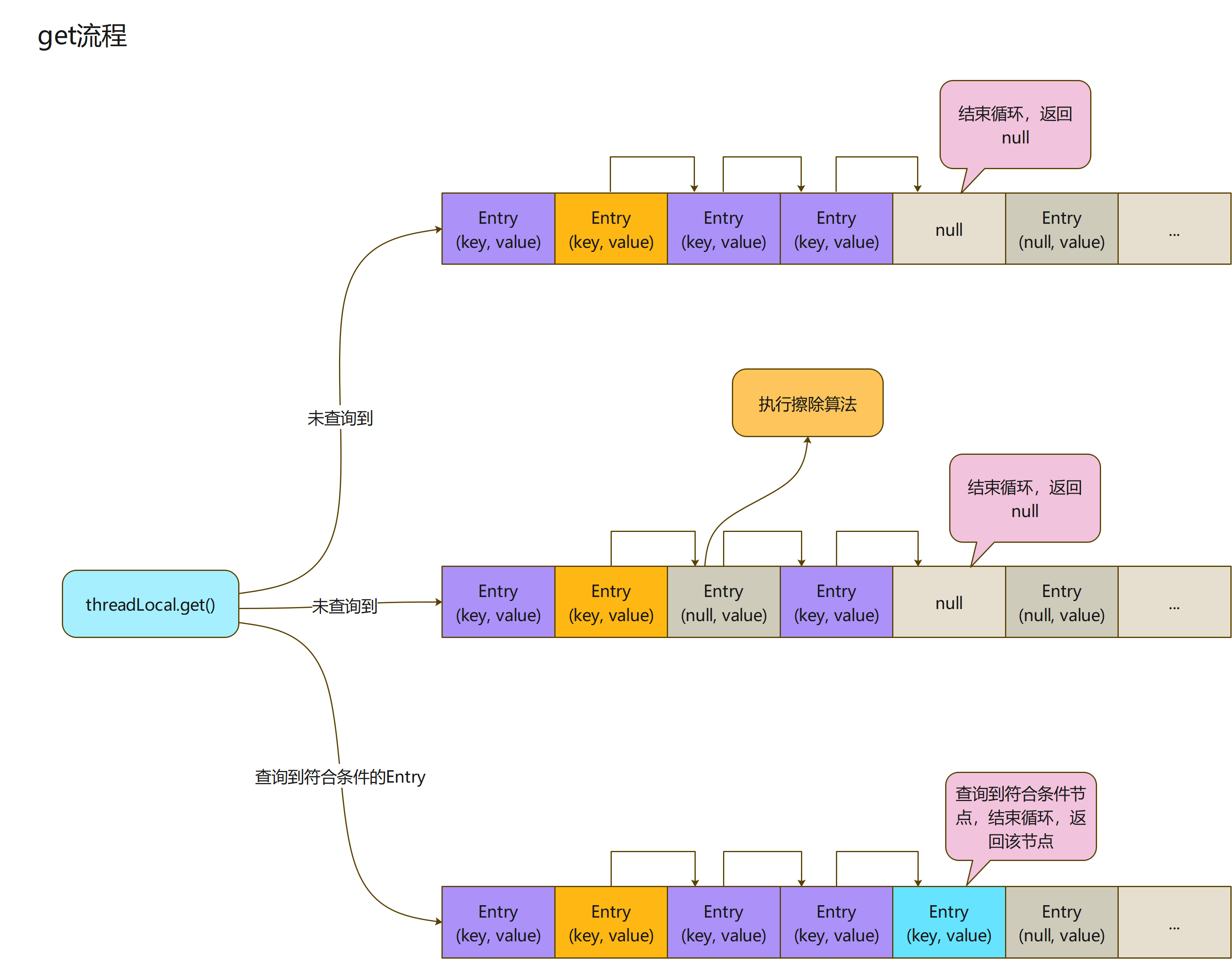
map.getEntry
- 从上面的代码可以看出来,getEntry方法是获取符合条件的节点
- 这里逻辑很简单,通过当前ThreadLocal实例获取HashCode,然后算出index值
- 直接获取当前index下标的Entry,将其key和当前ThreadLocal实例对比,看是否一样
- 相同:说明没有发生Hash碰撞,可以直接使用
- 不相同:说明发生了Hash碰撞,需要向后探测寻找,执行getEntryAfterMiss()方法
- 此时,就需要来看看getEntryAfterMiss()方法逻辑了
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
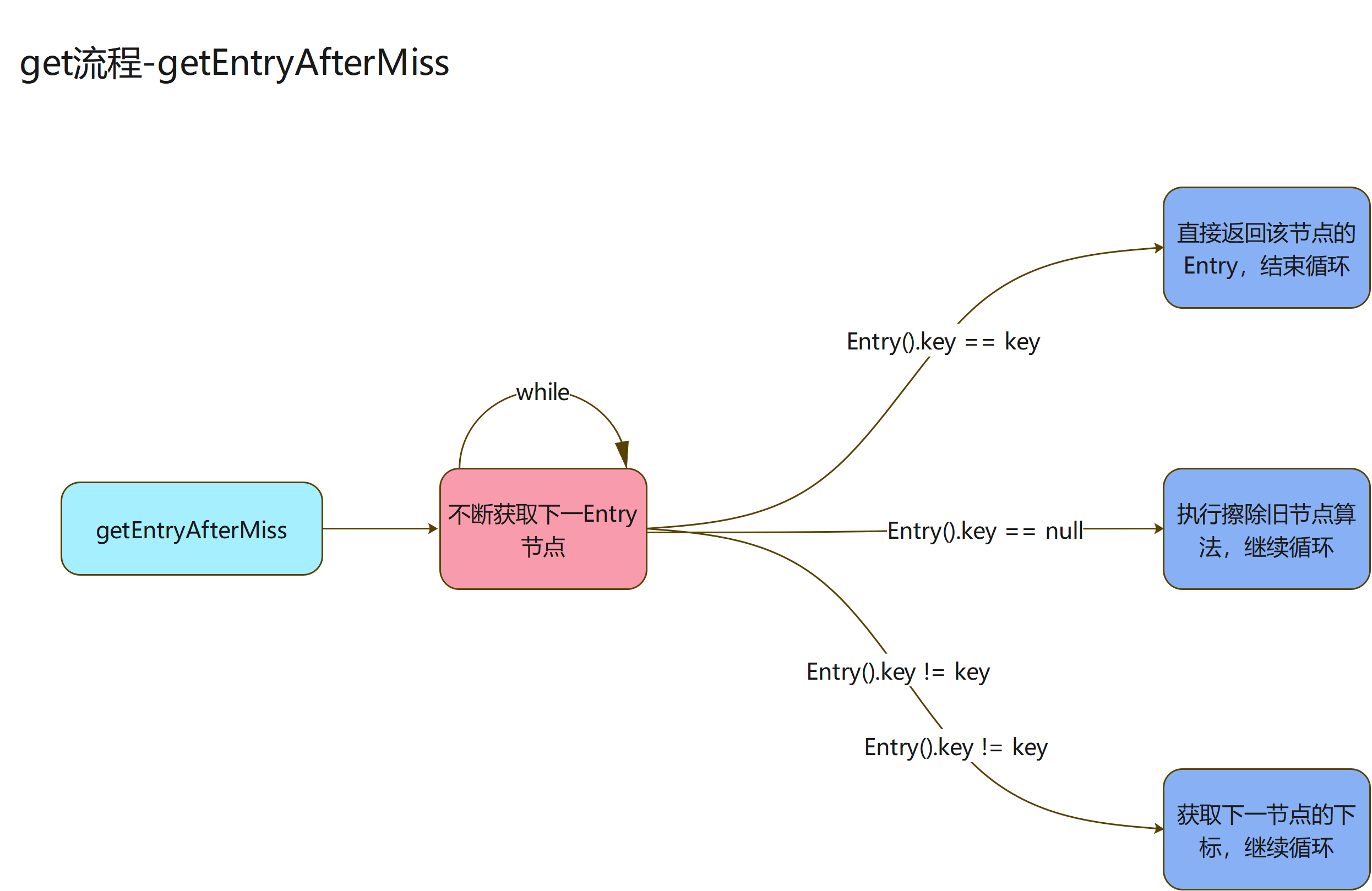
getEntryAfterMiss
- 来看下代码
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
整体逻辑还是很清晰了,通过while循环,不断获取Entry数组中的下一个节点,循环中有三个逻辑走向
- 当前节点的key等于当前ThreadLocal实例:直接返回这个节点的Entry
- 当前节点的key为null:执行擦除旧节点算法,继续循环
- 当前节点的可以不等于当前ThreadLocal实例且不为null:获取下一节点的下标,然后继续上面的逻辑
- 如果没有获取到符合条件的Entry节点,会直接返回null
总结
ThreadLocal的流程,总体上比较简单
-
将当前ThreadLocal实例当为key,查找Entry数组当前节点(使用ThreadLocal中的魔术值算出的index)是否符合条件
-
不符合条件将返回null
- 从未进行过set操作
- 未查到符合条件的key
-
符合条件就直接返回当前节点
- 如果遇到哈希冲突,算出的index值的Entry数组上存在Entry,但是key不相等,就向后查找
- 如果遇到key为null的Entry,就执行擦除算法,然后继续往后寻找
- 如果遇到key相当的Entry,就直接结束寻找,返回这个Entry节点
-
这里大家一定要明确一个概念:在set的流程,发生了hash冲突,是在冲突节点向后的连续节点上,找到符合条件的节点存储,所以查询的时候,只需要在连续的节点上查找,如果碰到为null的节点,就可以直接结束查找
擦除算法
在set流程和get流程都使用了这个擦除旧节点的逻辑,它可以及时清除掉Entry数组中,那些key为null的Entry,如果key为null,说明这些这节点,已经没地方使用了,所以就需要清除掉
- 来看看这个方法代码
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
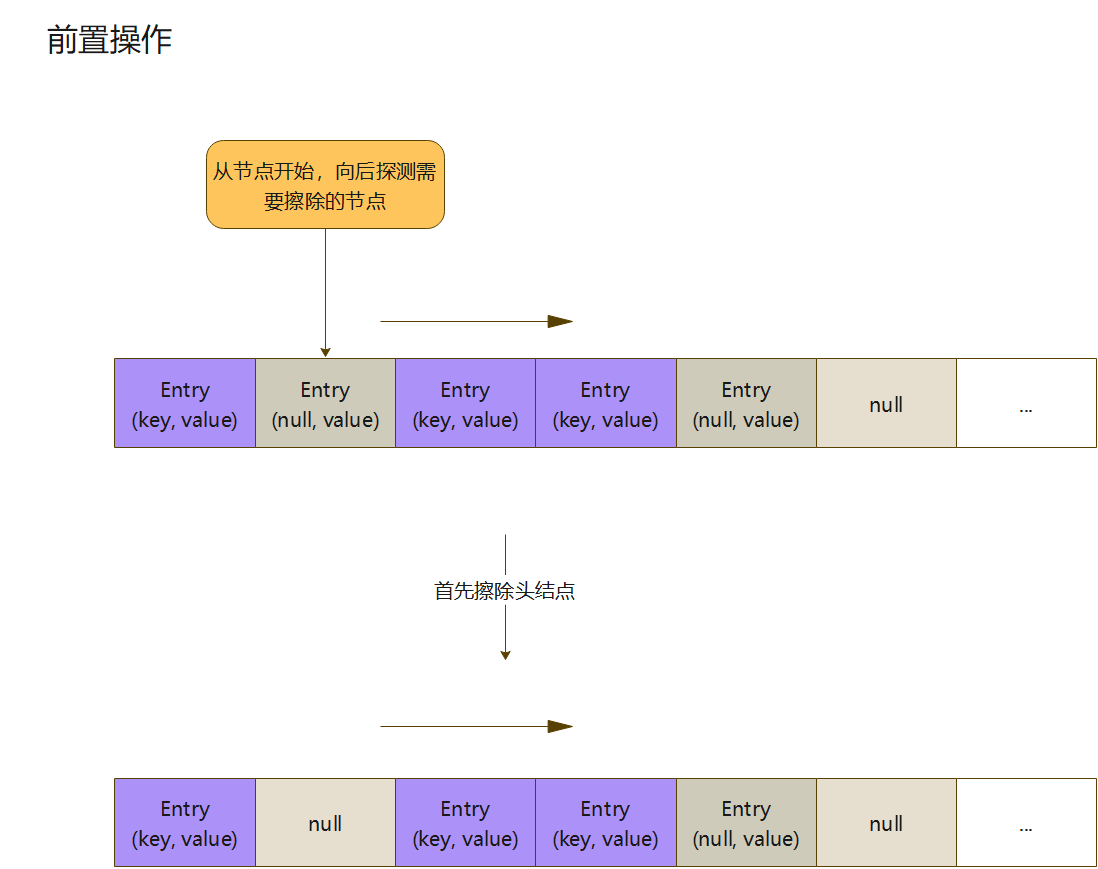
前置操作
从上面的代码,可以发现,再进行主要的循环体,有个前置操作
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
...
}
- 这地方做了很简单的置空操作,如果Entry节点的key为空,说明这个节点可以被清除,value置空,和数组的链接断开
主体逻辑
- 很明显,循环体里面的逻辑是最重要,而且循环体里面做了一个相当有趣的操作!
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
...
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
- 上面的循环体里面,就是不断的获取下一节点的Entry实例,然后判断key值进行相关处理
- key为null:中规中矩的,将value置空,断开与数组的链接
- key不为null:这时候就有意思了
- 首先,会获取当前ThreadLocal实例的hash值,然后取得index值
- 判断h(idnex值)和i是否相等,不相等进行下述操作,因为Entry数组是环形结构,是完成存在相等的情况
- 会将当前循环到节点置空,该节点的Entry记为e
- 从通过hreadLocal实例的hash值获取到index处,开始进行循环
- 循环到节点Entry为null,则结束循环
- 将e赋值给为null的节点
- 这里面的逻辑就是关键了
- 大家可能对这个文字的描述,感觉比较抽象,来个图,来体会下这短短几行代码的妙处

总结
代码很少,但是实现的功能却并不少
- 擦除旧节点的方法,在Entry上探测的时候
- 遇到key为空的节点,会将该节点置空
- 遇到key不为空的节点,会将该节点移到靠前位置(具体移动逻辑,请参考上述说明)
- 交互到靠前节点位置,可以看出,主要的目的,是为了:
- ThreadLocal实例计算出的index节点位置往后的位置,能让节点保持连续性
- 也能让交换的节点,更快的被操作
扩容
在进行set操作的时候,会进行相关的扩容操作
- 来看下扩容代码入口:resize方法便是扩容方法
public void set(T value) {
...
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
private void set(ThreadLocal<?> key, Object value) {
...
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
- 来看下扩容代码
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
触发条件
先来看下扩容的触发条件吧
- 整体代码
public void set(T value) {
...
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
private void set(ThreadLocal<?> key, Object value) {
...
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
上面主要的代码就是:!cleanSomeSlots(i, sz) && sz >= threshold
- 来看下threshold是什么
- 只要Entry数组含有Entry实例大于等于数组的长度的三分之二,便能满足后一段判定
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
- 来看看前一段的判定,看下cleanSomeSlots,只要返回false,就能触发扩容方法了
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
n >>>= 1:表达是无符号右移一位,正数高位补0,负数高位补1
举例:0011 ---> 0001
在上面的cleanSomeSlots方法中,只要在探测节点的时候,没有遇到Entry的key为null的节点,该方法就会返回false
- rehash方法就非常简单了
- 执行擦除方法
- 只要size(含有Entry实例数)长度大于等于3/4 threshold,就执行扩容操作
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
总结
满足下面俩个条件即可
- Entry数组中不含key为null的Entry实例
- 数组中含有是实例数大于等于threshold的四分之三(threshold为数组长度的 三分之二)
扩容逻辑
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
-
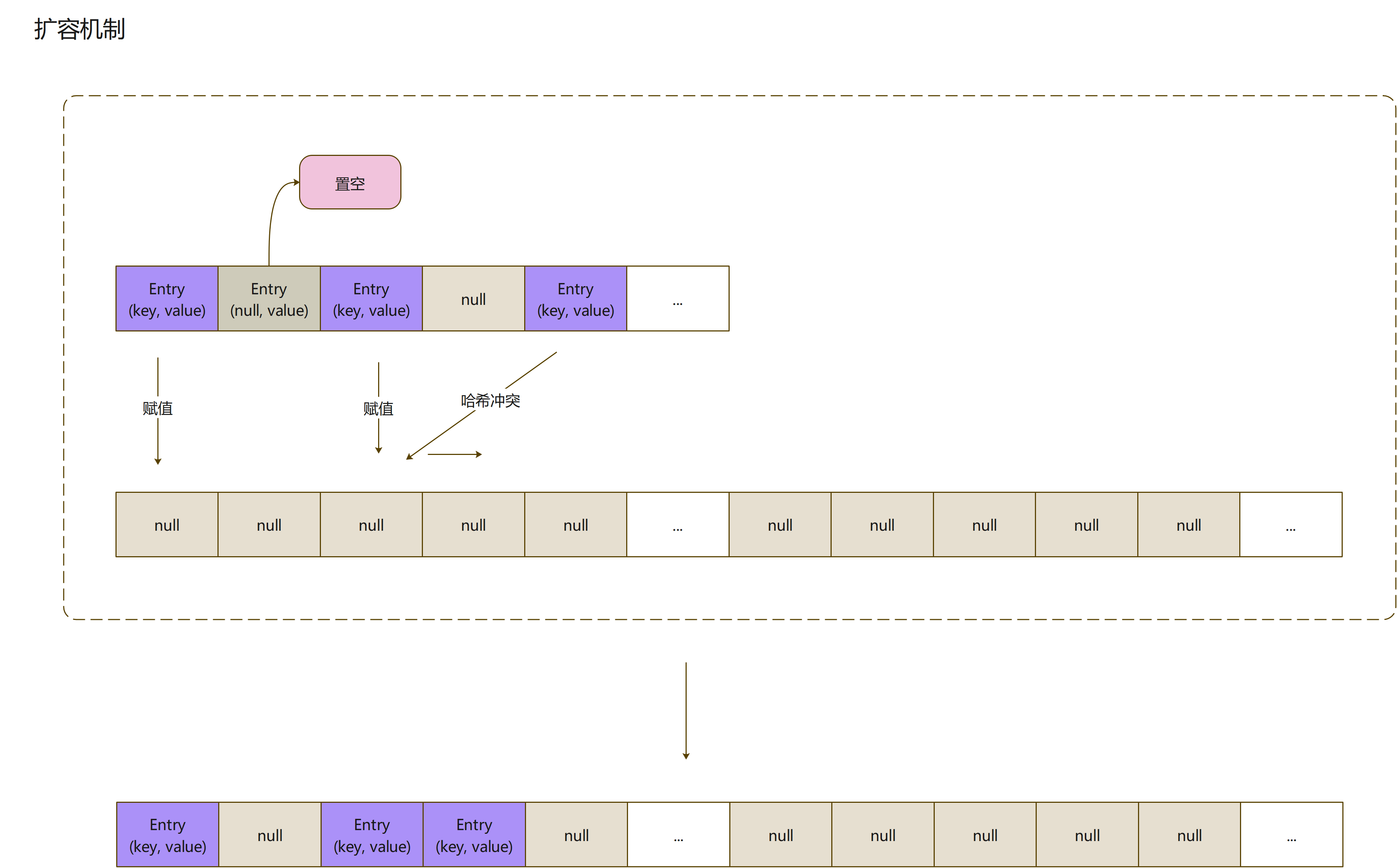
从上面的逻辑,可以看出来,将旧数组的数据赋值到扩容数组,并不是全盘赋值到扩容数组的对应位置
-
遍历旧数组,取出其中的Entry实例
- key为null:需要将该节点value置空,等待GC处理(Help the GC,hhhh)
- 这里你可能有个疑问,不是说数组的节点key不为null,才会触发扩容机制吗?
- 在多线程的环境里,执行扩容的时候,key的强引用断开,导致key被回收,从而key为null,这是完全存在的
- key不为null:算出index值,向扩容数组中存储,如果该节点冲突,向后找到为null的节点,然后存储
- key为null:需要将该节点value置空,等待GC处理(Help the GC,hhhh)
-
这里的扩容存储和ArrayList之类是有区别
总结
可以发现
-
set,替换,擦除,扩容,基本无时无刻,都是为了使hash冲突节点,向冲突的节点靠近
-
这是为了提高读写节点的效率
remove
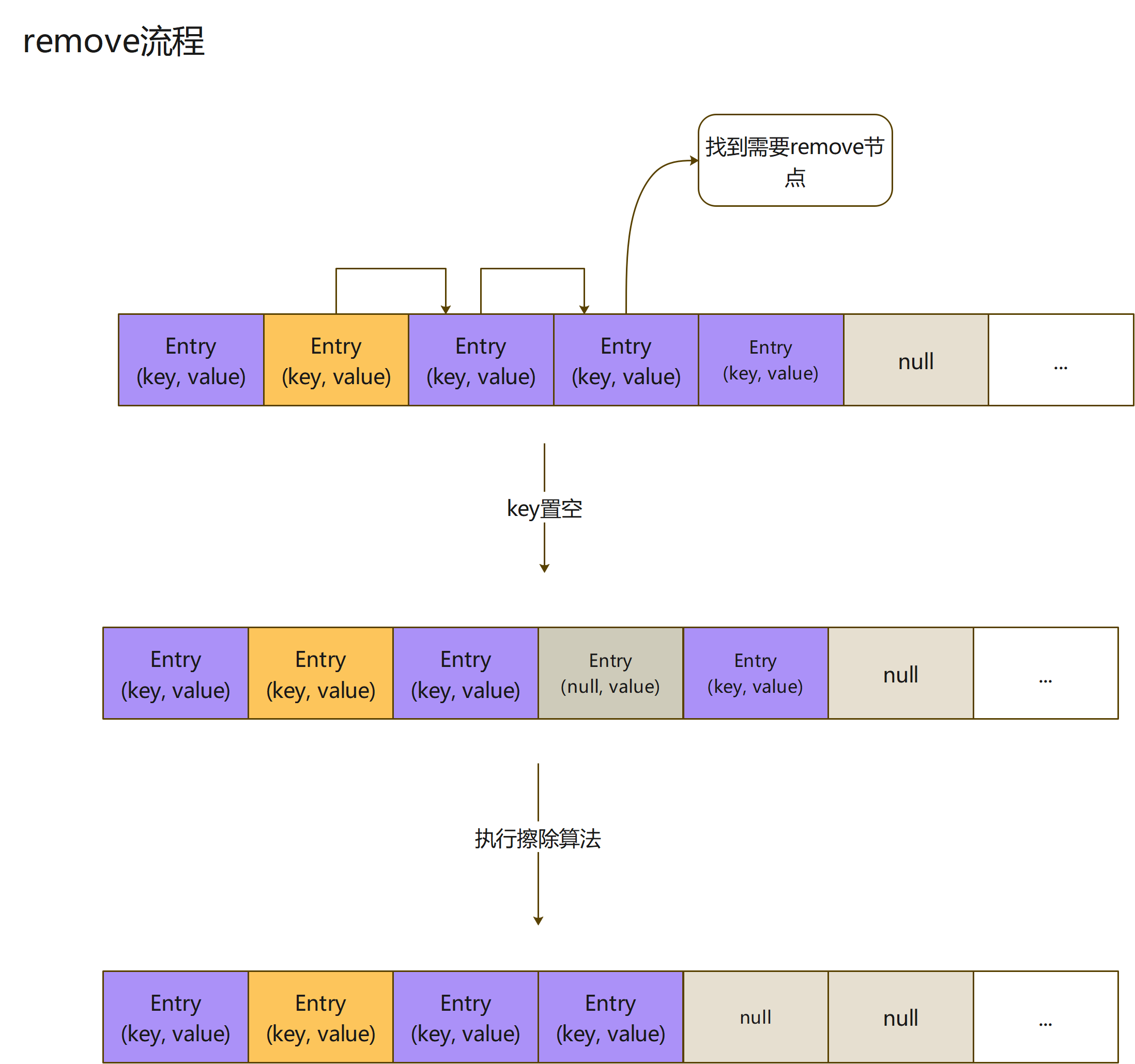
remove方法是非常简单的,ThreadLocal拥有三个api:set、get、remove;虽然非常简单,但是还有一些必要,来稍微了解下
- remove代码
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
逻辑非常的清晰,通过ThreadLocal实例,获取当前的index,然后从此开始查找符合条件Entry,找到后,会将其key值清掉,然后执行擦除算法
e.clear就是,弱引用的清理弱引用的方法,很简单,将弱引用referent变量置空就行了,这个变量就是持有弱引用对象的变量
最后
文章写到这里,基本上到了尾声了,写了差不多万余字,希望大家看完后,对ThreadLocal能有个更加深入的认识
ThreadLocal的源码虽然并不多,但是其中有很多奇思妙想,有种萝卜雕花的感觉,这就是高手写的代码吗?
系列文章