文章目录
1. Hadoop 集群简介
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群
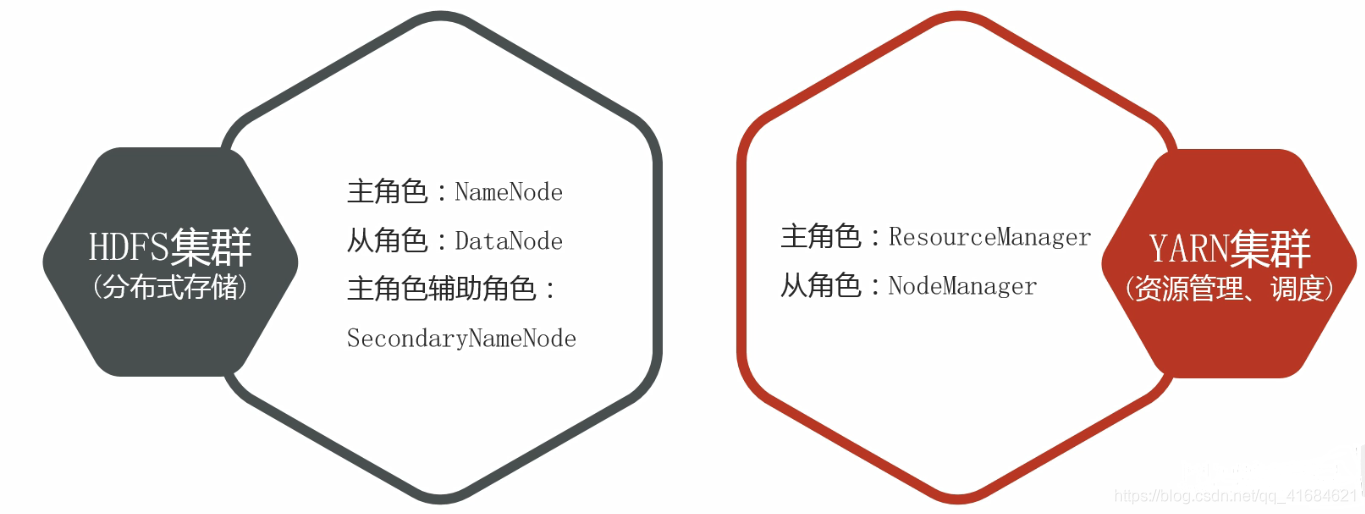

- 逻辑上分离
两个集群互相之间没有依赖、互不影响 - 物理上在一起
某些角色进程往往部署在同一台物理服务器上 - MapReduce集群呢?
MapReduce是计算框架、代码层面的组件没有集群之说

2. Hadoop 部暑模式

3. Hadoop 源码编译
- 安装包、源码包下载地址
https://hadoop.apache.org/releases.html

- 随便选择一个镜像地址下载,第一个是北京外国语大学的镜像地址,第二个是清华大学的
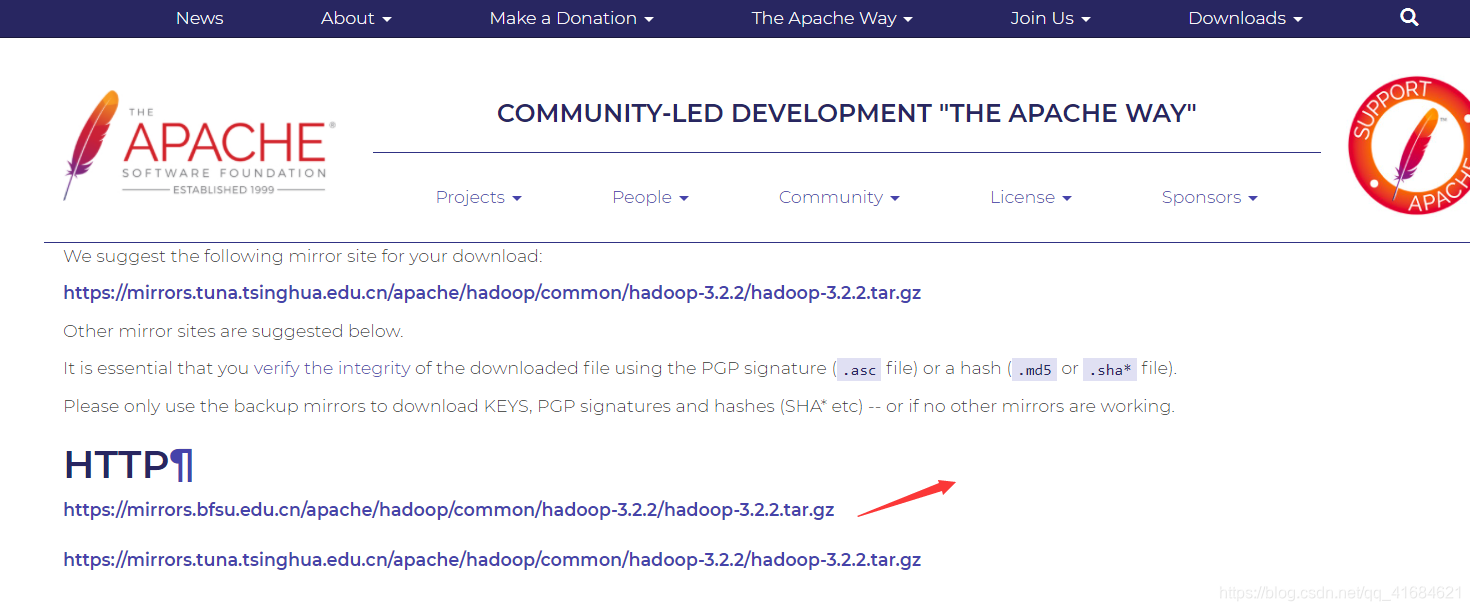
- 如果想下载其他比较早的版本,点击

https://archive.apache.org/dist/hadoop/common/,这里包含所有发布的版本

- 为什么要重新编译Hadoop源码?
匹配不同操作系统本地库环境,Hadoop某些操作比如压缩、IO 需要调用系统本地库(*.so|*.dll)
修改源码、重构源码 - 如何编译Hadoop
源码包根目录下文件:BUILDING.txt

- 这里使用Hadoop3.1.4安装包,可以去官网下载
4. Hadoop 集群安装
step1:集群角色规划
- 角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上? - 角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起

Step2:服务器基础环境准备
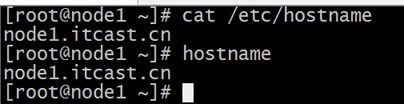
- 主机名(3台机器)
vim /etc/hostname
- Hosts映射(3台机器)|
vim /etc/hosts

- 防火墙关闭(3台机器)
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙开启自启
- ssh免密登录(
node1执行->node1|node2|node3)
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
- 检验:

- 集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com

- JDK 1.8安装(3台机器)

Step3:上传安装包、解压安装包
- 创建统一工作目录(3台机器),自定义创建,自己可以划分
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径

- 上传、解压安装包(node1)
tar -zxvf hadoop-3.2.2 -C /export/server/
-C :表示指定安装路径
Step4:Hadoop安装包目录结构

Step5:编辑Hadoop配置文件(1)
- 打开Hadoop根目录下的
etc/hadoop-env.sh文件
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim hadoop-env.sh
- 配置 JDK 环境可以访问我之前写的博文:关于Linux服务器配置java环境遇到的问题
- 指定安装JDK的根目录,配置 JAVA_HOME
export JAVA_HOME=/export/server/jdk1.8.0_65
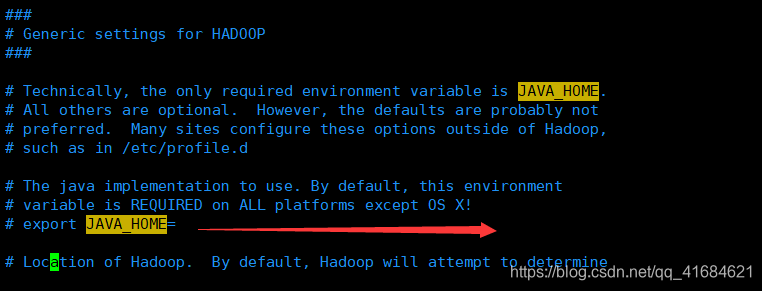
- 在文件末尾加上如下命令,设置用户以执行对应角色shell命令
#设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Step5:编辑Hadoop配置文件(2)
- 还是在Hadoop的根目录下的
etc下配置core-site.xml,在<configuration>下添加如下代码 - 注意:下面的域名要改成自己主机对应的
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1.xdr630.com:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
Step5:编辑Hadoop配置文件(3)
- 配置
hdfs-site.xml,在在<configuration>下添加
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2.xdr630.com:9868</value>
</property>
Step5:编辑Hadoop配置文件(4)
- 配置
mapred-site.xml,添加
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
Step5:编辑Hadoop配置文件(5)
- 配置
yarn-site.xml,添加
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1.xdr630.com</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
Step5:编辑Hadoop配置文件(6)
- 配置 workers ,添加
node1.xdr630.com
node2.xdr630.com
node3.xdr630.com
Step6:分发同步安装包
- 在node1机器上将Hadoop安装包scp同步到其他机器
cd /export/server/
scp -r hadoop-3.1.4 root@node2:/usr/local/
scp -r hadoop-3.1.4 root@node3:/usr/local/
Step7:配置Hadoop环境变量
- 在node1上配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 将修改后的环境变量同步其他机器
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
- 重新加载环境变量 验证是否生效(3台机器)
source /etc/profile
hadoop #验证环境变量是否生效
5. 总结
- 服务器基础环境
- Hadoop源码编译
- Hadoop配置文件修改
- shell文件、4个xml文件、workers文件
- 配置文件集群同步