一、函数
什么是函数?
类似一个封装体,它是组织好的,可重复使用的,实现相关功能的代码段
函数的特性有:减少重复代码;使程序变的可拓展;使程序变的易维护
二、定义函数
语法:
def 函数名(参数1,参数2,参数3,...): #函数名要见名思意
'''注释'''
函数体
return 返回的值
三、函数的调用
1.调用函数
格式:函数名()
def star():
print("you are beautiful girl")
star()
2.函数返回值
函数在执行过程中只要遇到return语句,就会停止执行并返回结果
如果未在函数中指定return,那这个函数的返回值为None
什么时候函数需要返回值,什么时候函数不需要返回值?
通常有参函数需要有返回值,通常无参函数不需要有返回值
四、函数的参数
形参
1.位置参数必须传值
1 def func(a, b):
2 the_max = a if a > b else b #三元运算
3 return the_max
4 res = func(3, 5)
5 print(res)
2.默认参数(不传值就会显示默认的值)
1 def people(name, sex="男"):
2 print(name,sex)
3 people("xfxing")
4 people("alex", "gay")
实参
1.按位置传值
2.按关键字传参
3.混合传参 关键字参数永远在位置参数之后
def my_sum(x, y):
return x + y
num1 = my_sum(10, 20) # 位置参数
num2 = my_sum(x=20, y=99) # 关键字传参
num3 = my_sum(1, y=88) # 1--位置参数,y=88--关键字参数
print(num1, num2,num3)
动态传参
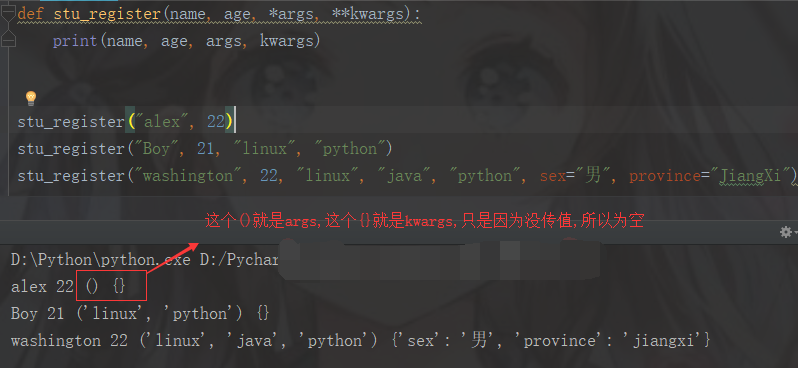
动态参数也叫非固定参数,需要传的参数个数不定,可用“args”,“kwargs”接收
1.agrs是元组的形式,接收除去键值对以外的所有参数。
2.kwargs接受的只是键值对的参数,并保存在字典中。
如果不确定要传的参数,最好使用非固定参数(万能参数)
def stu_register(name, age, *args, **kwargs): print(name, age, args, kwargs) stu_register("alex", 22) stu_register("Boy", 21, "linux", "python") stu_register("washington", 22, "linux", "java", "python", sex="男", province="JiangXi")
五、嵌套函数


name = "御姐" #外层定义的变量 def wrapper(): name = "小可爱" #外层函数定义的变量 def inner(): name = "萝莉" #内层函数定义的变量 print(name) inner() print(name) wrapper() print(name)
六、匿名函数(lambda函数)
就是不需要显示的指定函数名
func=lambda x,y:x*y if x<y else x/y #申明一个匿名函数 print(func(8, 16)) foo = lambda x, y: x**y print(foo(2, 3))
优点:1. 节省代码量
2. 看着高级
七、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n): #1 程序执行过程 v = int(n/2) #3 7 11 15 print(v) #4 8 12 16 if v > 0: #5 9 13 17 calc(v) #6 10 14 print(n) #18 19 20 21 calc(10) #2
递归特性:
1.必须有一个明确的结束条件
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
二分查找
八、内置函数
如何查看Python中全部内置变量和内置函数?
1.>>>dir(__builtins__)
2.>>>import builtins
>>>dir(builtins)

九、名称空间
1.什么是名称空间
名称到对象的映射。命名空间是一个字典的实现,键为变量名,值是变量对应的值。各个命名空间是独立的,一个命名空间中不能有重名,不同的命名空间可以重名。
2.名称空间分类
全局命名空间:global
局部命名空间:local
外部嵌套的命名空间:enclosing
内置命名空间:built-in
3.名称空间的加载顺序
内置命名空间(程序运行前加载)-->全局命名空间(程序运行中:从上到下加载)-->局部命名空间(程序运行中:调用时才加载)
4.名称空间的取值顺序:
在局部调用:局部命名空间-->全局命名空间-->内置命名空间 L->E->G->B
LEGB(local->enclosing function->global->built-in)
在全局调用:全局命名空间-->内置命名空间 G->B
十、作用域
1.什么是作用域
作用域是针对变量而言,指申明的变量在程序里的可应用范围。或者称为变量的可见性。
2.作用域分类
全局作用域:范围最大,在整个文件的任意位置都能被引用,全局有效
局部作用域:局部名称空间,只能在局部范围内生效
3.查看作用域的值
locals()和globals(),提供了基于字典的访问局部和全局变量的方式:
locals():函数会以字典类型返回当前位置的全部局部变量。
globals():函数会以字典类型返回当前位置的全部全局变量。
4.关键字(global与nonlocal)
global关键字作用:
声明一个全局变量
在局部作用域想要对全局作用域的全局变量进行调用,可用global(仅适用于字符串、数字)
对可变数据类型(list,dict,set)可以直接引用,不用通过global
a = 1 def func(): global a #声明为全局变量 a = 5 print(a) func() print(a) #结果:5 5
nonlocal作用:
不能修改一个全局变量
在局部作用域中,对外层(非全局作用域)的变量进行引用和修改,引用到了哪一层,那层以下这个变量全部发生改变
def wrapper():
foo = 19
def outer():
foo = 23
print(foo)
def inner():
nonlocal foo
foo = foo + 29
print(foo)
inner()
print(foo)
outer()
print(foo)
wrapper() #输出结果: 23 52 52 19
十一、函数的本质
1.函数可以被当成值或变量引用
1 def func():
2 return
3
4
5 print(func)
6 f = func #将其传给变量f
7 print(f)
2.函数可以被当成容器类型的元素存储
def func1(): print('func1') def func2(): print('func2') def func3(): print('func3') lists = [func1, func2, func3] lists[0]() lists[1]() lists[2]()
3.可以当做函数的参数和返回值
def func(): # 1 程序执行过程 print("func") # 5 8 def func1(args1): # 2 args1() # 4 return args1 # 6 func作为返回值 f = func1(func) # 3 func作为参数 f() # 7
十二、闭包
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包(即:内层函数,对外层函数(非全局)的变量的引用)。
def func(): name = 'alice' def inner(): print(name) return inner f = func() f()
1.检测闭包函数的公共属性:closure
如果里层的函数调用__closure__方法输出是一个cell对象,则证明是闭包。
def wrapper(): name = 'alice' def inner(): print(name) #调用外层函数的变量 inner() print(inner.__closure__) wrapper() #输出结果是: #alice #(<cell at 0x0000024057E65618: str object at 0x0000024DD8AD70A0>,)
2.带有参数的闭包函数
def wrapper(a): #a是外部传入的参数 b = 10 def inner(a): print(a + b) return a + b inner(a) wrapper(10)
十三、装饰器
本质上就是一个python函数,它可以让其他函数在不需要做任何代码变动的前提下,增加额外的功能,装饰器的返回值也是一个函数对象。
无参的装饰器
import time #1 程序执行流程
def timmer(func): #2
def wrapper(*args, **kwargs): #4
start_time = time.time() #7
res = func(*args, **kwargs) #my_max(1,2) #8
stop_time = time.time() #12
print('run time is %s' % (stop_time-start_time)) #13
return res #14
return wrapper #5
@timmer #3
def my_max(x, y):
print('my_max function') #9
res = x if x > y else y #10
return res #11
res = my_max(1, 2) #res=wrapper(1,2) #6
print('=====>', res) #15
带参数的装饰器
十四、迭代器
1.可迭代对象
可以直接作用于for循环的对象统称为可迭代对象,即Iterable。
常见迭代对象:
集合数据类型(str list tuple dict set range)
generator,包括生成器和带yield的generator function。
2.判断可迭代对象的方法
1)dir(对象)
str1 = 'hello' #字符串为可迭代对象 print('__iter__' in dir(str1)) #输出结果: True
2)isinstance()方法
使用isinstance()判断一个对象是否是Iterable对象
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
3.可迭代对象转换迭代器
可迭代对象执行obj.iter()得到的结果就是迭代器对象。
而迭代器对象指的是即内置有__iter__又内置有__next__方法的对象。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
4.迭代器的优缺点
优点:提供一种统一的、不依赖于索引的迭代方式;惰性计算、节省内存
缺点:无法获取长度(只有在next完毕才知道有几个值);一次性的,只能往后走,不能往前退
十五、生成器
把列表解析的[]换成()得到的就是生成器表达式
>>> L = [x*x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g =(x*x for x in range(10))
>>> g
<generator object <genexpr> at 0x0000028604E21048>
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
>>> next(g)
36
>>> next(g)
49
>>> next(g)
64
>>> next(g)
81
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
每次调用next()函数获得generator的下一个返回值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
可用for循环迭代,不需要每次调用next(),同时也不会出现StopIteration的错误。
1 g = (x * x for x in range(10)) 2 for n in g: 3 print(n)
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ...
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
#a, b = b, a + b相当于 t = (b, a + b) # t是一个tuple
#a = t[0]
#b = t[1]
输出结果:
>>> fib(6)
1
1
2
3
5
8
'done'
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
def fib(max1):
n, a, b = 0, 0, 1
while n < max1:
yield b
a,b = b, a + b
n = n + 1
return 'done'
for n in fib(6):
print(n)
generator和函数的执行流程不一样!函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代。
用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
1 g = fib(6)
2 while True:
3 try:
4 x = next(g)
5 print('g:', x)
6 except StopIteration as e:
7 print('Generator return value:', e.value)
8 break
输出结果:
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存。