需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar)
链接:https://pan.baidu.com/s/1VlylWmlhjd8Ka8VTruQEnA 提取码:dxeq
爬取的原网站为:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
Paqu.java
package control; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Date; import java.util.List; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.gargoylesoftware.htmlunit.BrowserVersion; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.HtmlInput; import com.gargoylesoftware.htmlunit.html.HtmlPage; import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput; import Dao.AddService; public class Paqu { public static void main(String args[]) { // TODO Auto-generated method stub String sheng=""; String xinzeng=""; String leiji=""; String zhiyu=""; String siwang=""; String url = "https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1"; int i=0; try { //构造一个webClient 模拟Chrome 浏览器 WebClient webClient = new WebClient(BrowserVersion.CHROME); //支持JavaScript webClient.getOptions().setJavaScriptEnabled(true); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setActiveXNative(false); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setThrowExceptionOnScriptError(false); webClient.getOptions().setThrowExceptionOnFailingStatusCode(false); webClient.getOptions().setTimeout(8000); HtmlPage rootPage = webClient.getPage(url); //设置一个运行JavaScript的时间 webClient.waitForBackgroundJavaScript(6000); String html = rootPage.asXml(); Document doc = Jsoup.parse(html); //System.out.println(doc); Element listdiv1 = doc.select(".wrap").first(); Elements listdiv2 = listdiv1.select(".province"); for(Element s:listdiv2) { Elements span = s.getElementsByTag("span"); Elements real_name=span.select(".item_name"); Elements real_newconfirm=span.select(".item_newconfirm"); Elements real_confirm=span.select(".item_confirm"); Elements real_dead=span.select(".item_dead"); Elements real_heal=span.select(".item_heal"); sheng=real_name.text(); xinzeng=real_newconfirm.text(); leiji=real_confirm.text(); zhiyu=real_heal.text(); siwang=real_dead.text(); //System.out.println(sheng+" 新增确诊:"+xinzeng+" 累计确诊:"+leiji+" 累计治愈:"+zhiyu+" 累计死亡:"+siwang); Date currentTime=new Date(); SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm"); String time = formatter.format(currentTime);//获取当前时间 AddService dao=new AddService(); dao.add("myinfo", sheng, xinzeng, leiji, zhiyu, siwang,time);//将爬取到的数据添加至数据库 } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); System.out.println("爬取失败"); } } }
AddService.java:
package Dao; import java.sql.Connection; import java.sql.Statement; import utils.DBUtils; public class AddService { public void add(String table,String sheng,String xinzeng,String leiji,String zhiyu,String dead,String time) { String sql = "insert into "+table+" (Province,Newconfirmed_num ,Confirmed_num,Cured_num,Dead_num,Time) values('" + sheng + "','" + xinzeng +"','" + leiji +"','" + zhiyu + "','" + dead+ "','" + time+ "')"; System.out.println(sql); Connection conn = DBUtils.getConn(); Statement state = null; int a = 0; try { state = conn.createStatement(); a=state.executeUpdate(sql); } catch (Exception e) { e.printStackTrace(); } finally { DBUtils.close(state, conn); } } }
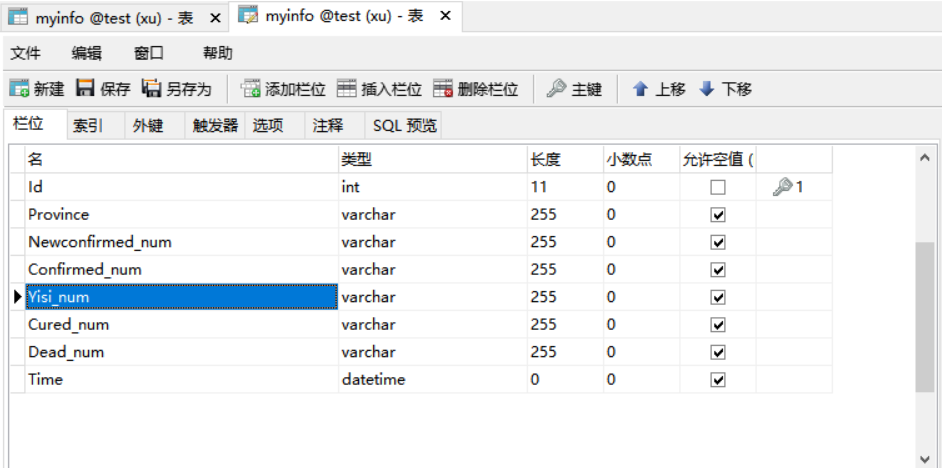
数据库建表如下:
遇到的问题
一开始的数据是动态加载的,无法获取确定的数据,最后在代码中添加了一段js内容来获取动态数据。
其中还尝试过爬取其他的网站上的数据,但doc并不能很好的输出,只能输出网站的大框架,无法获取具体到内容。