文章正文
对于分布式系统来说,网络是最基本的一环,其设计的好坏直接影响到整个分布式系统的稳定性及可用性。为此,Spark专门独立出基础网络模块spark-network,为上层RPC、Shuffle数据传输、RDD Block同步以及资源文件传输等提供可靠的网络服务。在spark-1.6以前,RPC是单独通过akka实现,数据以及文件传输是通过netty实现,然而akka实质上底层也是采用netty实现,对于一个优雅的工程师来说,不会在系统中同时使用具有重复功能的框架,否则会使得系统越来越重,所以自spark-1.6开始,通过netty封装了一套简洁的类似于akka actor模式的RPC接口,逐步抛弃akka这个大框架。从spark-2.0起,所有的网络功能都是通过netty来实现。
1、系统抽象
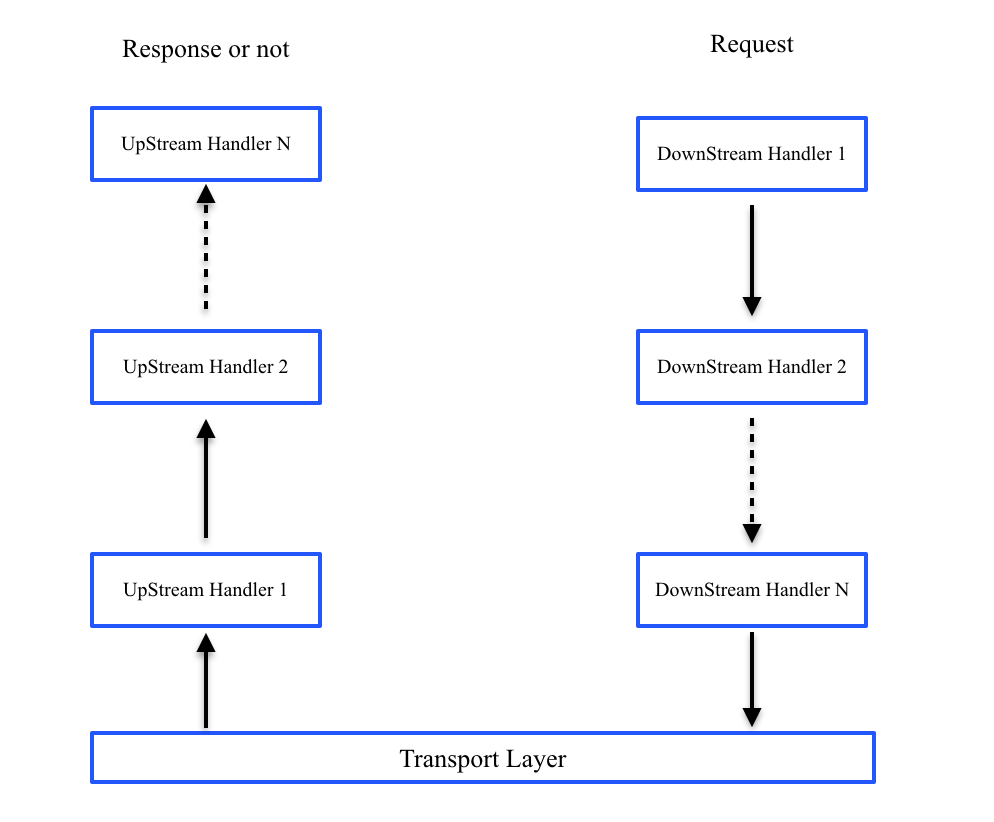
在介绍spark网络模块前,我们先温习下netty的基本工作流程。无论是服务器还是客户端都会关联一个channel(socket),channel上会绑定一个pipeline,pipeline绑定若干个handler,用来专门用来处理和业务有关的东西,handler有DownHandler和UpHandler两种,DownHandler用来处理发包,UpHandler用来处理收包,大致过程如下图所示。
Spark的底层网络实现也是遵循上图所示流程,其总体实现流程如下图所示。客户端发送请求消息,经过Encoder(一种DownHandler)编码,加上包头信息,再通过网络发给服务端,服务端收到消息后,首先经过TransportFrameDecoder(一种UpHandler)处理粘包拆包,得到消息类型和消息体,然后经过Decoder解析消息类型,得到一个个具体的请求消息,最后由TransportChannelHandler处理具体的请求消息,并根据具体的消息类型判断是否返回一个响应。类似地,响应消息传给客户端也是先经过Encoder编码,客户端先通过TransportFrameDecoder、Decoder解包消息,再通过TransportChannelHandler处理具体的响应消息。
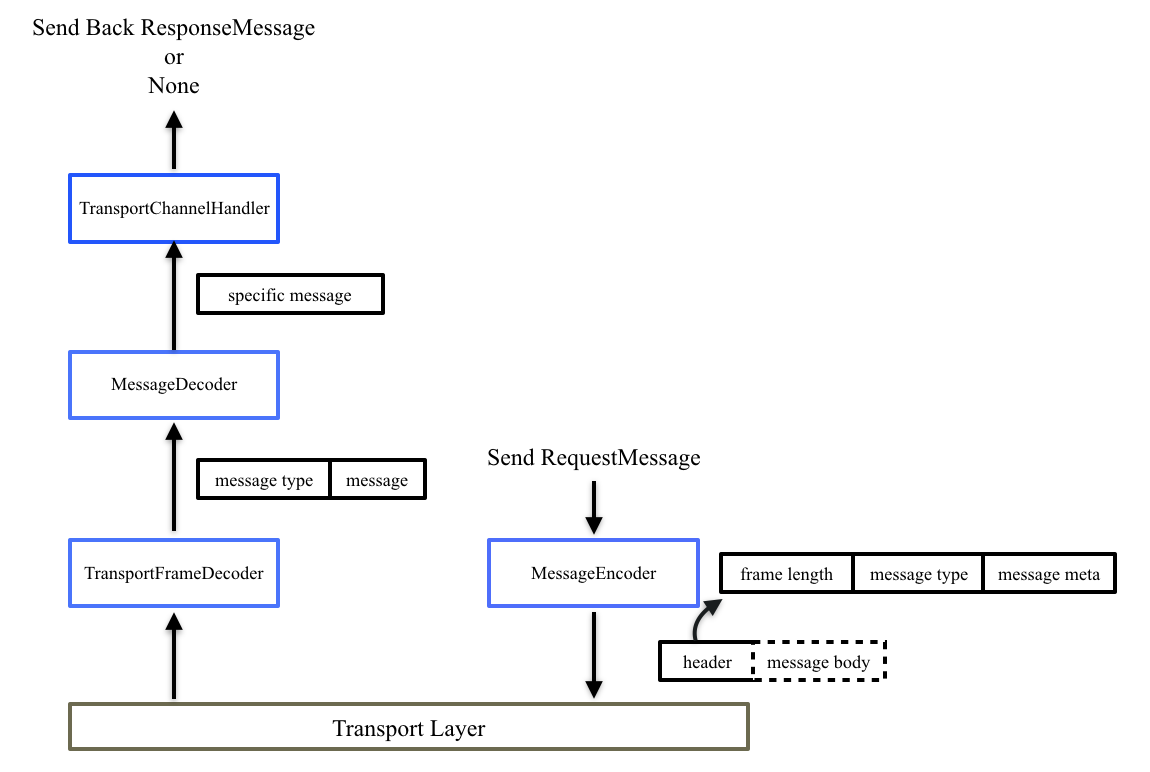
整个网络模型非常清晰简单,最核心的当属消息抽象以及如何定义消息传输和处理,即上图中的Message的定义以及编解码传输等,下面详细介绍spark网络模块的消息抽象以及相关handler的定义。
2、消息抽象
总结起来,Spark中定义三种类型的消息:RPC消息、ChunkFetch消息以及Stream消息。Message是这些消息的抽象接口,它定义了三个关键接口,分别得到消息类型、消息体以及判断消息体是否编码在header中,消息体统一由ManagedBuffer表示,ManagedBuffer抽象了JAVA NIO ByteBuffer、Netty ByteBuf以及File Segment,所以无论是ByteBuffer、ByteBuf还是File Segment,都可以表示为ManagedBuffer。如下图列出所有spark中涉及到的具体消息,下面分别详细阐述各种消息。

RPC消息用于抽象所有spark中涉及到RPC操作时需要传输的消息,通常这类消息很小,一般都是些控制类消息,在spark-1.6以前,RPC都是通过akka来实现的,自spark-1.6开始逐渐把akka剔除,通过netty实现,所以在spark-network公共模块中定义该类消息,其包括RpcRequest、OneWayMessage、RpcResponse以及RpcFailure四种消息。RpcRequest封装RPC请求消息,这类RPC请求是需要得到一个RPC响应的,RpcRequest除了消息体外,还包括一个requestId字段,用于唯一标识一个RPC请求,与RpcRequest对应地,有两种RPC响应消息,RpcResponse是RPC调用正常返回的响应消息,RpcFailure是RPC调用异常返回的响应消息,同样地,它们除了消息体外也包括requestId字段,该字段用于对应RpcRequest。OneWayMessage作为另一种RPC请求消息,但是这类RPC请求是不需要响应的,所以它只包含消息体,不需要诸如requestId等字段来唯一标识,该消息被发送后可不用管它。
ChunkFetch消息用于抽象所有spark中涉及到数据拉取操作时需要传输的消息,它用于shuffle数据以及RDD Block数据传输。在shuffle阶段,reduce task会去拉取map task结果中的对应partition数据,这需要发起一个ChunkFetch;另外,当RDD被缓存后,如果节点上没有所需的RDD Block,则会发起一个ChunkFetch拉取其他节点上的RDD Block。ChunkFetch消息包括ChunkFetchRequest、ChunkFetchSuccess以及ChunkFetchFailure三种消息。ChunkFetchRequest封装ChunkFetch请求消息,其只包括StreamChunkId字段,没有消息体,StreamChunkId包括streamId和chunkIndex两个字段,streamId标识这次chunk fetch,chunkIndex标识fetch的数据块,通常一次fetch可能会fetch多个chunk。ChunkFetchSuccess是成功Fetch后的响应消息,ChunkFetchFailure是Fetch失败的响应消息,它们包含了Fetch的消息体外,还包括StreamChunkId,以对应ChunkFetchRequest。
Stream消息很简单,主要用于driver到executor传输jar、file文件等。Stream消息包括StreamRequest、StreamResponse以及StreamFailure三种消息,其中StreamRequest表示Stream请求消息,只包含一个streamId,标识这个请求。StreamResponse表示Stream成功响应消息,包含streamId以及响应的字节数,并后面跟数据内容,实际使用时,客户端会根据响应中的字节数进一步获取实际内容。StreamFailure表示Stream失败的响应消息,包含streamId以及异常信息。executor需要获取相关jar包或file文件时,会发起一个StreamRequest消息给driver,driver会返回一个StreamResponse,executor根据响应中的字节数来进一步去截获后续数据内容。
3、Handler定义
一个message从被发送到被接收需要经过”MessageEncoder->网络->TransportFrameDecoder->MessageDecoder”,下面按照这一过程详细阐述各handler的作用。
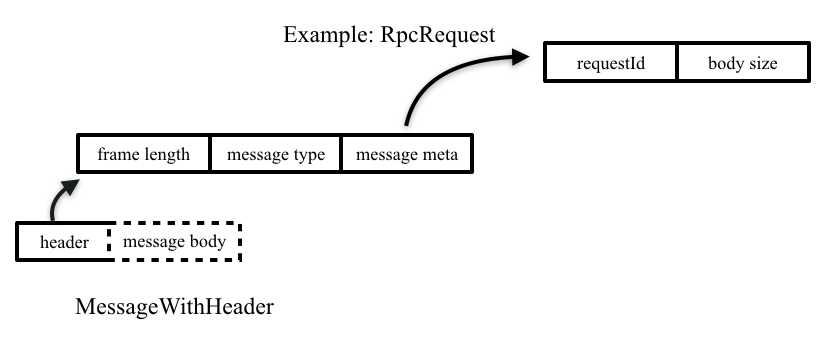
一个message进入网络前,需要经过MessageEncoder编码,加上包头信息,以便后续收包时正确粘包拆包。头信息主要是包括三部分:
- 整个包的长度
- 消息类型
- 除消息体外的消息元数据,例如RpcRequest消息的元数据信息包括requestId和消息长度bodysize
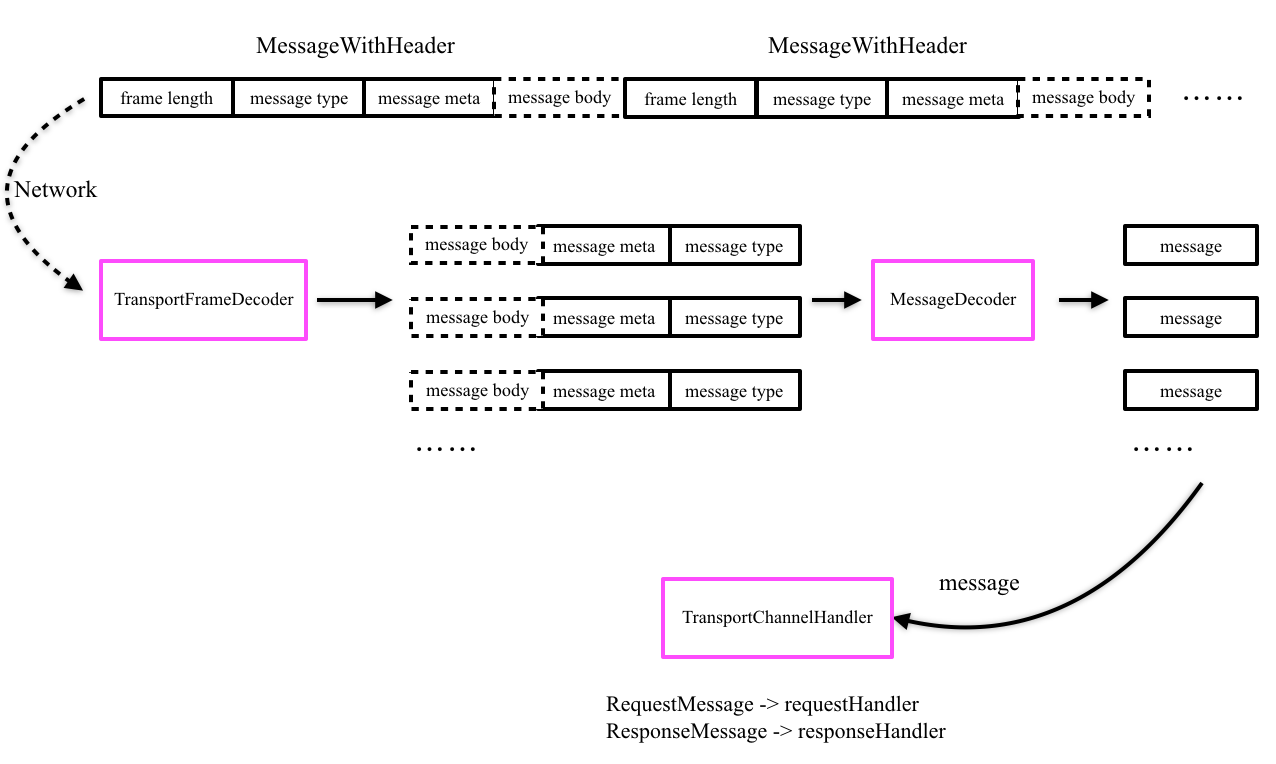
经过上述编码后,一个个Message被编码成一个个MessageWithHeader发送到网络中,接收端收到数据后,首先通过TransportFrameDecoder和MessageDecoder来解码出一个个具体的Message,这里就涉及到粘包拆包问题,这也是为什么在编码阶段在头部加上frame length的原因。TransportFrameDecoder在解码过程中,首先读取8字节的frame length(Long型),用frame length减去8就是除frame length外其他部分的长度,即为message type、message meta、message body三部分的长度,循环读取直到这个长度,把读到的Bytebuf交给MessagerDecoder,MessagerDecoder首先解析出message type,根据message type去反序列化(实例化)出具体的Message,例如message type如果是RpcRequest,那么则继续解析requestId和body size,根据body size解析后续字节得到body,并构造出RpcRequest对象。反序列化得到的message对象会交给TransportChannelHandler,TransportChannelHandler里封装了TransportRequestHandler和TransportResponseHandler,分别处理RequestMessage和ResponseMessage,在服务端,TransportChannelHandler一般处理RequestMessage,在客户端,TransportChannelHandler一般处理ResponseMessage。
4、系统消息流程
根据上述系统抽象可以看出,spark-network将RPC、ChunkFetch以及Stream统一抽象出来,其中任意一种功能都依赖于spark-network的实现,下面分别详细阐述这三种功能的一般使用流程。
4.1 RPC消息处理
客户端发送一个RPC请求消息(RpcRequest或OneWayMessage),经过编码到网络,解码到服务端的TransportChannelHandler,RPC请求会被交给TransportRequestHandler处理,而TransportRequestHandler中包括了一个RpcHandler专门用来处理RPC请求消息,RpcHandler中有两个关键receive接口,带callback和不带callback参数分别处理RpcRequest和OneWayMessage。
public abstract class RpcHandler {
public abstract void receive(
TransportClient client,
ByteBuffer message,
RpcResponseCallback callback);
public void receive(TransportClient client, ByteBuffer message) {
receive(client, message, ONE_WAY_CALLBACK);
}
...
}
当收到RpcRequest时,处理后会在callback中发送响应消息,成功则发送RpcResponse,失败则发送RpcFailure。当收到OneWayMessage时,处理后则直接不用管,客户端也不用关心是否被处理了。
类似地,服务端发送RPC响应消息(RpcResponse或RpcFailure),也经过编码到网络,解码到客户端的TransportChannelHandler,RPC响应会被交给TransportResponseHandler处理,在客户端发送RpcRequest的时候,会注册一个RpcResponseCallback,通过requestId来标识,这样在收到响应消息的时候,根据响应消息中的requestId就可以取出对应的RpcResponseCallback对响应消息进行处理。
4.2 ChunkFetch消息处理
对于ChunkFetch请求,客户端一般需要首先发送一个RPC请求,告诉服务端需要拉取哪些数据,服务端收到这个RPC请求后,会为客户端准备好需要的数据。上一节也提到,RPC请求会通过RpcHandler来处理,当RpcHandler接收到ChunkFetch的RPC请求消息时,则会为客户端准备好它需要的数据,这些即将要被fetch的数据是通过一个StreamManager来管理的,所以RpcHandler中有一个接口专门获取StreamManager,StreamManager为后续到来的ChunkFetchRequest服务。
public abstract class RpcHandler {
...
public abstract StreamManager getStreamManager();
...
}
RPC请求成功后,服务端表示数据准备好,客户端发送ChunkFetchRequest消息,服务端收到该消息后,最后会交给TransportRequestHandler处理,TransportRequestHandler则根据请求消息中的StreamChunkId,从前面准备好的StreamManager中拿到对应的数据,封装成ChunkFetchSuccess返回给客户端,如果出错或找不到对应的数据,则返回ChunkFetchFailure。
public abstract class StreamManager {
...
public abstract ManagedBuffer getChunk(long streamId, int chunkIndex);
...
}
响应消息到达客户端后,最后会被交给TransportResponseHandler处理,在客户端发送ChunkFetchRequest的时候,会注册一个ChunkReceivedCallback,通过StreamChunkId来标识,这样在收到响应消息的时候,根据响应消息中的StreamChunkId就可以取出对应的ChunkReceivedCallback对响应消息进行处理。
4.3 Stream消息处理
Stream类似于ChunkFetch,主要用于文件服务。客户端一般也需要首先发送一个RPC请求,告诉服务端需要打开一个stream,服务端收到这个RPC请求后,会为客户端打开所需的文件流。
RPC请求成功后,服务端表示数据准备好,客户端发送StreamRequest消息,服务端收到该消息后,最后会交给TransportRequestHandler处理,TransportRequestHandler则根据请求消息中的streamId,从准备好的StreamManager中打开对应的文件流,同时返回StreamResponse给客户端,如果出错或找不到对应的流,则返回ChunkFetchFailure。
public abstract class StreamManager {
...
public ManagedBuffer openStream(String streamId);
...
}
响应消息到达客户端后,最后会被交给TransportResponseHandler处理,在客户端发送StreamRequest的时候,会注册一个StreamCallback,同时维护一个StreamCallback的队列,这样在收到响应消息的时候,就会从队列中取出StreamCallback去处理截获的数据。注意这里说的是截获的数据,这块有点不一样的是,收到响应消息后,会根据响应消息中数据大小,在TransportFrameDecoder对象中设置截获器Interceptor对象,TransportFrameDecoder在接收数据的时候会被这个截获器Interceptor截取它想要的数据。虽然代码看懂了,但是这里却不知道为啥通过截获的方式去拉取文件流数据。
5、小结
本文主要阐述spark-network公共模块,详细分析spark底层网络编解码以及消息处理的抽象,在后续文章中会更加详细地介绍具体spark中的RPC、ShuffleService、BlockTransformService以及FileServer的实现,这些功能服务都是基于spark-network公共模块来实现的。
文章来源
http://sharkdtu.com/posts/spark-network.html